python 爬虫实例(二)
环境:
OS:Window10
python:3.7
描述
打开下面的网址,之后抓取其中的图片
https://music.163.com/#/artist/album?id=101988&limit=120&offset=0
安装一些库文件
首先看你的网页版本,查看方法,打开【https://sites.google.com/a/chromium.org/chromedriver/downloads】之后显示如下图1,说明你的版本是2.45,
下载对应的版本的驱动下载地址【https://chromedriver.storage.googleapis.com/index.html】如下图2

(图1)

(图2)
上面的包文件下载到本地之后,把bin里面的EXE文件放到你本地安装的Python的【Scripts】文件夹路径下
自己的本地路径【C:\Users\XXXXXXX\AppData\Local\Programs\Python\Python37\Scripts】 整体代码如下
import time import requests
import os from bs4 import BeautifulSoup
from selenium import webdriver class GetMuisc: def __init__(self):
self.init_url = 'http://music.163.com/#/artist/album?id=101988&limit=120&offset=0'
self.folder_path = r"C:\pythonProject\wangyi" def request(self, url):
r = requests.get(url)
return r def mkdir(self, path):
path = path.strip()
isExists = os.path.exists(path) if not isExists:
print('创建名字叫做', path, '的文件夹')
os.makedirs(path)
print('创建成功!')
return True
else:
print(path, '文件夹已经存在了,不再创建')
return False def save_img(self, url, file_name):
print("开始请求图片地址...")
img = self.request(url)
print('开始保存图片')
with(open(file_name, "ab")) as ff:
ff.write(img.content)
print(file_name, '图片保存成功!') # f = open(file_name, "ab")
# f.write(img.content)
# f.close() def get_files(self, path):
pic_name = os.listdir(path)
return pic_name def spider(self):
print("Start!")
driver = webdriver.Chrome()
driver.get(self.init_url)
driver.switch_to.frame("g_iframe")
iframe_html = driver.page_source
driver.close() self.mkdir(self.folder_path)
file_name = self.get_files(self.folder_path)
os.chdir(self.folder_path) idstr = 'm-song-module'
moduleHtml = BeautifulSoup(iframe_html, 'lxml').find(id=idstr)
if moduleHtml is None:
print("标签{}没有找到,请检查是否有问题。".format(idstr))
else:
all_li = moduleHtml.find_all('li')
for li in all_li:
album_img = li.find("img")["src"]
album_name = li.find("p", class_="dec")["title"]
album_date = li.find("span", class_="s-fc3").get_text()
end_pos = album_img.index("?")
album_img_url = album_img[:end_pos] photo_name = album_date + " - " + album_name.replace("/", "").replace(":", ",") + ".jpg"
print(album_img_url, photo_name) if photo_name in file_name:
print('图片已经存在,不再重新下载')
else:
self.save_img(album_img_url, photo_name) album_cover = GetMuisc()
album_cover.spider()
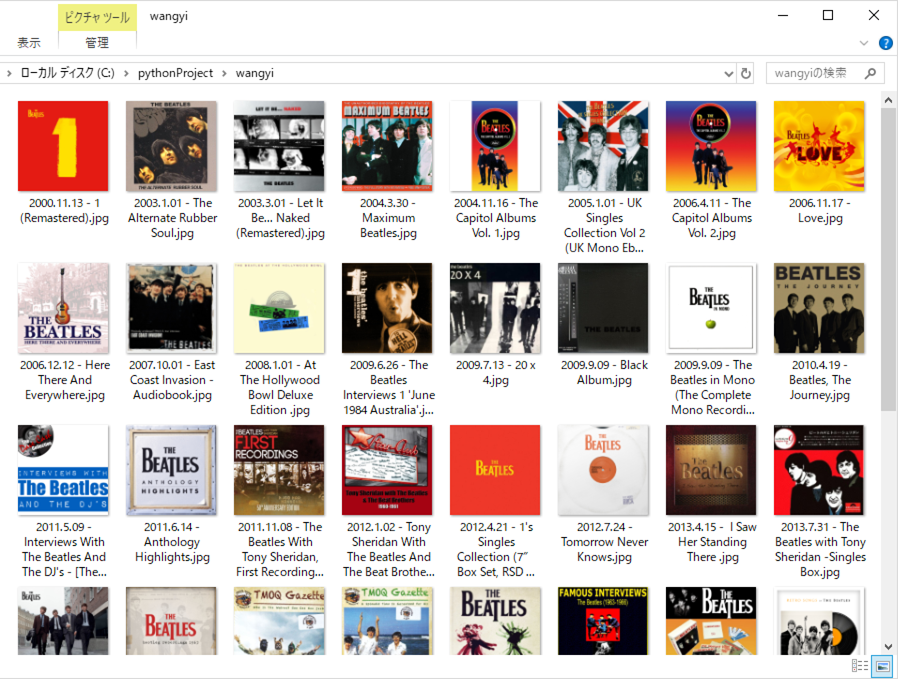
运行效果

python 爬虫实例(二)的更多相关文章
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫利器二之Beautiful Soup的用法
上一节我们介绍了正则表达式,它的内容其实还是蛮多的,如果一个正则匹配稍有差池,那可能程序就处在永久的循环之中,而且有的小伙伴们也对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Be ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫入门二之爬虫基础了解
静觅 » Python爬虫入门二之爬虫基础了解 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以 ...
- Python 爬虫实例
下面是我写的一个简单爬虫实例 1.定义函数读取html网页的源代码 2.从源代码通过正则表达式挑选出自己需要获取的内容 3.序列中的htm依次写到d盘 #!/usr/bin/python import ...
随机推荐
- 23、CacheManager原理剖析与源码分析
一.图解 二.源码分析 ###org.apache.spark.rdd/RDD.scalal ###入口 final def iterator(split: Partition, context: T ...
- UOJ272. 【清华集训2016】石家庄的工人阶级队伍比较坚强 [FWT]
UOJ 思路 很容易想到\(O(3^{3m}\log T)\)的暴力大矩乘,显然过不了. 我们分析一下每次转移的性质.题目给的转移方程是填表法,我们试着改成刷表法看看-- 发现好像没啥用. 注意到游戏 ...
- 03、CPU主频,和性能
性能?时间的倒数 有两个指标:一个是响应时间或者叫执行时间:一个是吞吐率或者带宽,这两个就可以理解为办事的时间和办事的多少. 而 性能= 1/响应时间 CPU时钟:计算机的计时单位 程序的CPU执行时 ...
- Java 自动装箱/拆箱
自动装箱/拆箱大大方便了基本类型(8个基本类型)数据和它们包装类的使用 自动装箱 : 基本类型自动转为包装类(int >> Integer) 自动拆箱: 包装类自动转为基本类型(Integ ...
- Nfs固定端口 nfs 端口公网映射
- Xcode: Xcode中Command Line Tools的安装方法
1. 打开终端: 2. 输入命令: xcode-select --install ,如果出现下图,说明你已经安装过了,下边内容也不用看了 如果出现下图说明还没有安装,点击安装 同意协议: 稍等片刻.. ...
- linux内核在哪里处理设备树中compatible为"syscon"的节点?
答: linux内核源码drivers/mfd/syscon.c中的of_syscon_register()接口对regmap_config进行初始化 注: linux内核源码版本为5.1.0
- AdapterViewFlipper
使用AdapterViewFiller组件设置图片轮播,该组件可以自动切换view <?xml version="1.0" encoding="utf-8" ...
- 国人开发的api测试工具 ApiPost
挺好用的 ApiPost https://www.apipost.cn/download.html 需要注册,免费试用.感觉比postman好用
- Spring cloud微服务安全实战-5-6实现授权码认证流程(2)
授权服务器,返回给我一个授权码,这里我只需要把授权传回去就可以了.来证明我是这个服务器. URI的地址传和第一次的地址一样的,认证服务器会比,第一次跳转的请求和第二次申请令牌的请求redirect_u ...