使用SVM在数字验证码识别中的应用研究课程报告
第1章 概要设计
1.1 设计目的
支持向量机作为一类强大的监督学习模型,以其出色的泛化能力,在手写数字识别、面部检测、图像分类等多个领域展现出了其优越性。其在处理小样本、非线性及高维模式识别任务中表现尤为突出。SVM通过构造最优超平面,在保证分类准确性的同时,最大限度地提高了分类决策的置信度。此外,其核技巧有效地解决了线性不可分问题,使得SVM在图像识别领域尤为适用。
本研究旨在探索SVM在特定应用场景——数字验证码图像训练和识别——中的有效性及可行性。具体而言,本研究将基于Python语言,使用sklearn库中的SVM模块开发一套数字验证码的识别程序。研究的主要目的是验证SVM在数字验证码图像识别任务上的准确率和泛化性能,同时对比不同核函数对模型性能的影响,以寻找最优的模型配置。
1.2 选题
验证码(CAPTCHA)是一种常见的用于区分人类和机器的技术,常用于网站、APP用户登陆时输入一些数字或字符以验证其身份。本文将介绍如何使用SVM来识别常见的字符验证码。
选择使用支持向量机进行验证码识别方向的原因具体如下:
1. 卓越的泛化能力:SVM在设计时就是以最小化结构风险为目标,而不仅仅是经验风险,这赋予了SVM模型极好的泛化能力,即对于未见样本的预测能力。在验证码识别任务中,能够正确识别新的、未经过训练的验证码图片是至关重要的。
2. 处理小样本的优势:相比于深度学习等其他机器学习方法,SVM在小样本情况下依然能够保持较好的分类性能,这对于验证码这种较难获取大量标注数据的场景尤为重要。
3. 高维空间的效率:由于SVM能够有效处理高维数据,并且通过核技巧隐式地在高维空间中寻找最优的线性划分,使得其在图像识别任务中,即使面对大量特征的情形下仍具有高效的计算性能。
4. 灵活的核函数选择:SVM可以通过选择不同的核函数来适应不同的数据分布,如线性核、多项式核、径向基核等,使得其对各种类型的验证码都有很好的识别潜力。
5. 成熟的理论和实践基础:SVM作为一种经典的机器学习算法,拥有成熟的理论基础和广泛的应用场景,这意味着在实施过程中可以借鉴丰富的先前研究和实践经验,降低开发难度并加快开发周期。
6. 字符识别方面显著表现:在以往的研究中,SVM在字符型图片验证码识别任务上已经展现出了显著的性能,包括高准确率和良好的泛化性,这使得SVM成为了解决此类问题的有效工具。
综上所述,SVM在验证码识别领域的应用具有多方面的优势,从理论基础到实践应用都显示出其适用于该领域的特性。因此,选择SVM进行验证码识别不仅基于其技术上的优势,也在于其在实际应用中所展现出来的高效性和准确性。
1.3 支持向量机(SVM)算法的原理
支持向量机(SVM)是一种监督学习算法,主要用于解决二分类问题,其核心思想是通过在特征空间中找到最优的超平面来进行分类,同时使间隔最大化。
(1) 超平面与间隔:
SVM算法的核心思想是在特征空间中寻找一个最优的超平面,该超平面能够将不同类别的样本分隔开。
这个超平面可以被定义为在n维空间中的一个(n-1)维子空间,其中n是特征的数量。
SVM通过最大化两个类别之间的间隔来确定这个超平面。间隔是指超平面到最近的样本距离的两倍。这个间隔越大,模型的泛化能力通常越强。
(2) 核函数与映射:
当数据在原始空间中不可分时,SVM算法会将数据映射到一个更高维的空间中,使得数据在该空间中变得线性可分。
这种映射通常是通过核函数来实现的,核函数可以计算两个样本在高维空间中的相似度。常见的核函数包括线性核、多项式核、高斯核等。
(3) 分类与软间隔:
SVM算法主要用于二分类问题,但也可以通过多次训练和组合来解决多分类问题。
在处理线性不可分的数据时,SVM允许一些样本在超平面的错误一侧,即引入软间隔的概念。这可以通过引入惩罚参数来平衡间隔的大小和分类错误的容忍度。
(4) 优化与求解:
SVM算法的训练过程可以转化为一个凸优化问题,通常被表述为一个二次规划问题。
由于二次规划问题具有全局最优解,因此可以使用现有的优化算法来求解SVM的最优超平面。
(5)优点与缺点:
优点:SVM能够处理高维数据,具有较强的泛化能力,适用于小样本数据,可以处理非线性问题,具有较好的鲁棒性和可解释性。
缺点:SVM对参数的敏感性较高,计算复杂度较高,尤其是当数据集较大或特征维度较高时。此外,SVM对数据的缩放和噪声也比较敏感。
综上所述,SVM算法通过寻找最优超平面来实现数据分类,其性能受到核函数、软间隔以及惩罚参数等因素的影响。在实际应用中,需要根据具体的数据和任务来选择合适的SVM模型和参数设置。
1.4 程序概要设计
验证码(CAPTCHA)是一种常见的用于区分人类和机器的技术,常用于网站、APP用户登陆时输入一些数字或字符以验证其身份。使用支持向量机(SVM)来识别常见的字符验证码,主要步骤流程如下。
(1)数据收集与预处理
数据收集:收集包含不同字符、字体、背景、噪点、扭曲等变化的验证码图像数据集。
数据标注:对每个验证码图像进行人工标注,确定其对应的字符序列。
图像预处理:对图像进行去噪、二值化等处理,以便后续的特征提取。
(2)特征值提取
基于像素的特征:可以使用图像的原始像素值或像素的统计信息(如直方图)作为特征。
基于形状的特征:对于字符验证码,可以提取字符的轮廓、边缘、角点等形状特征。
基于纹理的特征:利用局部二值模式(LBP)、灰度共生矩阵(GLCM)等方法提取字符的纹理特征。
(3)支持向量机(SVM)模型训练
核函数选择:根据数据特点选择合适的核函数,如线性核、多项式核、径向基函数(RBF)核等。
参数优化:使用交叉验证和网格搜索等方法优化SVM的惩罚参数C和核函数参数(如RBF核的gamma)。
模型训练:使用标注好的数据集训练SVM模型,得到字符分类器。
(4)评估模型和改进
评估指标:使用准确率指标评估模型的性能。
错误分析:对识别错误的验证码进行错误分析,找出模型存在的问题和改进方向。
模型改进:根据错误分析的结果,调整特征提取方法、优化SVM参数、使用更先进的模型等方法来改进模型的性能。
第2章 程序整体设计说明
2.1 数据收集与预处理
首先,我们需要收集带有字符验证码的图片数据,并将其分为训练集和测试集。确保每张图片都标记了正确的字符。
很多网站都有验证码功能,可以先写个爬取验证码图片的脚本,采集了500份目标网站的验证码图片;80%用于训练数据集,20%用于测试数据集;然后人工打上标签,把答案作为验证码图片的文件名前4个字符。
然后需要将采集的500份验证码图片进行字符切割预处理,分割成单个字符的图片保存,这些分割后的图片才是训练数据集和测试数据集,单个字符图片更适合于SVM算法训练,训练的模型准确度更高。
# 数据集目录结构示例:
# ├── data
# │ ├── image_train
# │ │ ├──
0
# │ │ ├── 1
# │ │ ├── 2
# │ │ ├── ...
# │ ├── image_test
# │ │ ├── 0
# │ │ ├── 1
# │ │ ├── 2
# │ │ ├── ...
(1)
标签列表
使用单个数字整数作为样本的标签值,保证是统一的整数分类形式。
(2)
导入数据集方法
根据目录导入数据集,统一处理样本集,获取图片的特征值,将特征值添加到特征列表中;图片标签需要统一转换下,然后添加到标签列表中返回。
# 加载数据集(这里已经有一个包含标签的图片文件夹)
def load_dataset(data_folder):
labels = []
features = []
for label in os.listdir(data_folder):
label_dir = os.path.join(data_folder, label)
for filename in os.listdir(label_dir):
if filename.endswith('.png'):
image_path = os.path.join(label_dir, filename)
# 提取特征
feat = extract_features(image_path)
# 将图像特征值添加到列表中
features.append(feat)
# 将图像标签值添加到列表中
labels.append(int(label))
return np.array(features), np.array(labels)
(3) 加载训练数据和测试数据
# 加载训练数据和测试数据
train_features, train_labels = load_dataset('./data/image_train')
test_features, test_labels = load_dataset('./data/image_test')
print(f"训练集特征值列表:{train_features}")
print(f"测试集特征值列表:{test_features}")
print(f"训练集标签:{train_labels}")
print(f"测试集标签:{test_labels}")
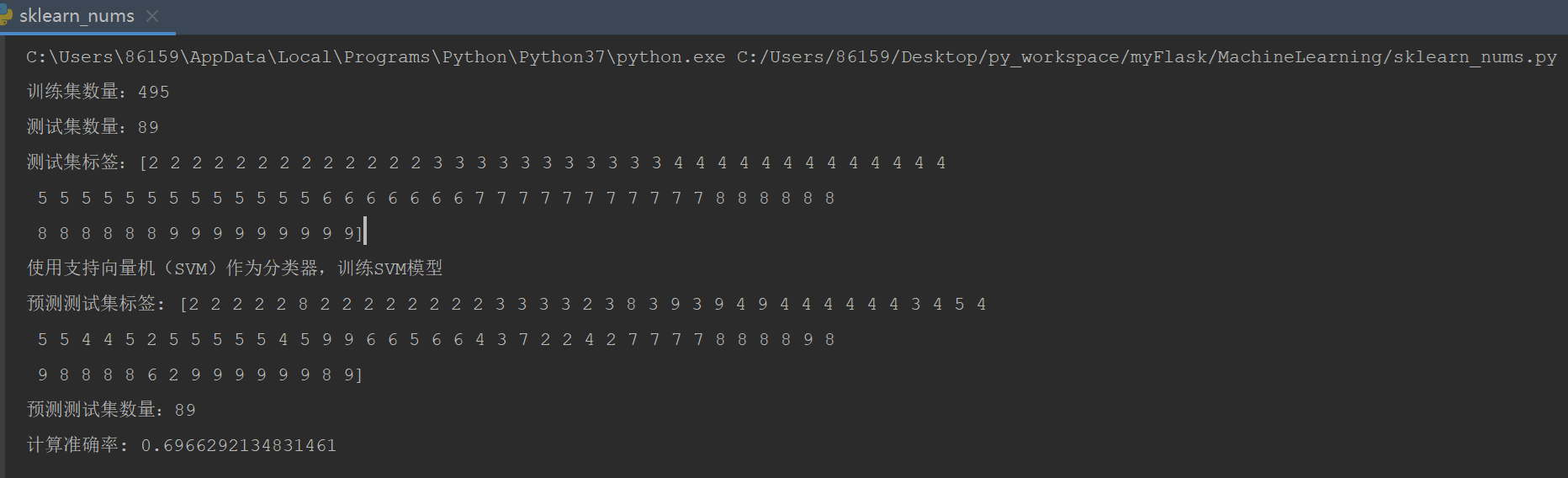
print(f"训练集数量:{train_labels.size}")
print(f"测试集数量:{test_labels.size}")
2.2 特征值提取
数字验证码有位置、方向、周长、面积、矩形度、宽长比、球状性、圆形度、不变矩、偏心率等各种特征。对图像进行灰度化再经过二值化等处理可以得到图像中数字的轮廓,利用该轮廓可以求得各种特征,利用一些特征构造模型可以实现对数字种类的检测识别,通过多次筛选,选出性能最优的几种特征值列表。
# 提取特征
def extract_features(image_path):
# 步骤 1: 读取图像
image = cv2.imread(image_path)
# 步骤 2: 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 步骤 3: 二值化
_, thresh = cv2.threshold(gray, 8, 255, cv2.THRESH_BINARY)
# 步骤 4: 轮廓提取
contours, _ = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
features = []
if len(contours) > 0:
# 获取最大长度轮廓列表值,去除干扰点轮廓
max_length_contour = max(contours, key=lambda x: len(x))
# print(f'max_length_contour :{max_length_contour}')
M = cv2.moments(max_length_contour)
M = cv2.HuMoments(M) # 计算轮廓的HU矩
# print(f'轮廓的HU矩 :{M}')
rect = cv2.minAreaRect(max_length_contour)
box = cv2.boxPoints(rect)
box = np.int0(box)
(x, y), radius = cv2.minEnclosingCircle(max_length_contour)
center = (int(x), int(y))
# print(f'中心点 :{center}')
radius = int(radius)
# print(f'半径 :{radius}')
w = min(rect[1][0], rect[1][1]) # 宽度
h = max(rect[1][0], rect[1][1]) # 长度
wh = w / h # 宽长比例
# print(f'宽长比例 :{wh}')
s = cv2.contourArea(max_length_contour) # 面积
# print(f'面积 :{s}')
l = cv2.arcLength(max_length_contour, True) # 周长
# print(f'周长 :{l}')
radius_area = radius / s # 半径面积比
# print(f'半径面积比 :{radius_area}')
radius_arc = radius / l # 半径周长比
# print(f'半径周长比 :{radius_arc}')
l_wh = l / (w * h) # 周长长宽比
# print(f'周长长宽比 :{l_wh}')
ls = l / s # 周长面积比
# print(f'周长面积比 :{ls}')
roundness = (4 * np.pi * s) / (l * l) # 圆形度
# print(f'圆形度 :{roundness}')
r = s / (w * h) # 矩形度
# print(f'矩形度 :{r}')
# 根据不同类型图片数据,最后选择几种组合的特征值作为提升准确率
features_name = ['周长长宽比', '周长面积比', '宽长比例', '矩形度', '圆形度']
features = [l_wh, ls, wh, r, roundness]
# 使用列表推导式和round函数格式化列表数据,保留4位小数
features = [round(num, 4) for num in features]
else:
exit(0)
return features
2.3 支持向量机(SVM)模型训练
根据训练数据集使用支持向量机(SVM)作为分类器,训练SVM模型。
(1)核函数选择:
根据数据特点选择合适的核函数,如线性核、多项式核、径向基函数(RBF)核等。
线性核函数(Linear Kernel):
表达式:K(x,z) = x ∙ z,即普通的内积。
使用场景:当数据是线性可分时,或者你想使用线性模型时。
备注:LinearSVC 和 LinearSVR 只能使用线性核函数。
多项式核函数(Polynomial Kernel):
表达式:K(x,z) = (γx∙z + r)^d,其中γ, r, d都需要自己调参定义。
使用场景:当数据有一定程度的非线性,并且你想通过增加多项式的阶数来捕捉更多的非线性关系时。
径向基函数核(Radial Basis Function Kernel,RBF),也称为高斯核函数(Gaussian Kernel):
表达式:K(x,z) = exp(−γ||x−z||^2),其中γ大于0,需要自己调参定义。
使用场景:对于大多数非线性问题,默认的高斯核函数通常都有比较好的效果。
备注:这是SVC的默认核函数。
(2)惩罚参数C优化:
SVM算法主要用于二分类问题,但也可以通过多次训练和组合来解决多分类问题。在处理线性不可分的数据时,SVM允许一些样本在超平面的错误一侧,即引入软间隔的概念。这可以通过引入惩罚参数来平衡间隔的大小和分类错误的容忍度。
惩罚参数C : 浮点数, 默认值为1.0
正则化参数。正则化的强度与C成反比。必须严格为正。惩罚项是平方的次l2惩罚。
from sklearn import svm
# 选择最优参数
clf = svm.SVC(C=0.5, kernel='poly')
clf.fit(train_features, train_labels)
print("使用支持向量机(SVM)作为分类器,训练SVM模型")
2.4 评估模型
评估一个训练好的模型在测试数据集上的性能,计算预测结果标签列表和真实结果标签列表的准确率,是一个通用的评估模型性能指标。
# 预测测试集
y_pred = clf.predict(test_features)
print('预测测试集标签:', y_pred)
# 计算准确率
accuracy = accuracy_score(test_labels, y_pred)
print('计算准确率:', accuracy)
2.5 模型参数调优
通过不断的优化特征值和SVM模型参数调优,最终选择准确率最高的模型作为结果。
# 获取特征值列表的所有可能子集列表
def get_all_child_list(train_features_np, test_features_np):
# 获取列数
num_cols = train_features_np.shape[1] # 初始化一个空列表来存储所有子集
all_subsets_train = []
all_subsets_test = [] # 遍历从1列到所有列的所有组合
for r in range(1, num_cols + 1):
# 生成所有r列的组合索引
combinations_r_cols = list(itertools.combinations(range(num_cols), r)) # 遍历每个组合索引并提取数据
for cols in combinations_r_cols:
# 使用NumPy索引从train_features_np中提取列
subset_train = train_features_np[:, list(cols)].tolist()
# 使用相同的索引从test_features_np中提取列
subset_test = test_features_np[:, list(cols)].tolist() # 将子集添加到列表中
all_subsets_train.append(subset_train)
all_subsets_test.append(subset_test) # 打印test_features的子集数量(与train_features相同)
print(f"all_subsets_train总共有 {len(all_subsets_train)} 个子集列表")
print(f"test_features总共有 {len(all_subsets_test)} 个子集列表")
return all_subsets_train, all_subsets_test # 遍历所有子集特征值列表,然后训练模型和预测
def all_subsets_svc(all_subsets_train, all_subsets_test, train_labels, test_labels):
# 打印前几个子集作为示例
for i, (subset_train_features, subset_test_features) in enumerate(
zip(all_subsets_train, all_subsets_test)): # 仅打印前5个作为示例
print(f"子集 {i + 1}(train_features): {subset_train_features}")
print(f"子集 {i + 1}(test_features): {subset_test_features}") # 使用支持向量机(SVM)作为分类器
clf = svm.SVC(C=0.5, kernel='poly')
clf.fit(subset_train_features, train_labels)
print("使用支持向量机(SVM)作为分类器,训练SVM模型")
# 预测测试集
y_pred = clf.predict(subset_test_features)
print('预测测试集标签:', y_pred)
print(f"预测测试集数量:{y_pred.size}")
# 计算准确率
accuracy = accuracy_score(test_labels, y_pred)
print('计算准确率:', accuracy)
print("=========================================")
第3章 程序运行效果
3.1 程序运行结果:
(1) 特征值调优
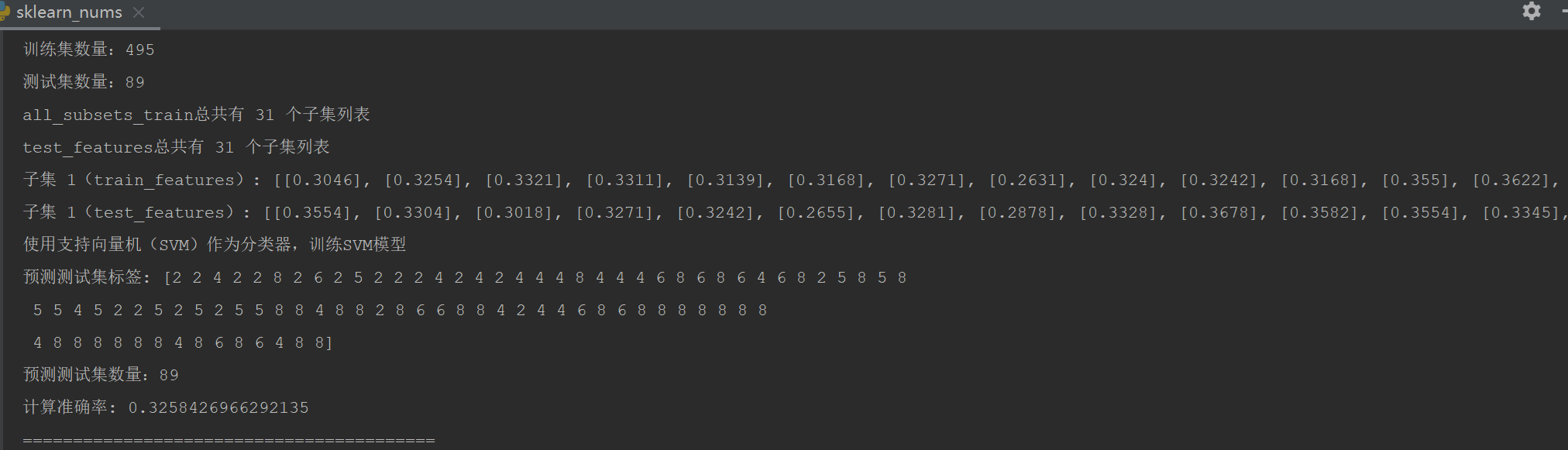


经过测试对比:特征值列表选择最佳如下:
['周长长宽比', '周长面积比', '宽长比例', '矩形度', '圆形度']
(2) SVM模型参数调优
①核函数选择
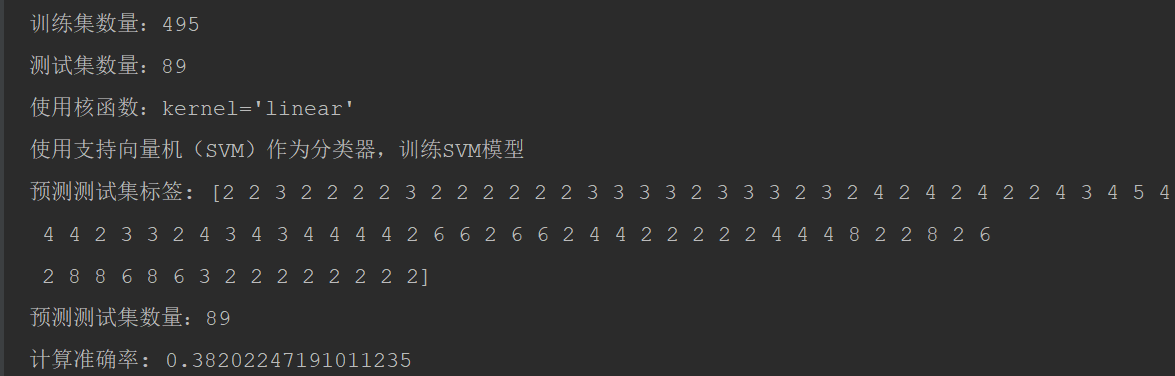
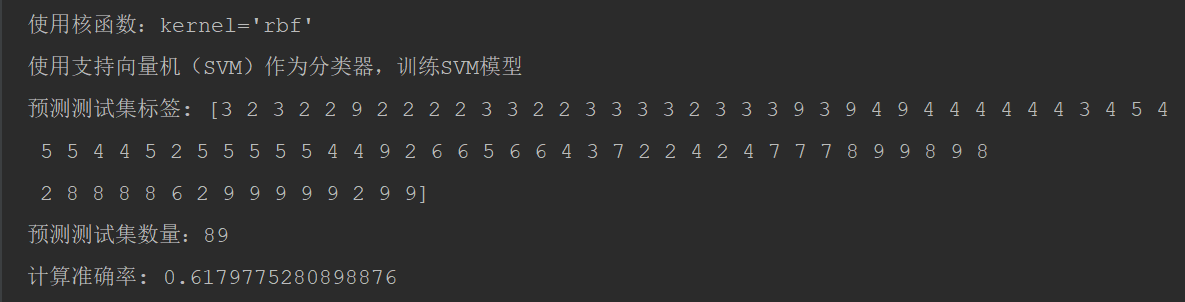
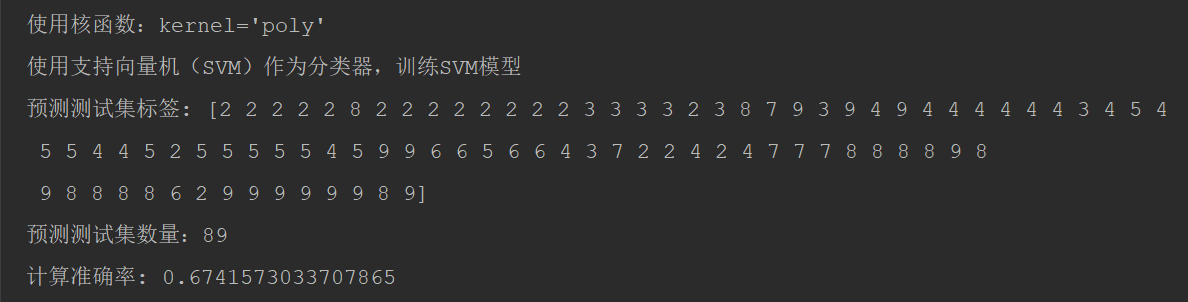
经过测试对比:核函数选择kernel='poly'最佳。
kernel='linear', 计算准确率: 0.38202247191011235
kernel='rbf', 计算准确率: 0.6179775280898876
kernel='poly', 计算准确率: 0.6741573033707865
②惩罚参数C调整
经过测试对比:惩罚参数设置C=0.5最佳。
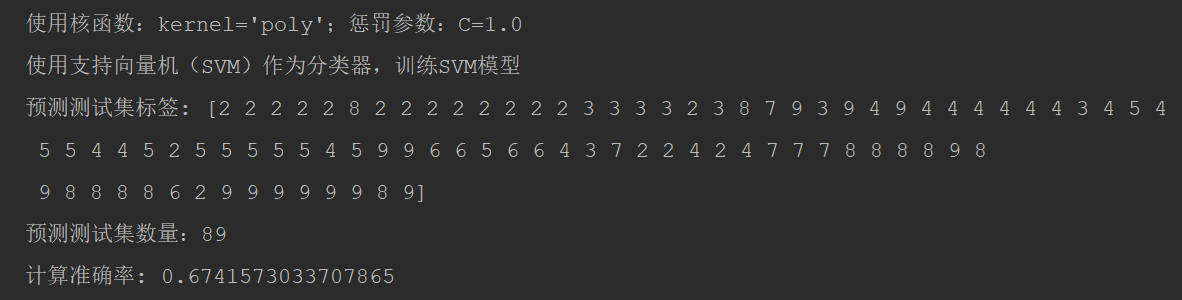
C=1.0, kernel='poly',计算准确率: 0.6741573033707865
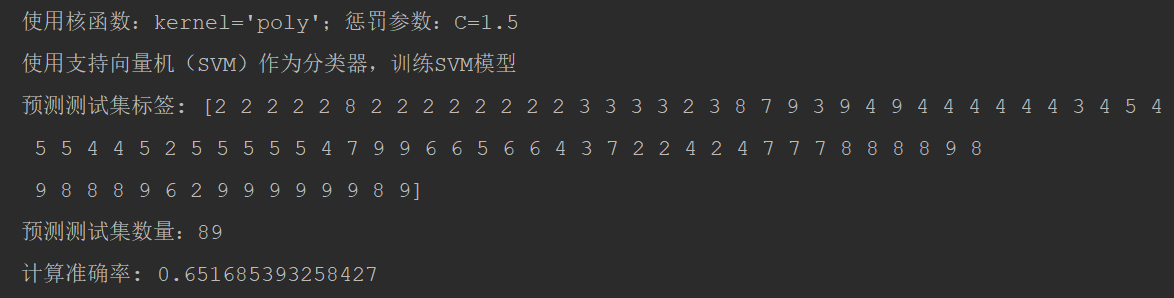
C=1.5, kernel='poly',计算准确率: 0.651685393258427
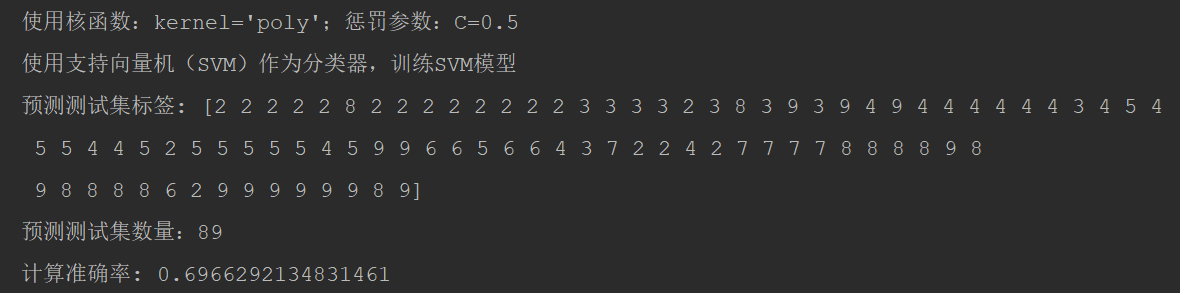
C=0.5, kernel='poly',计算准确率: 0.6966292134831461
(3) 最终模型运行结果
最终模型调优后,计算准确率: 0.6966292134831461。
第4章 设计中遇到的重点及难点
4.1 设计中遇到的重点
在本次的SVM算法识别验证码图片的设计实现过程中,遇到很多难点,主要的难点如下:
(1)数据集的预处理,要保证数据分类统一。
主要的解决步骤分为以下几点:
① 验证码图片需要分割为单个字符图片,直接使用4位字符的验证码图片去训练模型效果很差,而且不好分类;
② 分割后的单个字符图片需要人工标签对应的真实值。
(2)特征值的选择。
数字验证码有位置、方向、周长、面积、矩形度、宽长比、球状性、圆形度、不变矩、偏心率等各种特征,如何选择最优特征值组合:
① 一开始人工选择几种特征值组合测试,发现类似矩形度、圆形度这类小数点特征值训练的模型,准确率更高,选择周长、面积等大于1的特征值训练的模型,准确率更低;
② 然后特地选择了全部由小数点的特征值列表,再计算出特征值列表的所有子集列表,测试出所有特征值子集列表训练模型的准确率,选出其中准确率最高的特征值列表。
(3)SVM模型的参数调整。
SVM模型参数调整有以下几点:
① 核函数选择:根据数据特点选择合适的核函数,如线性核、多项式核、径向基函数(RBF)核等,测试出准确率最高的核函数。
② 惩罚参数C优化:根据默认值1.0,逐步上下调整0.1,测试出准确率最高的核函数。
第5章 本次设计存在不足与改良方案
5.1 本次设计中存在的不足
在本次设计中主要有以下几个方面是不完善的。
(1)数据集分类上存在不足:
由于采集的验证码图片数量有限,最后分割后单个字符图片,数字类只有2-9,缺少0和1。
(2)验证码图片分割后图片需要人工标签真实值:
由于需要分割4位字符的验证码图片为单个字符图片方便CNN模型训练使用,编写了分割图片代码,但是需要人工给这些分割后的图片打标签,图片重新命名。
(3)特征值选择存在不足:
由于选择的特征值都是基于形状的特征:轮廓形状计算出的几种特征值,经过多次调优,准确率也只有69%,一般准确率至少要到达90%才算合格的模型。
5.2 本次设计的改良方案
(1)增加数据集样本量:
保证分割后单个字符图片两大类:数字字符有0-9中的10类和字母字符A-Z中的26类,完善这两种字符数据分类。
(2)验证码图片分割后图片自动打上标签真实值:
编写简易的OCR识别代码,将这些分割后的单个字符图片统一识别文字,自动修改图片名称,打上标签真实值,减少人工耗时。
(3)增加更多的特征值:
基于像素的特征:可以使用图像的原始像素值或像素的统计信息(如直方图)作为特征。
基于纹理的特征:利用局部二值模式(LBP)、灰度共生矩阵(GLCM)等方法提取字符的纹理特征。
使用SVM在数字验证码识别中的应用研究课程报告的更多相关文章
- 基于SVM的字母验证码识别
基于SVM的字母验证码识别 摘要 本文研究的问题是包含数字和字母的字符验证码的识别.我们采用的是传统的字符分割识别方法,首先将图像中的字符分割出来,然后再对单字符进行识别.首先通过图像的初步去噪.滤波 ...
- 基于SVM.NET的验证码识别算法实现
工作之余,对这个算法做了一些研究,并成功对验证码进行了识别,对普通验证码识别率在90%左右,识别速度相当快,已基于此做过一些自动查询.提交程序(例如投票.发帖等) ,还上过淘宝店,赚过一笔外快,现将相 ...
- OpenCV 数字验证码识别
更新后代码下载链接在此! !! 点我下载 本文针对OpenCv入门人士.由于我也不是专门做图像的,仅仅是为了完毕一次模式识别的小作业. 主要完毕的功能就是自己主动识别图片中的数字.图片包含正常图片,有 ...
- 17、OpenCV Python 数字验证码识别
__author__ = "WSX" import cv2 as cv import numpy as np from PIL import Image import pytess ...
- python cv2在验证码识别中的使用
使用函数cv2.imread(filepath,flags)读入一副图片 filepath:要读入图片的完整路径 flags:读入图片的标志 cv2.IMREAD_COLOR:默认参数,读入一副彩色图 ...
- [验证码识别技术]字符验证码杀手--CNN
字符验证码杀手--CNN 1 abstract 目前随着深度学习,越来越蓬勃的发展,在图像识别和语音识别中也表现出了强大的生产力.对于普通的深度学习爱好者来说,一上来就去跑那边公开的大型数据库,比如I ...
- 简单验证码识别(matlab)
简单验证码识别(matlab) 验证码识别, matlab 昨天晚上一个朋友给我发了一些验证码的图片,希望能有一个自动识别的程序. 1474529971027.jpg 我看了看这些样本,发现都是很规则 ...
- 第二十三节:scrapy爬虫识别验证码(二)图片验证码识别
图片验证码基本上是有数字和字母或者数字或者字母组成的字符串,然后通过一些干扰线的绘制而形成图片验证码. 例如:知网的注册就有图片验证码 首先我们需要获取验证码图片,通过开发者工具我们可以得到验证码ur ...
- Windows平台python验证码识别
参考: http://oatest.dragonbravo.com/Authenticate/SignIn?returnUrl=%2f http://drops.wooyun.org/tips/631 ...
- python之基于libsvm识别数字验证码
1. 参考 字符型图片验证码识别完整过程及Python实现 2.图片预处理和手动分类 (1)分析图片 from PIL import Image img = Image.open('nums/ttt. ...
随机推荐
- 主动式AI(代理式)与生成式AI的关键差异与影响
大型语言模型(LLMs)如GPT可以生成文本.回答问题并协助完成许多任务.然而,它们是被动的,这意味着它们仅根据已学到的模式对接收到的输入作出响应.LLMs无法自行决策:除此之外,它们无法规划或适应变 ...
- 即时通讯技术文集(第44期):微信、QQ技术精华合集(Part1) [共14篇]
为了更好地分类阅读 52im.net 总计1000多篇精编文章,我将在每周三推送新的一期技术文集,本次是第44 期. [-1-] 微信朋友圈千亿访问量背后的技术挑战和实践总结 [链接] http:/ ...
- 【狂神说Java】Java零基础学习笔记-异常
[狂神说Java]Java零基础学习笔记-异常 异常01:Error和Exception 什么是异常 实际工作中,遇到的情况不可能是非常完美的.比如:你写的某个模块,用户输入不一定符合你的要求.你的程 ...
- 2024-12-28 AI智能体日报
- 6种@Transactional注解的失效场景
一.事务 事务管理在系统开发中是不可缺少的一部分,Spring提供了很好事务管理机制,主要分为编程式事务和声明式事务两种. 编程式事务:是指在代码中手动的管理事务的提交.回滚等操作,代码侵入性比较强, ...
- ctfshow--web13 .user.ini上传和bak源码泄露
upload.php.bak源码泄露了 审计一下 点击查看代码 <?php header("content-type:text/html;charset=utf-8"); $ ...
- dart变量类型详解
1==> 三个单引号的作用 String Str = ''' qijqowjdo 哈哈嘿嘿黑 '''; print(Str); 这样使用三个单引号,输出来换行:方便我们观看而已哈 2==> ...
- PostgreSQL 数据备份与恢复:掌握 pg_dump 和 pg_restore 的最佳实践
title: PostgreSQL 数据备份与恢复:掌握 pg_dump 和 pg_restore 的最佳实践 date: 2025/1/28 updated: 2025/1/28 author: c ...
- last和history 查看登录和操作命令
last命令 last命令:用于显示用户最近登录信息.单独执行last命令,它会读取/var/log/wtmp的文件,并把该文件的内容记录的登入系统的用户名单全部显示出来. 语法 last(选项)(参 ...
- linux mint安装hadoop
一.安装 安装ssh openssh-server 配置jdk环境变量~/.bashrc参考 export JAVA_HOME=/opt/jdk1.7.0_55/ export JRE_HOME= ...