Spring的三级缓存详解
目录
1、什么是三级缓存
2、三级缓存详解
Bean实例化前
属性赋值/注入前
初始化后
总结
3、怎么解决的循环依赖
4、不用三级缓存不行吗
5、总结
一、什么是三级缓存
就是在Bean生成流程中保存Bean对象三种形态的三个Map集合,如下:

用来解决什么问题 ?
这个大家应该熟知了,就是循环依赖
什么是循环依赖 ?
就像下面这样,AService 中注入了BService ,而BService 中又注入了AService ,这就是循环依赖

这几个问题我们结合源码来一起看一下:
三级缓存分别在什么地方产生的?
三级缓存是怎么解决循环依赖的?
一定需要三级缓存吗?二级缓存不行?
二、三级缓存详解
不管你了不了解源码,我们先看一下Bean的生成流程,看看三级缓存是在什么地方有调用,就三个地方:
1、Bean实例化前会先查询缓存,判断Bean是否已经存在
2、Bean属性赋值前会先向三级缓存中放入一个lambda表达式,该表达式执行时会获取一个半成品Bean放入二级缓存并删除三级缓存
3、Bean初始化完成后将完整的Bean放入一级缓存,同时清空二、三级缓存
接下来我们一个一个看!
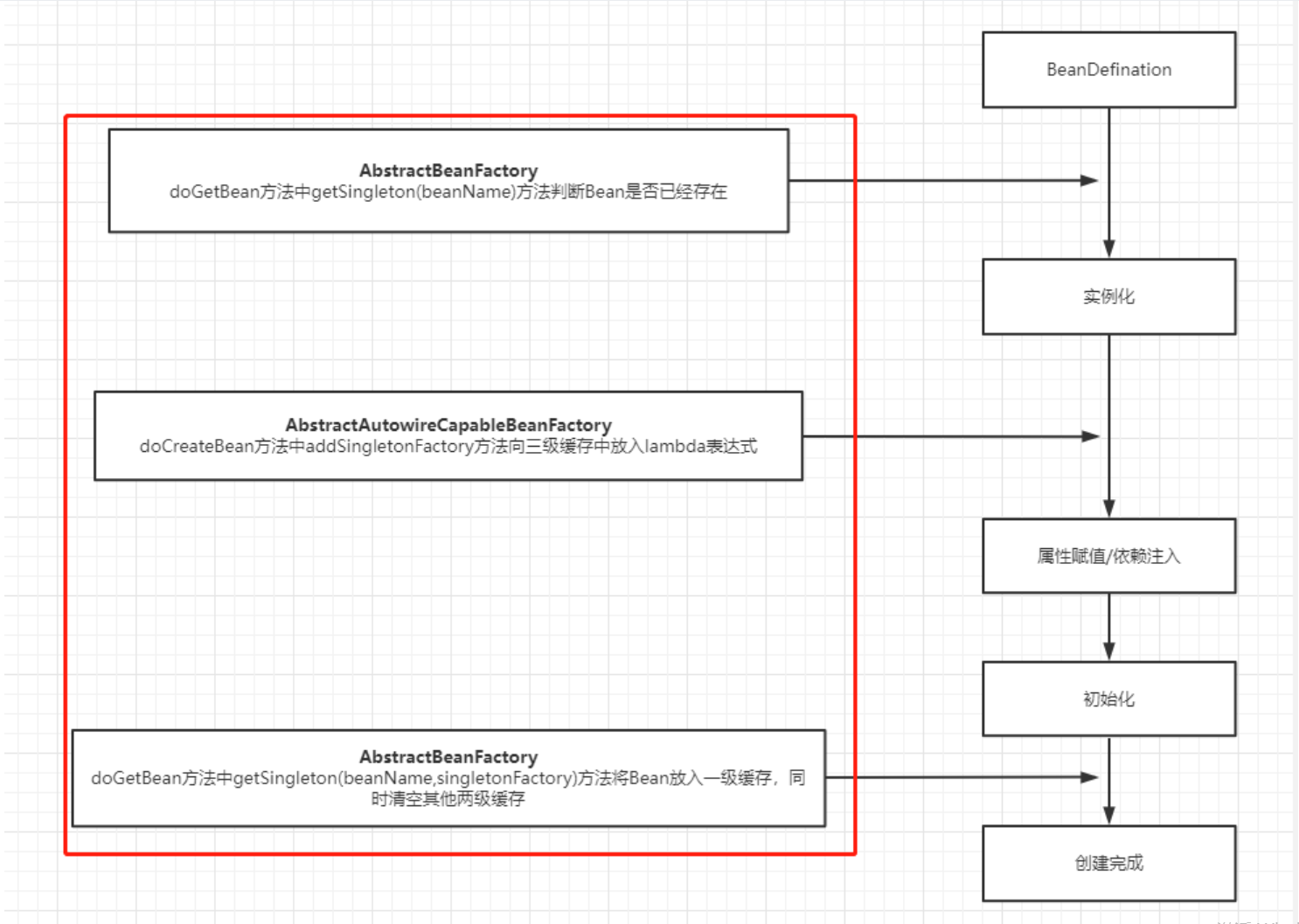
1、Bean实例化前
AbstractBeanFactory.doGetBean
Bean实例化前会从缓存里面获取Bean,防止重复实例化

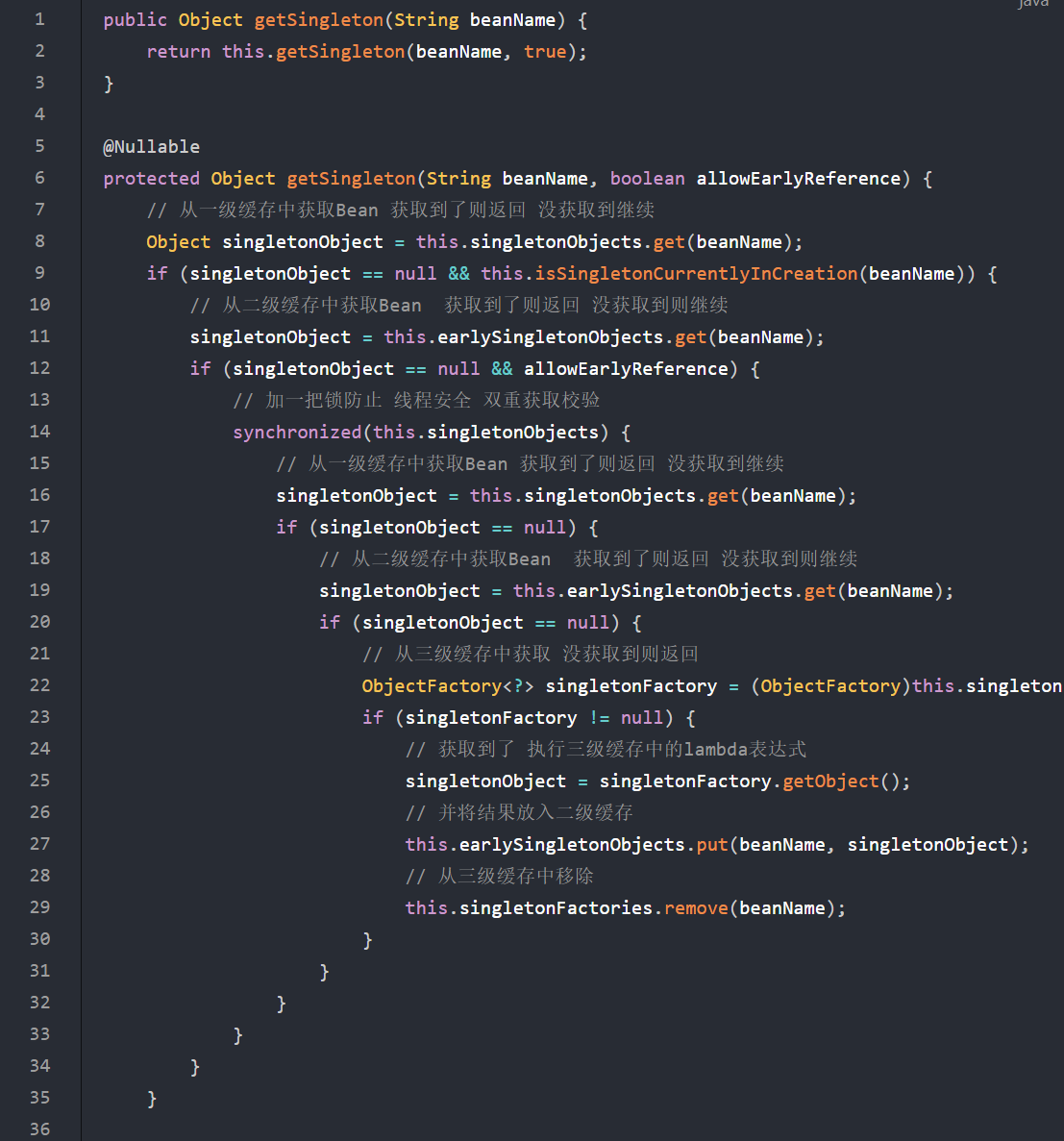
DefaultSingletonBeanRegistry.getSingleton(String beanName, boolean allowEarlyReference)
我们看看这个获取的方法逻辑:
a、从一级缓存获取,获取到了,则返回
b、从二级缓存获取,获取到了,则返回
c、从三级缓存获取,获取到了,则执行三级缓存中的lambda表达式,将结果放入二级缓存,清除三级缓存
2、属性赋值/注入前
AbstractAutowireCapableBeanFactory.doCreateBean
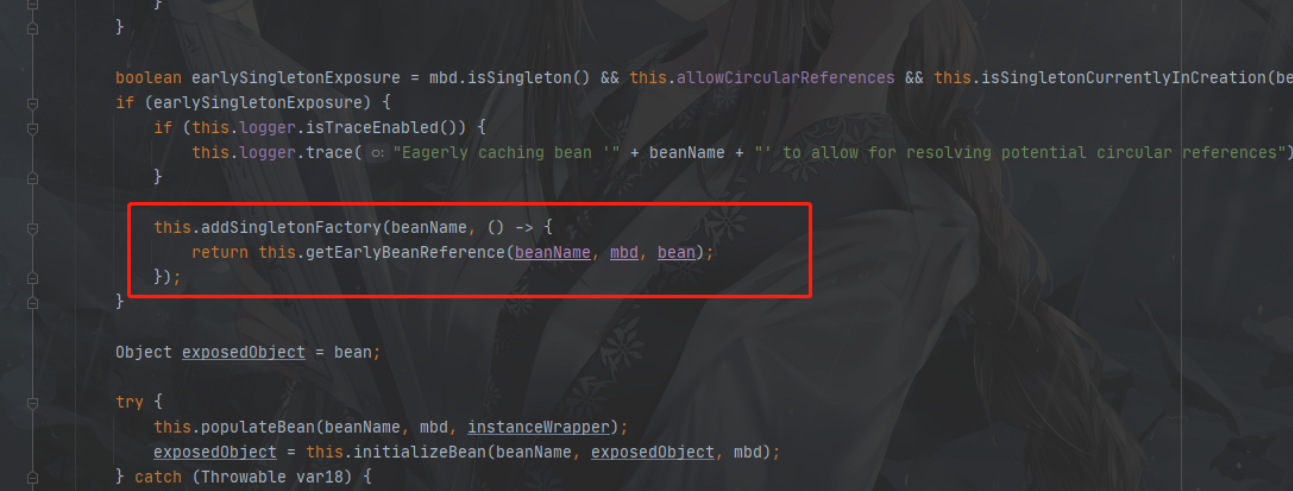
DefaultSingletonBeanRegistry.addSingletonFactory
这里就是将一个lambda表达式放入了三级缓存,我们需要去看一下这个表达式是干什么的!!

AbstractAutowireCapableBeanFactory.getEarlyBeanReference 该方法在属性赋值之前、初始化之前执行
重点,该方法说白了就是会判断该Bean是否需要被动态代理,两种返回结果:
不需要代理,返回未属性注入、未初始化的半成品Bean
需要代理,返回未属性注入、未初始化的半成品Bean的代理对象
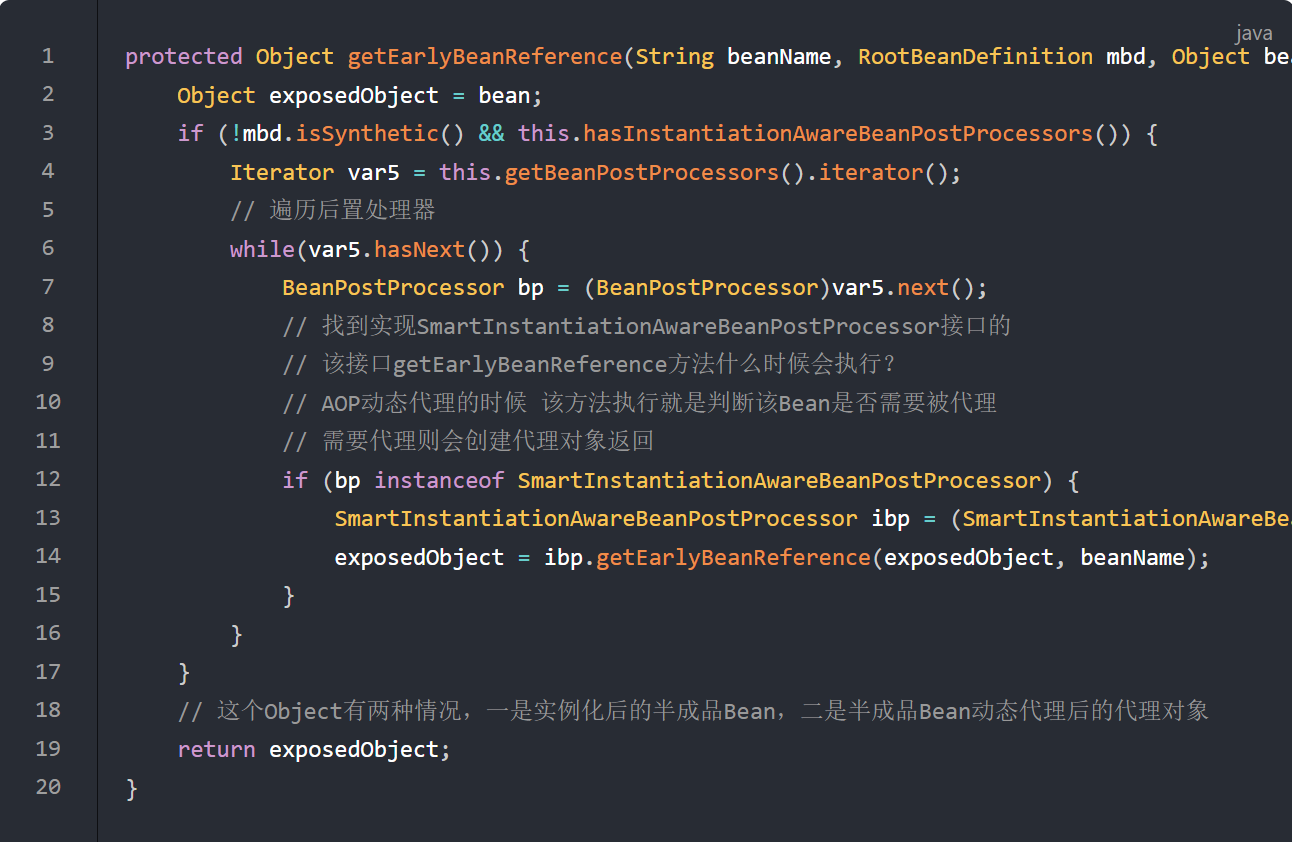
注意:这里只是把lambda表达式放入了三级缓存,如果不从三级缓存中获取,这个表达式是不执行的,一旦执行了,就会把半成品Bean 或 者半成品Bean的代理对象放入二级缓存中了
3、初始化后
AbstractBeanFactory.doGetBean
执行流程,sharedInstance = getSingleton(beanName, new ObjectFactory() --> singletonObject = singletonFactory.getObject() --> createBean方法 --> 又返回到singletonObject = singletonFactory.getObject()
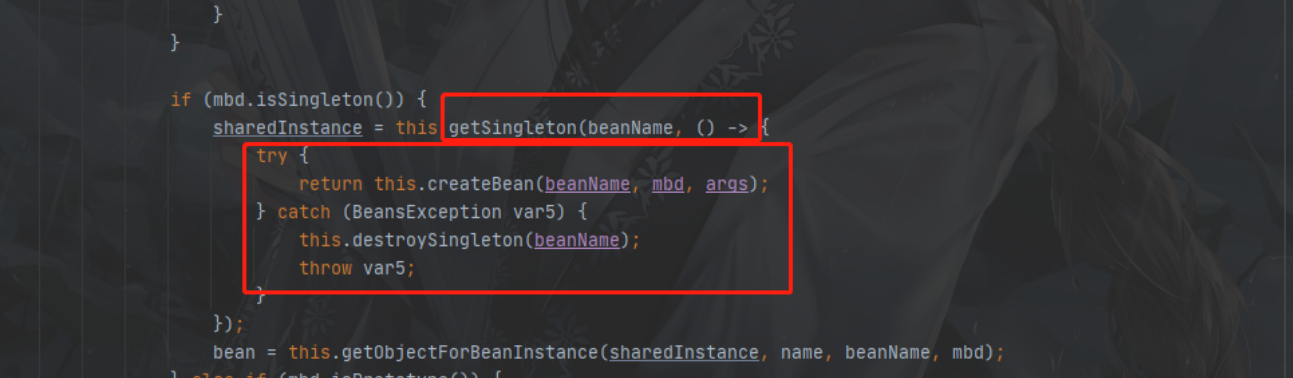
DefaultSingletonBeanRegistry.getSingleton(beanName, singletonFactory)
这个方法与上面那个不一样,重载了

DefaultSingletonBeanRegistry.addSingleton

总结
整个过程就三个地方跟缓存有关,我们假设现在要实例化A这个Bean,看看缓存是怎么变化的:
1、实例化前,获取缓存判断(三个缓存中肯定没有A,获取为null,进入实例化流程)
2、实例化完成,属性注入前(往三级缓存中放入了一个lambda表达式,一、二级为null)
3、初始化完成(将A这个Bean放入一级缓存,清除二、三级缓存)
以上则是单个Bean生成过程中缓存的变化!!
三、怎么解决的循环依赖
上面我们把Bean流程中利用缓存的三个重要的点都找出来了,也分析了会带来什么变化,接下来看看是怎么解决的循环依赖,我们看个图就懂了:
以A注入B,B注入A为例:
A属性注入前就把lambda表达式放入了第三级缓存,所以B再注入A的时候会从第三级缓存中找到A的lambda表达式并执行,然后将半成品Bean放入第二级缓存,所以此时B注入的只是半成品的A对象,然后B将完整对象返回给A注入,A继续初始化,完成创建。
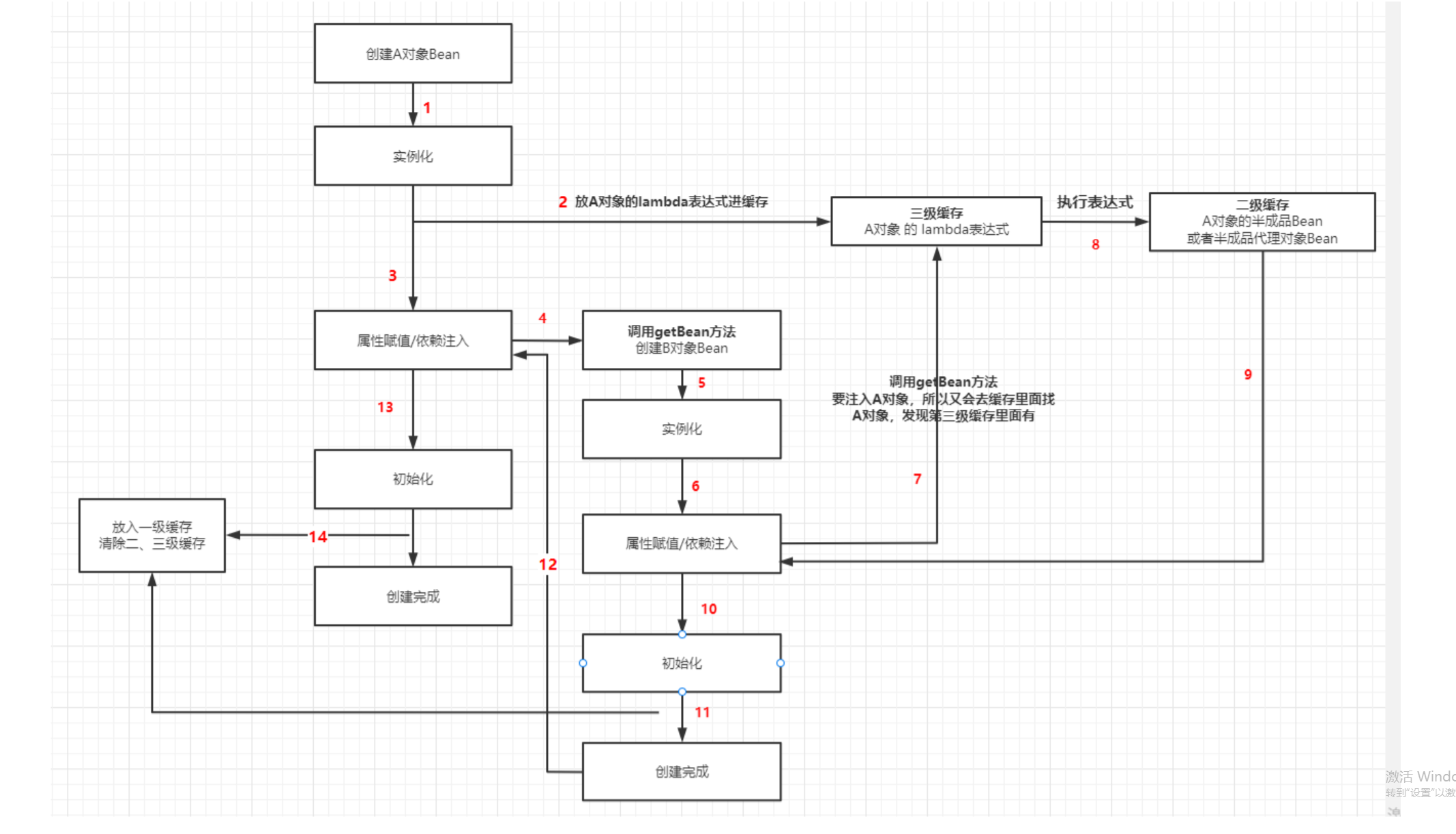
从上述看第三级缓存是用来提前暴露Bean对象引用的,所以解决了循环依赖,但是第二级缓存的这个半成品Bean对象干嘛的呢 ?
假设A同时注入了B和C,B和C又都注入了A,这时A注入B,实例化B的过程和上述是一样的,但随后还会注入C,那这个C在注入A的时候还会有第三级缓存用吗?没了吧,所以它就只能用第二级缓存的半成品Bean对象了,同样也是引用而已
四、不用三级缓存不行吗
可能很多小伙伴得到的答案就是不行,而且答案是因为不确定这个Bean是不是代理对象,所以搞了个lambda表达式?答案真的是这样吗 ?
那为什么要设计成三级缓存,而不是两级呢?比如说,如果只有二级缓存的话,可能会有什么问题?可能和AOP代理有关。因为如果Bean被AOP代理,那么在生成代理对象的时候,需要确保在注入的时候使用的是最终的代理对象。三级缓存中的工厂可以处理这种情况,根据需要返回原始对象或者代理对象,而二级缓存可能无法处理这种情况,导致多次代理 或者 代理不一致的问题。
示例1
比如,当Bean A被AOP代理时,在创建A的原始对象后,会有一个工厂放入三级缓存。当其他Bean B需要引用A时,会通过这个工厂获取代理对象,然后将这个代理对象放到二级缓存中。这样后续再需要A的时候,可以直接从二级缓存拿到代理对象,而不用再通过工厂创建,保证单例。如果没有三级缓存,只有二级的话,可能在处理代理对象的时候会遇到问题,比如多次调用工厂或者无法正确生成代理。
另外,三级缓存的存在可能还涉及到性能优化。比如,避免在不需要的时候过早地创建代理对象,只有在有循环依赖的情况下才会通过工厂来生成代理,这样在无循环依赖的情况下,可以延迟代理的创建,提高效率。
不过,可能有些情况下二级缓存也可以解决循环依赖的问题,但为什么Spring选择了三级呢?比如,假设只有一级和二级缓存,当Bean A创建时,实例化后放到二级缓存,然后填充属性时发现需要Bean B。Bean B在创建时同样需要Bean A,这时候从二级缓存拿到A的早期对象,完成B的创建,然后A继续填充。这样看起来可能可以解决循环依赖。但问题在于,如果A需要被代理的话,这时候在二级缓存中的A可能还是原始对象,而不是代理后的对象。而Spring的AOP通常是在Bean初始化后处理的,比如通过BeanPostProcessor。这时候,如果在填充属性的时候引用了原始对象,但最终Bean却是代理对象,就会导致不一致,因为其他Bean引用的可能是原始对象,而不是代理后的,这样AOP的增强就会失效。
所以,为了解决这个问题,Spring引入了三级缓存,在需要提前暴露Bean的时候,不是直接暴露实例,而是通过一个工厂来生成。这个工厂可以处理需要代理的情况,返回代理后的对象。这样,当存在循环依赖时,通过三级缓存中的工厂,可以生成正确的代理对象,并将其放入二级缓存,后续直接从二级缓存获取,而不用每次都通过工厂创建,同时保证所有依赖方都使用同一个代理对象。
总结一下,三级缓存主要是为了解决循环依赖中存在的代理问题,确保即使存在AOP代理,也能正确地处理依赖注入,避免出现不一致的引用。而二级缓存可能无法处理这种情况,导致代理对象被多次创建或引用的对象不正确。因此,Spring设计三级缓存是为了更细粒度地控制Bean的创建过程,处理各种复杂的依赖场景,尤其是涉及AOP的情况。

五、总结
一级缓存:用于存储被完整创建了的bean。也就是完成了初始化之后,可以直接被其他对象使用的bean。
二级缓存:用于存储半成品的Bean。也就是刚实例化但是还没有进行初始化的Bean
三级缓存:三级缓存存储的是工厂对象(lambda表达式)。工厂对象可以产生Bean对象提前暴露的引用(半成品的Bean或者半成品的代理Bean对象),执行这个lambda表达式,就会将引用放入二级缓存中
经过以上的分析,现在应该懂了吧:
循环依赖是否一定需要三级缓存来解决? 不一定,但三级缓存会更合适,风险更小
二级缓存能否解决循环依赖? 可以,但风险比三级缓存更大
第二级缓存用来干嘛的? 存放半成品的引用,可能产生多对象循环依赖,第三级缓存产生引用后,后续的就可以直接注入该引用
多例、构造器注入为什么不能解决循环依赖 ?
1、多例(Prototype)Bean为何无法解决循环依赖?
核心原因:作用域的生命周期不同
单例Bean的缓存机制:
Spring通过三级缓存(singletonObjects、earlySingletonObjects、singletonFactories)管理单例Bean的创建过程,提前暴露未完全初始化的Bean实例,以解决循环依赖
多例Bean的特性:
Prototype作用域的Bean每次请求都会创建一个新实例,Spring不缓存多例Bean的实例,因此无法在创建过程中提前暴露一个“半成品”Bean供其他对象使用。
具体场景示例

问题:当尝试获取Bean A或B时,Spring会尝试为每个Bean创建一个新实例,但由于它们相互依赖,每次创建都需要另一个Bean的新实例,导致无限递归,最终抛出 BeanCurrentlyInCreationException
2、构造器注入为何无法解决循环依赖 ?
核心原因:实例化与依赖注入的顺序冲突
构造器注入的时机:
构造器注入发生在Bean的实例化阶段,此时Bean还未完成初始化,无法通过提前暴露引用(如三级缓存)解决循环依赖
属性注入(Setter注入)的时机:
属性注入发生在Bean实例化之后,此时Spring可以通过三级缓存提前暴露一个未完成属性填充的Bean,供其他对象引用
具体场景示例
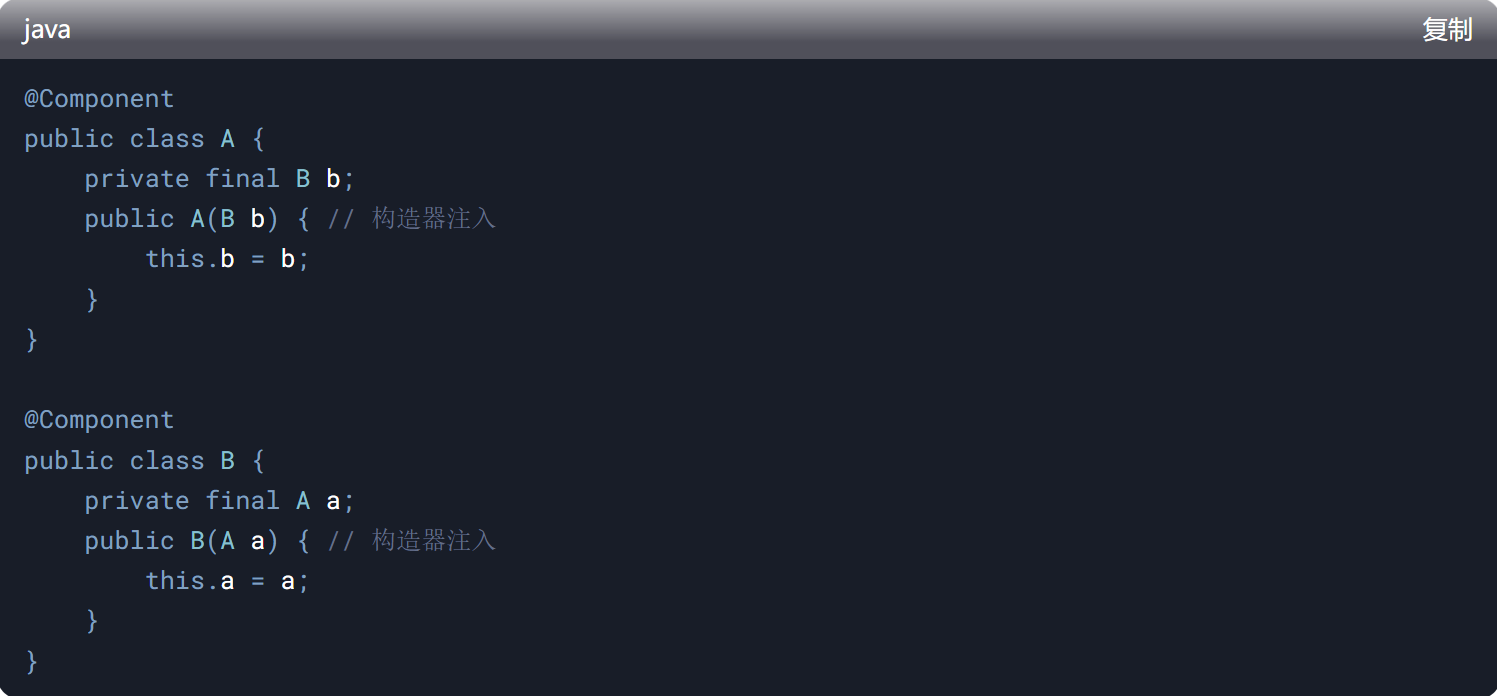
问题:创建Bean A时,需要先实例化Bean B;而实例化Bean B时,又需要先实例化Bean A。两者互相等待对方完成实例化,导致死锁,最终抛出 BeanCurrentlyInCreationException
Spring的三级缓存详解的更多相关文章
- Spring框架系列(8) - Spring IOC实现原理详解之Bean实例化(生命周期,循环依赖等)
上文,我们看了IOC设计要点和设计结构:以及Spring如何实现将资源配置(以xml配置为例)通过加载,解析,生成BeanDefination并注册到IoC容器中的:容器中存放的是Bean的定义即Be ...
- Spring Data操作Redis详解
Spring Data操作Redis详解 Redis是一种NOSQL数据库,Key-Value形式对数据进行存储,其中数据可以以内存形式存在,也可以持久化到文件系统.Spring data对Redis ...
- Spring各个jar包详解
Spring各jar包详解 spring.jar 是包含有完整发布模块的单个jar 包.但是不包括mock.jar,aspects.jar, spring-portlet.jar, and sprin ...
- Spring Boot 之 Redis详解
Redis是目前业界使用最广泛的内存数据存储. Redis支持丰富的数据结构,同时支持数据持久化. Redis还提供一些类数据库的特性,比如事务,HA,主从库. REmote DIctionary S ...
- Spring IoC @Autowired 注解详解
前言 本系列全部基于 Spring 5.2.2.BUILD-SNAPSHOT 版本.因为 Spring 整个体系太过于庞大,所以只会进行关键部分的源码解析. 我们平时使用 Spring 时,想要 依赖 ...
- Spring IoC 公共注解详解
前言 本系列全部基于 Spring 5.2.2.BUILD-SNAPSHOT 版本.因为 Spring 整个体系太过于庞大,所以只会进行关键部分的源码解析. 什么是公共注解?公共注解就是常见的Java ...
- Spring框架系列(6) - Spring IOC实现原理详解之IOC体系结构设计
在对IoC有了初步的认知后,我们开始对IOC的实现原理进行深入理解.本文将帮助你站在设计者的角度去看IOC最顶层的结构设计.@pdai Spring框架系列(6) - Spring IOC实现原理详解 ...
- Spring框架系列(7) - Spring IOC实现原理详解之IOC初始化流程
上文,我们看了IOC设计要点和设计结构:紧接着这篇,我们可以看下源码的实现了:Spring如何实现将资源配置(以xml配置为例)通过加载,解析,生成BeanDefination并注册到IoC容器中的. ...
- Spring框架系列(9) - Spring AOP实现原理详解之AOP切面的实现
前文,我们分析了Spring IOC的初始化过程和Bean的生命周期等,而Spring AOP也是基于IOC的Bean加载来实现的.本文主要介绍Spring AOP原理解析的切面实现过程(将切面类的所 ...
- elasticSearch+spring 整合 maven依赖详解
摘自:http://www.mayou18.com/detail/nTxPQSyu.html [Elasticsearch基础]elasticSearch+spring 整合 maven依赖详解 Ma ...
随机推荐
- Nibbles PG walkthrough Intermediate
nmap nmap -p- -A 192.168.239.47 Starting Nmap 7.95 ( https://nmap.org ) at 2025-01-15 02:26 UTC Nmap ...
- BackupBuddy pg walkthrough Intermediate
nmap ┌──(root㉿kali)-[~/lab] └─# nmap -p- -A 192.168.189.43 Starting Nmap 7.94SVN ( https://nmap.org ...
- 闲话 4.12——对 Worpitzky 恒等式的几个证明
\[\sum_{i}\left\langle\begin{matrix}n\\i\end{matrix}\right\rangle \binom{i+k}{n}=k^n \] 通俗的证明(具体数学的习 ...
- 还堵在高速路上吗?带你进入Scratch世界带你飞
国庆假期高速路的风景 国庆假期正式启动人从众模式,无论是高速公路还是景区,不管是去程还是回程,每一次都堪称经典. 一些网友在经历漫长的拥堵后 哭笑不得地表示 "假期都在堵车中度过了" ...
- NLLB 与 ChatGPT 双向优化:探索翻译模型与语言模型在小语种应用的融合策略
作者:来自 vivo 互联网算法团队- Huang Minghui 本文探讨了 NLLB 翻译模型与 ChatGPT 在小语种应用中的双向优化策略.首先介绍了 NLLB-200 的背景.数据.分词器和 ...
- 【忍者算法】从拉链到链表:探索有序链表的合并之道|LeetCode 21 合并两个有序链表
从拉链到链表:探索有序链表的合并之道 生活中的合并 想象你正在整理两叠按日期排好序的收据.最自然的方式就是:拿起两叠收据,每次比较最上面的日期,选择日期较早的那张放入新的一叠中.这个简单的日常操作,恰 ...
- Kali Linux(202104)重置root账户密码
1.前言 如果忘记了Kali Linux系统的登录密码,最关键的需求就是重置root用户的登录密码, 之后使用root账户可以修改其他账户的密码. 因此, 本文就介绍一下在不知道root用户登录密码的 ...
- 全程不用写代码,我用AI程序员写了一个飞机大战
前言 还在为写代码薅头发吗?还在为给出的需求无处下手而发愁吗?今天宏哥分享一款开发工具的插件,让你以后的编程变得简单起来. 作为一个游戏编程小白,能完成自己工作就不错了,还能玩别的,这在以前想都不敢想 ...
- php解析url并得到url中的参数及获取url参数的四种方式
https://www.jb51.net/article/73900.htm 下面通过四种实例给大家介绍php url 参数获取方式. 在已知URL参数的情况下,我们可以根据自身情况采用$_GET来获 ...
- 在OCI上快速静默安装23ai数据库
拿到同事帮忙申请好的OCI环境[OEL 8.10]后,开始安装23ai数据库用于后续测试,本文选择快速静默安装模式. OCI环境都是opc用户登录的,执行高权限的操作均需要用到sudo命令. 首先创建 ...