hadoop部署安装(三)zookeeper+yarn
1. 配置zookeeper
3.1 解压存放指定目录
[root@bogon src]# tar xf zookeeper-3.4.10.tar.gz
[root@bogon src]# mv zookeeper-3.4.10 /usr/local/zookeeper
3.2 创建zoo.cfg文件
[root@master ~]# vim /usr/local/zookeeper/conf/zoo.cfg
添加:
tickTime=2000
dataDir=/opt/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
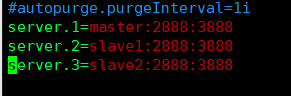
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
设置三台zookeeper集群,作为投票,必须是单数,才能保证投出leader节点
创建zoo.cfg指定的zookeepr节点的dataDir目录
[root@master ~]# mkdir /opt/zookeeper
[root@slave1 ~]# mkdir /opt/zookeeper
[root@slave2 ~]# mkdir /opt/zookeeper
3.2 配置myid
[root@master ~]# echo 1 >/opt/zookeeper/myid
[root@slave1 ~]# echo 2 >/opt/zookeeper/myid
[root@slave2 ~]# echo 3 >/opt/zookeeper/myid
设置每个zookeeper节点的id标识
3.3 拷贝zookeeper文件
[root@master ~]# scp -rp /usr/local/zookeeper/ slave1:/usr/local/
[root@master ~]# scp -rp /usr/local/zookeeper slave2:/usr/local/
将zookeeper文件拷贝到其他两个zookeeper节点上
3.4 配置各台zookeeper节点的环境变量
[root@master ~]# vim /etc/profile
修改:
#zookeeper
export PATH=$PATH:/usr/local/zookeeper/bin
将zookeeper的bin目录加入到环境中去

[root@master ~]# scp -rp /etc/profile slave1:/etc/
[root@master ~]# scp -rp /etc/profile slave2:/etc/
将环境变量文件同步到其他zookeeper节点中去

[root@master ~]# source /etc/profile
[root@slave1 ~]# source /etc/profile
[root@slave2 ~]# source /etc/profile
3.5 启动zookeeper
[root@master ~]# zkServer.sh start
[root@slave1 ~]# zkServer.sh start
[root@slave2 ~]# zkServer.sh start
在三台zookeeper节点同时启动zookeeper服务,并在启动时的当前路径下产生zookeeper日志文件zookeeper.out
查看zookeeper进程是否存在
[root@master ~]# jps
[root@slave1 ~]# jps
[root@slave2 ~]# jps
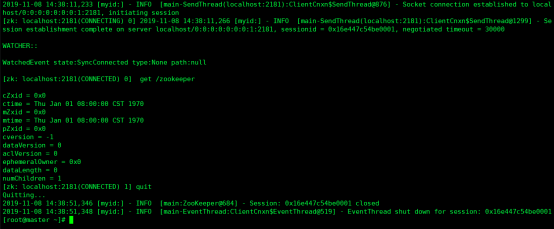
3.6 连接内存实时库
[root@master ~]# zkCli.sh
[zk: localhost:2181(CONNECTED) 2] get /zookeeper
[zk: localhost:2181(CONNECTED) 3] quit
解释:
Zookeeper正常启动会启动它的内存库,可以查看是否存在/zookeeper文件,表示zookeeper安装是否有问题
3.7 配置hadoop资源管理
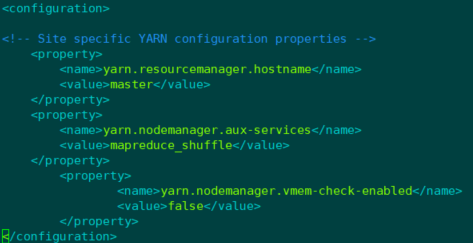
3.7.1 编辑yarn-site.xml文件
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
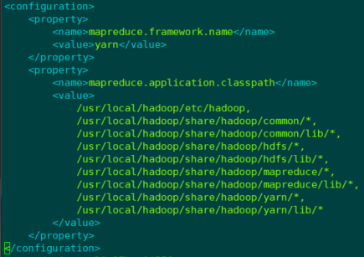
3.7.2 创建mapperd-site.xml文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
3.7.3 同步配置文件
[root@master hadoop]# scp yarn-site.xml slave1:/usr/local/hadoop/etc/hadoop/
[root@master hadoop]# scp yarn-site.xml slave2:/usr/local/hadoop/etc/hadoop/
[root@master hadoop]# scp mapred-site.xml slave1:/usr/local/hadoop/etc/hadoop/
[root@master hadoop]# scp mapred-site.xml slave2:/usr/local/hadoop/etc/hadoop/
3.7.4启动yarn服务及验证
[root@master hadoop]# start-yarn.sh

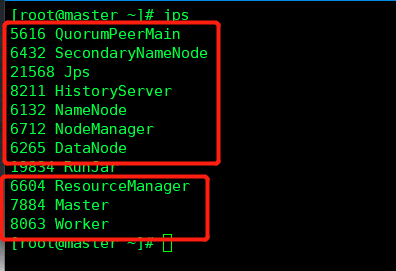
3.7.5 jps正常状态
master节点
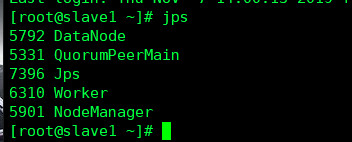
Slave节点
hadoop部署安装(三)zookeeper+yarn的更多相关文章
- kafka单机模式部署安装,zookeeper启动
在root的用户下 1):前提 安装JDK环境,设置JAVA环境变量 2):下载kafka,命令:wget http://mirrors.shuosc.org/apache/kafka/0.10.2 ...
- Hadoop 部署之 Hadoop (三)
目录 一.Hadoop 介绍 1.HDFS 介绍 2.HDFS 组成 3.MapReduce 介绍 4.MapReduce 架构 JobTracker TaskTracker 二.Hadoop的安装 ...
- hadoop 2.7.2 + zookeeper 高可用集群部署
一.环境说明 虚拟机:vmware 11 操作系统:Ubuntu 16.04 Hadoop版本:2.7.2 Zookeeper版本:3.4.9 二.节点部署说明 三.Hosts增加配置 sudo ge ...
- Apache Hadoop 2.9.2 的YARN High Available 模式部署
Apache Hadoop 2.9.2 的YARN High Available 模式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.环境准备 1>.官方文档(htt ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- 基于Docker搭建大数据集群(三)Hadoop部署
主要内容 Hadoop安装 前提 zookeeper正常使用 JAVA_HOME环境变量 安装包 微云下载 | tar包目录下 Hadoop 2.7.7 角色划分 角色分配 NN DN SNN clu ...
- hadoop的安装和配置(三)完全分布式模式
博主会用三篇文章为大家详细说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 完全分布式模式: 前面已经说了本地模式和伪分布模式,这两种在hadoop的应用中并不用于实际,因为几乎没人会 ...
- hbase、zookeeper及hadoop部署
一 机器192.168.0.203 hd203: hadoop namenode & hbase HMaster192.168.0.204 hd204: hadoop datanode &am ...
- Hadoop集群搭建-02安装配置Zookeeper
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
- hadoop 简单安装部署
hadoop第一课:虚拟机搭建和安装hadoop及启动 hadoop第二课:hdfs集群集中管理和hadoop文件操作 hadoop第三课:java开发hdfs hadoop第四课:Yarn和Map/ ...
随机推荐
- RDK新一代模型转换可视化工具!!!
作者:SkyXZ CSDN:SkyXZ--CSDN博客 博客园:SkyXZ - 博客园 之前在使用的RDK X3的时候,吴诺老师@wunuo发布了新一代量化转换工具链使用教程,这个工具真的非常的方便, ...
- 【质点弹簧实现】Unity 版示例
[质点弹簧实现]Unity 版示例 急速搭建的 Unity 版本的质点弹簧 Demo,不要在意帧率,这个 Demo 没有做任何优化.整个 Demo 就一个文件,直接在 Unity 创建里创建一个名为& ...
- autMan奥特曼机器人-内置wx机器人的相关说明
内置wx机器人的相关说明 内置wxbot机器人,经常有人说在群内无回复,做以下几个工作: 给群命名 通过机器人微信APP将此群加入到通讯录 重启autMan 内置微信机器人已经支持群名设置 例如转发时 ...
- 如何使用ISqlSugarClient进行数据访问,并实现了统一的批量依赖注入
仓储层当前有接口 IRepository<T> 抽象类 BaseRepository<T> 业务逻辑层有抽象类 BaseBusiness<M, E> 接口 IBu ...
- 解决CondaError: Run 'conda init' before 'conda activate'
前言 使用 Anaconda 激活 python 环境,报错: conda activate deepseek7B CondaError: Run 'conda init' before 'conda ...
- Windows 10右键添加 "在此处打开命令窗口" 菜单
1.添加右键菜单的两种效果: 第一种是在 桌面/文件夹窗口中/选中文件夹上直接点击右键,显示"在此处打开命令窗口"选项,如图: 第二种是在 桌面/文件夹窗口中/选中文件夹上按住Sh ...
- numpy -- 处理数值型数据 -- 数据分析三剑客
博客地址:https://www.cnblogs.com/zylyehuo/ NumPy(Numerical Python) 是 Python 语言中做科学计算的基础库.重在于数值计算,也是大部分Py ...
- List集合分页处理的方法
参考https://www.cnblogs.com/cmz-32000/p/12186362.html 解决了数组越界问题 参数页码大于总页码时返回null(可根据自己业务调整为返回最后一页数据) s ...
- 接口介绍以及定义和使用--java进阶day02
1.接口介绍 日常生活中有很多接口,比如手机数据线的接口和手机充电器的接口 我们转换视角,站在设计者的角度思考接口,接口体现出规则,手机的接口大小和数据线的接口大小必须一致,各种接口的大小都要一致,都 ...
- 【Linux】3.10 进程管理(重点)
进程管理 1. 进程管理基础 在Linux中,每个执行的程序(代码)都称为一个进程.每个进程都分配一个ID号 每一个进程,都会对应一个父进程,而这个父进程可以复制多个子进程.例如www服务器. 每个进 ...