python+pytest接口自动化(4)-requests发送get请求
python中用于请求http接口的有自带的urllib和第三方库requests,但 urllib 写法稍微有点繁琐,所以在进行接口自动化测试过程中,一般使用更为简洁且功能强大的 requests 库。下面我们使用 requests 库发送get请求。
requests库
简介
requests 库中提供对用的方法用于常用的HTTP请求,对应如下:
requests.get() # 用于GET请求
requests.post() # 用于POST请求
requests.put() # 用于PUT请求
requests.delete() # 用于DELETE请求
当然还有更多的方法,这里只列举常用的。
安装
安装命令:pip install requests
发送get请求
get请求参数格式说明
requests 中的 get 方法源码如下:
def get(url, params=None, **kwargs):
r"""Sends a GET request.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary, list of tuples or bytes to send
in the query string for the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
kwargs.setdefault('allow_redirects', True)
return request('get', url, params=params, **kwargs)
参数说明:
- url,即接口地址
- params,接口参数,可选(即可填可不填)
- **kwargs,可以添加其他请求参数,如设置请求头headers、超时时间timeout、cookies等
不带参数请求
import requests
res = requests.get(url="https://www.cnblogs.com/lfr0123/")
# 请求得到的res是一个Response对象,如果想要看到返回的文本内容,需要使用.text
print(res.text)
带参数请求
import requests
url = "http://www.baidu.com/s"
params = {"wd": "给你一页白纸-博客园", "ie": "utf-8"}
res = requests.get(url=url, params=params)
print(res.text)
加入请求头headers
有些接口限制只能被浏览器访问,这时按照上面的代码去请求就会被禁止,我们可以在代码中加入 headers 参数伪装成浏览器进行接口请求,示例如下:
import requests
url = "http://www.baidu.com/s"
params = {"wd": "给你一页白纸-博客园", "ie": "utf-8"}
# User-Agent的值为浏览器类型
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36"
}
res = requests.get(url=url, params=params, headers=headers)
print(res.text)
部分结果如下:
这里的响应体其实就是在百度中搜索给你一页白纸-博客园的结果页面。
除此之外,还可以加入timeout、cookies等,写法如下:
# timeout只限制请求的超时时间,单位为s,若超时则报错
res = requests.get(url=url, params=params, headers=headers, timeout=20, cookies=cookies)
响应内容
发送请求后会获取到接口响应的内容,如上面示例中res.text,其他响应内容获取方式如下:
res.status_code # 响应状态码
res.headers # 响应头
res.encoding # 响应体编码格式
res.text # 响应体,字符串形式的文本信息
res.content # 响应体,二进制形式的文本信息,会自动解码
res.cookies # 响应的cookie
res.json() # 响应体格式为json,则需要通过json()进行解码
这里需要注意,res.text与res.content的使用,具体使用哪种方式获取响应体内容,需要根据编码方式进行选择,最笨的方法就是一种不行换另一种试试。
示例如下:
import requests
url = "http://www.baidu.com/s"
params = {"wd": "给你一页白纸-博客园", "ie": "utf-8"}
# User-Agent的值为浏览器类型
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36"
}
res = requests.get(url=url, params=params, headers=headers)
print(res.text)
print(res.status_code)
print(res.headers)
print(res.encoding)
print(res.cookies)
结果如下:
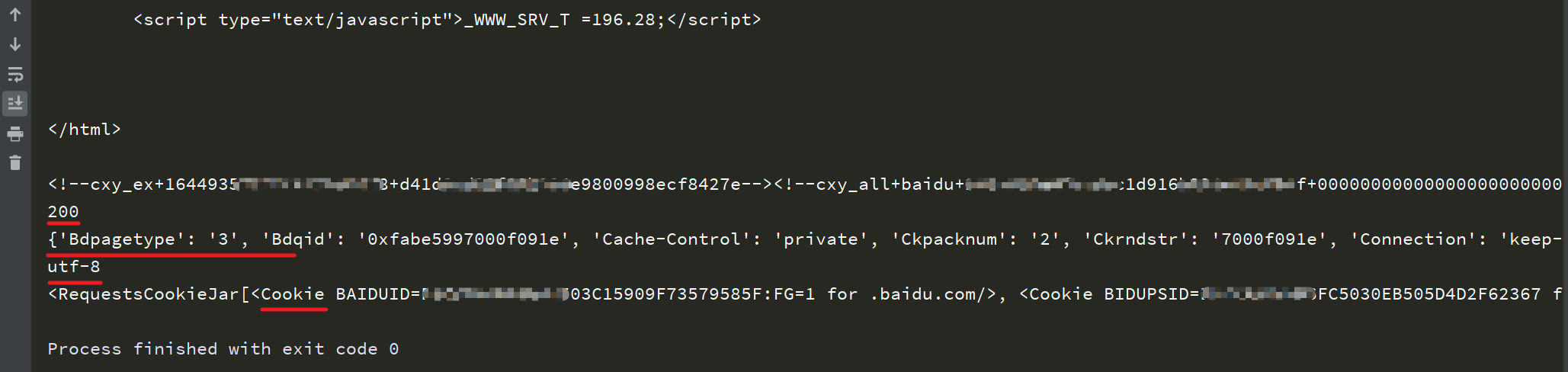
结果中由上而下依次对应代码中print的响应内容。
python+pytest接口自动化(4)-requests发送get请求的更多相关文章
- python+pytest接口自动化(11)-测试函数、测试类/测试方法的封装
前言 在python+pytest 接口自动化系列中,我们之前的文章基本都没有将代码进行封装,但实际编写自动化测试脚本中,我们都需要将测试代码进行封装,才能被测试框架识别执行. 例如单个接口的请求代码 ...
- python+pytest接口自动化(5)-发送post请求
简介 在HTTP协议中,与get请求把请求参数直接放在url中不同,post请求的请求数据需通过消息主体(request body)中传递. 且协议中并没有规定post请求的请求数据必须使用什么样的编 ...
- python+pytest接口自动化(13)-token关联登录
在PC端登录公司的后台管理系统或在手机上登录某个APP时,经常会发现登录成功后,返回参数中会包含token,它的值为一段较长的字符串,而后续去请求的请求头中都需要带上这个token作为参数,否则就提示 ...
- python WEB接口自动化测试之requests库详解
由于web接口自动化测试需要用到python的第三方库--requests库,运用requests库可以模拟发送http请求,再结合unittest测试框架,就能完成web接口自动化测试. 所以笔者今 ...
- python+pytest接口自动化(6)-请求参数格式的确定
我们在做接口测试之前,先需要根据接口文档或抓包接口数据,搞清楚被测接口的详细内容,其中就包含请求参数的编码格式,从而使用对应的参数格式发送请求.例如某个接口规定的请求主体的编码方式为 applicat ...
- python+pytest接口自动化(9)-cookie绕过登录(保持登录状态)
在编写接口自动化测试用例或其他脚本的过程中,经常会遇到需要绕过用户名/密码或验证码登录,去请求接口的情况,一是因为有时验证码会比较复杂,比如有些图形验证码,难以通过接口的方式去处理:再者,每次请求接口 ...
- python+pytest接口自动化(12)-自动化用例编写思路 (使用pytest编写一个测试脚本)
经过之前的学习铺垫,我们尝试着利用pytest框架编写一条接口自动化测试用例,来厘清接口自动化用例编写的思路. 我们在百度搜索天气查询,会出现如下图所示结果: 接下来,我们以该天气查询接口为例,编写接 ...
- python+pytest接口自动化(16)-接口自动化项目中日志的使用 (使用loguru模块)
通过上篇文章日志管理模块loguru简介,我们已经知道了loguru日志记录模块的简单使用.在自动化测试项目中,一般都需要通过记录日志的方式来确定项目运行的状态及结果,以方便定位问题. 这篇文章我们使 ...
- python+pytest接口自动化(10)-session会话保持
在接口测试的过程中,经常会遇到有些接口需要在登录的状态下才能请求,否则会提示请登录,那么怎样解决呢? 上一篇文章我们介绍了Cookie绕过登录,其实这就是保持登录状态的方法之一. 另外一种方式则是通过 ...
随机推荐
- 阅读笔记——长文本匹配《Matching Article Pairs with Graphical Decomposition and Convolutions》
论文题目:Matching Article Pairs with Graphical Decomposition and Convolutions 发表情况:ACL2019 腾讯PCG小组 模型简介 ...
- ARC-124 部分题解
E 直接统计原式不好做,注意到首先我们应该知道怎样的 \(x\) 序列是合法的,那么不妨首先来统计一下合法的 \(x\) 序列数量. 令 \(b_i\) 为 \(i\) 向右给的球数,那么有(\(i ...
- IDEA使用MybatisCodeHelperPro插件
下载MybatisCodeHelperPro: 链接:https://pan.baidu.com/s/1H6csq9STVh0Ofldh6V6gxQ提取码:r2g3 IDEA安装本地插件: ctrl+ ...
- redis清缓存
先查询当前redis的服务是否已经启动 ps -ef|grep redis [root@guanbin-k8s-master ~]# ps -ef|grep redis redis 1557 1 0 ...
- 入门-k8s集群环境搭建(二)
对于 Kubernetes 初学者,在搭建K8S集群时,推荐在阿里云或腾讯云采购如下配置:(您也可以使用自己的虚拟机.私有云等您最容易获得的 Linux 环境) 至少2台 2核4G 的服务器 Cent ...
- SpringMVC主要组件
1.DispatcherServlet:前端控制器,接收所有请求(如果配置/,则不包含jsp) 2.handlermapping:判断请求格式,判断希望具体要执行的那个方法 3.HanderAdapt ...
- 【struts2】中method={1}详解
我们在使用struts2的时候,有时候为了简化struts2的配置项而采用通配符的方式,如下代码: <action name="ajaxregister!*" class=& ...
- 洛谷P1098 [NOIP2007 提高组] 字符串的展开
题目链接:https://www.luogu.com.cn/problem/P1098 这个题出的真的很有质量,这个是我见过算是复杂的模拟题了,对付这种题,一丝都不能马虎,要想实现快捷而又简便的代码设 ...
- Codeforces Round #756 (Div. 3)
本场战绩:+451 题目如下: A. Make Even time limit per test 1 second memory limit per test 256 megabytes input ...
- Solution -「洛谷 P6577」「模板」二分图最大权完美匹配
\(\mathcal{Description}\) Link. 给定二分图 \(G=(V=X\cup Y,E)\),\(|X|=|Y|=n\),边 \((u,v)\in E\) 有权 \(w( ...