微调BERT:序列级和令牌级应用程序
微调BERT:序列级和令牌级应用程序
Fine-Tuning BERT for Sequence-Level and Token-Level Applications
为自然语言处理应用程序设计了不同的模型,例如基于RNNs、CNNs、attention和MLPs。当存在空间或时间限制时,这些模型是有用的,然而,为每个自然语言处理任务构建一个特定的模型实际上是不可行的。介绍了一个预训练模型,BERT,要求对各种自然语言处理任务进行最小的体系结构更改。一方面,在提出这个建议的时候,BERT改进了各种自然语言处理任务的现状。另一方面,如14.10节所述,原始BERT模型的两个版本都有1.1亿和3.4亿个参数。因此,当有足够的计算资源时,可以考虑为下游自然语言处理应用程序微调BERT。
现在,将自然语言处理应用程序的子集概括为序列级和令牌级。在序列层次上,介绍了在单文本分类和文本对分类或回归中如何将文本输入的BERT表示转换为输出标签。在令牌级别,将简要介绍新的应用程序,如文本标记和问答,并阐明BERT如何表示其输入并转换为输出标签。在“微调”过程中,不同的应用程序需要“完全连接”不同的层。在下游应用程序的监督学习过程中,外层的参数从零开始学习,同时对预训练的BERT模型中的所有参数进行微调。
1. Single Text Classification
单一文本分类以单个文本序列为输入,输出分类结果。除了在本章中研究的情感分析之外,语言可接受性语料库(CoLA)也是一个用于单个文本分类的数据集,用于判断给定句子在语法上是否可接受[Warstadt等人,2019]。例如,“应该学习”是可以接受的,但是“应该学习”则不是。
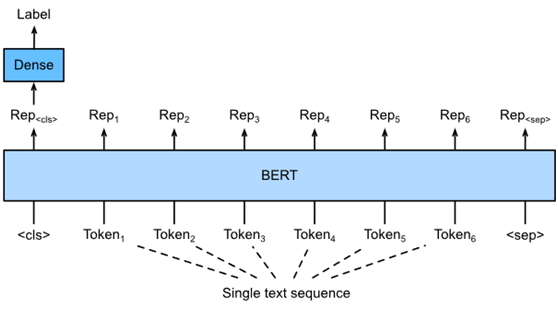
图1针对单个文本分类应用(如情感分析和测试语言可接受性)的微调BERT。假设输入的单个文本有六个标记。
描述了BERT的输入表示。BERT输入序列明确表示单个文本和文本对,其中特殊分类标记“<cls>”用于序列分类,特殊分类标记“<sep>”标记单个文本的结尾或分隔一对文本。如图1所示,在单个文本分类应用中,特殊分类标记“<cls>”的BERT表示对整个输入文本序列的信息进行编码。作为输入单个文本的表示,将被输入一个由完全连接(密集)层组成的小MLP,以输出所有离散标签值的分布。
2. Text Pair Classification or Regression
研究了自然语言推理。属于文本对分类,是一种对文本进行分类的应用程序。 以一对文本作为输入,输出一个连续值,语义文本相似度是一个流行的文本对回归任务。这个任务测量句子的语义相似性。例如,在语义-文本相似度基准数据集中,一对句子的相似度得分是一个从0(无意义重叠)到5(意义对等)的有序量表[Cer等人,2017]。目标是预测这些分数。语义-文本相似度基准数据集的示例包括(第1句、第2句、相似度得分):
· “A plane is taking off.”, “An air plane is taking off.”, 5.000;
· “A woman is eating something.”, “A woman is eating meat.”, 3.000;
· “A woman is dancing.”, “A man is talking.”, 0.000.
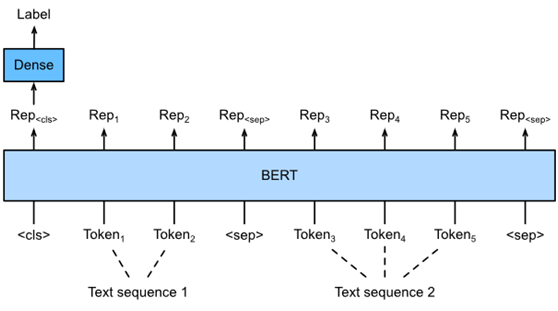
Fig. 2. Fine-tuning BERT for text pair classification or regression applications, such as natural language inference and semantic textual similarity. Suppose that the input text pair has two and three tokens.
与图1中的单个文本分类相比,图2中文本对分类的微调BERT在输入表示上有所不同。对于文本对回归任务(如语义文本相似性),可以应用一些微小的更改,例如输出连续的标签值和使用均方损失:在回归中很常见。
3. Text Tagging
现在让考虑令牌级别的任务,例如文本标记,其中每个令牌都分配了一个标签。在文本标注任务中,词性标注根据词在句子中的作用为每个词分配一个词性标记(如形容词和限定词)。例如,根据Penn Treebank II标记集,句子“John Smith的汽车是新的”应该标记为“NNP(名词,固有单数)NNP POS(所有格结尾)NN(名词,单数或质量)VB(动词,基本形式)JJ(形容词)”。
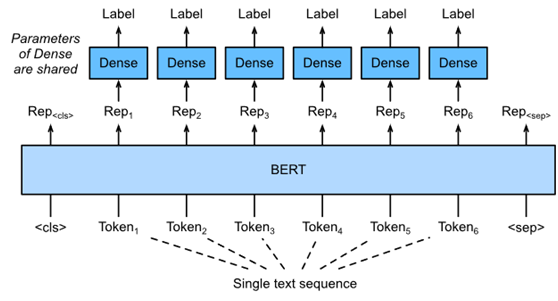
Fig. 3. Fine-tuning BERT for text tagging applications, such as part-of-speech tagging. Suppose that the input single text has six tokens.
图3说明了文本标记应用程序的微调BERT。与图1相比,唯一的区别在于在文本标记中,输入文本的每个标记的BERT表示被输入到相同的额外完全连接的层中,以输出标记的标签,例如词性标签。
4. Question Answering
问答作为另一个符号级应用,反映了阅读理解的能力。例如,斯坦福问答数据集(SQuAD v1.1)由阅读段落和问题组成,每个问题的答案只是问题所在段落中的一段文本(文本跨度)[Rajpurkar等人,2016年]。为了解释这一点,可以考虑这样一段话:“一些专家报告说,口罩的功效是不确定的。然而,口罩制造商坚持产品,如N95口罩,可以抵御病毒?”. 答案应该是文中的“口罩制造者”。因此,SQuAD v1.1的目标是在给定一对问题和一段文章的情况下,预测文章的开始和结束
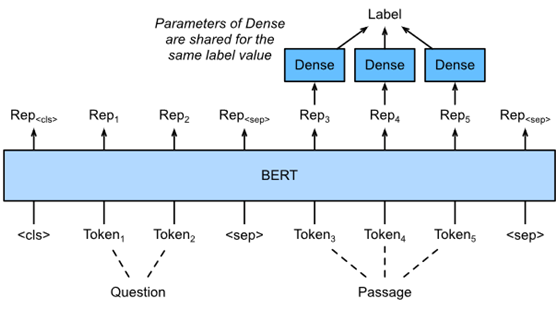
Fig. 4. Fine-tuning BERT for question answering. Suppose that the input text pair has two and three tokens.
为了对BERT进行微调,在BERT的输入中,将问题和段落分别打包为第一和第二文本序列。为了预测文本跨距开始的位置,相同的附加全连接层将从位置通道转换任何令牌的BERT表示i变成标量分数si。所有通行令牌的这种分数通过softmax操作进一步转换成概率分布,使得每个令牌位置i有一个概率pi。作为文本跨度的开始。预测文本跨距的结束与上述相同,只是其附加的完全连接层中的参数与用于预测开始的参数无关。在预测终点时,任何位置的通行标志i由相同的完全连通层转换为标量分数ei。
eiei. :numref:fig_bert-qa描述了用于问答的微调BERT。
对于问题回答,监督学习的训练目标与最大化地面真相起始和结束位置的对数可能性一样简单。在预测跨度时,可以计算得分si+ej,从位置开始有效跨距i到位置j(i≤j),输出得分最高的跨度。
5. Summary
· BERT requires minimal architecture changes (extra fully-connected layers) for sequence-level and token-level natural language processing applications, such as single text classification (e.g., sentiment analysis and testing linguistic acceptability), text pair classification or regression (e.g., natural language inference and semantic textual similarity), text tagging (e.g., part-of-speech tagging), and question answering.
· During supervised learning of a downstream application, parameters of the extra layers are learned from scratch while all the parameters in the pretrained BERT model are fine-tuned.
微调BERT:序列级和令牌级应用程序的更多相关文章
- 自然语言推理:微调BERT
自然语言推理:微调BERT Natural Language Inference: Fine-Tuning BERT SNLI数据集上的自然语言推理任务设计了一个基于注意力的体系结构.现在通过微调BE ...
- 51nod图论题解(4级,5级算法题)
51nod图论题解(4级,5级算法题) 1805 小树 基准时间限制:1.5 秒 空间限制:131072 KB 分值: 80 难度:5级算法题 她发现她的树的点上都有一个标号(从1到n),这些树都在空 ...
- Netty 100万级到亿级流量 高并发 仿微信 IM后台 开源项目实战
目录 写在前面 亿级流量IM的应用场景 十万级 单体IM 系统 高并发分布式IM系统架构 疯狂创客圈 Java 分布式聊天室[ 亿级流量]实战系列之 -10[ 博客园 总入口 ] 写在前面 大家好 ...
- HTML块级、行级元素,特殊字符,嵌套规则
如果介绍HTML网页基本标签的嵌套规则,首先要说的就是元素的分类.元素可以划分为块级元素和行级元素,块级元素是什么?它可以独占一行,可以设置宽高度,默认是100%:行级元素与之相反,它的内容决定它的宽 ...
- 操作系统学习笔记5 | 用户级线程 && 内核级线程
在上一部分中,我们了解到操作系统实现多进程图像需要组织.切换.考虑进程之间的影响,组织就是用PCB的队列实现,用到了一些简单的数据结构知识.而本部分重点就是进程之间的切换. 参考资料: 课程:哈工大操 ...
- [数据库事务与锁]详解五: MySQL中的行级锁,表级锁,页级锁
注明: 本文转载自http://www.hollischuang.com/archives/914 在计算机科学中,锁是在执行多线程时用于强行限制资源访问的同步机制,即用于在并发控制中保证对互斥要求的 ...
- MySQL行级锁,表级锁,页级锁详解
页级:引擎 BDB. 表级:引擎 MyISAM , 理解为锁住整个表,可以同时读,写不行 行级:引擎 INNODB , 单独的一行记录加锁 表级,直接锁定整张表,在你锁定期间,其它进程无法对该表进行写 ...
- 行为级和RTL级的区别(转)
转自:http://hi.baidu.com/renmeman/item/5bd83496e3fc816bf14215db RTL级,registertransferlevel,指的是用寄存器这一级别 ...
- CSS 各类 块级元素 行级元素 水平 垂直 居中问题
元素的居中问题是每个初学者碰到的第一个大问题,在此我总结了下各种块级 行级 水平 垂直 的居中方法,并尽量给出代码实例. 首先请先明白块级元素和行级元素的区别 行级元素 一块级元素 1 水平居中: ( ...
随机推荐
- POJ1236 强连通 (缩点后度数的应用)
题意: 一些学校有一个发送消息的体系,现在给你一些可以直接发送消息的一些关系(单向)然后有两个问题 (1) 问你至少向多少个学校发送消息可以让所有的学校都得到消息 (2) 问至少加多少条边 ...
- YII框架的自定义布局(嵌套式布局,版本是1.1.20)
0x01 创建控制器 0x02 创建文件夹,之后创建视图文件 0x03 浏览器访问cxy/index控制器,验证 以上就是使用默认的布局,非常简单,那么如果我不想用YII框架默认的布局呢,我想用自定义 ...
- Windows核心编程 第六章 线程基础知识 (下)
6.6 线程的一些性质 到现在为止,讲述了如何实现线程函数和如何让系统创建线程以便执行该函数.本节将要介绍系统如何使这些操作获得成功. 图6 - 1显示了系统在创建线程和对线程进行初始化时必须做些什么 ...
- React-状态提升
通常,多个组件需要反映相同的变化数据,这时建议将共享状态提升到最近的共同父组件中去. <!DOCTYPE html> <html> <head> <meta ...
- 【spring源码系列】之【BeanDefinition】
1. BeanDefinition简介 前面讲的解析bean标签,本质就是将bean的信息封装成BeanDefinition对象的过程,最后放入容器beanDefinitionMap中.spring ...
- JSON数据显示在jsp页面上中文乱码的解决办法
在@RequestMapping属性添加属性produces = "text/html;charset=utf-8",设置字符集为utf-8即可 代码如下: @RequestMap ...
- Redis 集群伸缩原理
Redis 节点分别维护自己负责的槽和对应的数据.伸缩原理:Redis 槽和对应数据在不同节点之间移动 环境:CentOS7 搭建 Redis 集群 一.集群扩容 1. 手动扩容 (1) 准备节点 9 ...
- Educational Codeforces Round 92 (Rated for Div. 2)
A.LCM Problem 题意:最小公倍数LCM(x,y),处于[l,r]之间,并且x,y也处于[l,r]之间,给出l,r找出x,y; 思路:里面最小的最小公倍数就是基于l左端点的,而那个最小公倍数 ...
- mysql枚举和集合
create table consumer( id int, name char(16), sex enum('male','female','other'), level enum('vip1',' ...
- 使用ldap客户端创建zimbra ldap用户的格式
cat << EOF | ldapadd -x -W -H ldap://:389 -D "uid=zimbra,cn=admins,cn=zimbra" dn: ui ...