Flink学习(四) Flink Table & SQL 实现wordcount Java版本
Flink Table & SQL WordCount
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
一个完整的 Flink SQL 编写的程序包括如下三部分。
Source Operator:是对外部数据源的抽象, 目前 Apache Flink 内置了很多常用的数据源实现,比如 MySQL、Kafka 等。
Transformation Operators:算子操作主要完成比如查询、聚合操作等,目前 Flink SQL 支持了 Union、Join、Projection、Difference、Intersection 及 window 等大多数传统数据库支持的操作。
Sink Operator:是对外结果表的抽象,目前 Apache Flink 也内置了很多常用的结果表的抽象,比如 Kafka Sink 等。
我们也是通过用一个最经典的 WordCount 程序作为入门,上面已经通过 DataSet/DataStream API 开发,那么实现同样的 WordCount 功能, Flink Table & SQL 核心只需要一行代码:
//省略掉初始化环境等公共代码
SELECT word, COUNT(word) FROM table GROUP BY word;
首先,整个工程中我们 pom 中的依赖如下图所示:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.10.0</version>
</dependency>
第一步,创建上下文环境:
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
第二步,读取一行模拟数据作为输入:
String words = "hello flink hello lagou";
String[] split = words.split("\\W+");
ArrayList<WC> list = new ArrayList<>(); for(String word : split){
WC wc = new WC(word,1);
list.add(wc);
}
DataSet<WC> input = fbEnv.fromCollection(list);
第三步,注册成表,执行 SQL,然后输出:
//DataSet 转sql, 指定字段名
Table table = fbTableEnv.fromDataSet(input, "word,frequency");
table.printSchema(); //注册为一个表
fbTableEnv.createTemporaryView("WordCount", table); Table table02 = fbTableEnv.sqlQuery("select word as word, sum(frequency) as frequency from WordCount GROUP BY word"); //将表转换DataSet
DataSet<WC> ds3 = fbTableEnv.toDataSet(table02, WC.class);
ds3.printToErr();
整体代码结构如下:
package wyh.tableApi;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.BatchTableEnvironment;
import java.util.ArrayList;
public class WCTableApi {
public static void main(String[] args) {
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
String words="hello flink hello shujia";
String[] split = words.split("\\W+");
ArrayList<WC> list = new ArrayList<>();
for (String word : split) {
WC wc = new WC(word, 1L);
list.add(wc);
}
// DataSet<WC> input = fbEnv.fromCollection(list);
DataSource<WC> input = fbEnv.fromCollection(list);
Table table = fbTableEnv.fromDataSet(input, "word,frequency");
table.printSchema();
fbTableEnv.createTemporaryView("wordcount",table);
Table table1 = fbTableEnv.sqlQuery("select word,sum(frequency) as frequency from wordcount group by word");
DataSet<WC> ds3 = fbTableEnv.toDataSet(table1, WC.class);
try {
ds3.printToErr();
} catch (Exception e) {
e.printStackTrace();
}
}
public static class WC{
public String word;
public Long frequency;
public WC() {
}
public WC(String word, Long frequency) {
this.word = word;
this.frequency = frequency;
}
@Override
public String toString() {
return "WC{" +
"word='" + word + '\'' +
", frequency=" + frequency +
'}';
}
}
}
我们直接运行该程序,在控制台可以看到输出结果:
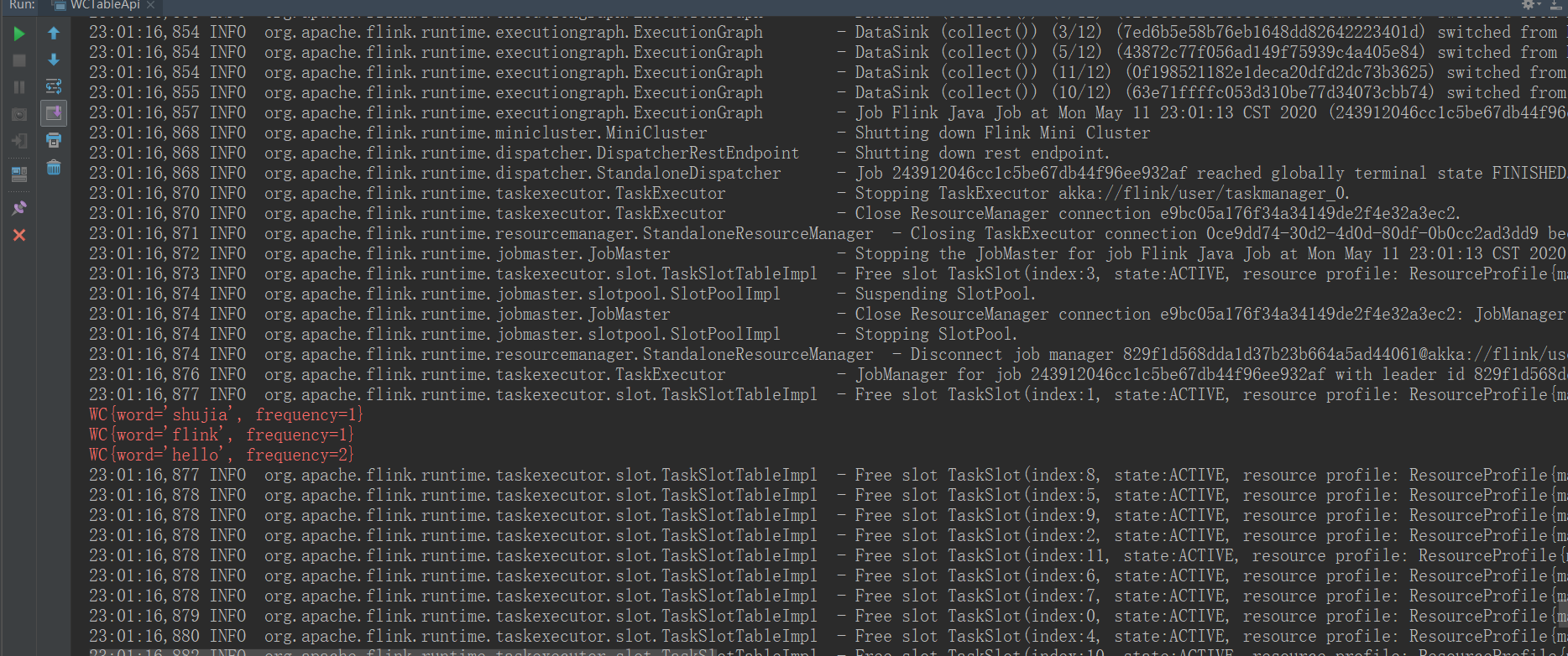
Flink学习(四) Flink Table & SQL 实现wordcount Java版本的更多相关文章
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-flink实战
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink table&Sql中使用Calcite
Apache Calcite是什么东东 Apache Calcite面向Hadoop新的sql引擎,它提供了标准的SQL语言.多种查询优化和连接各种数据源的能力.除此之外,Calcite还提供了OLA ...
- 使用flink Table &Sql api来构建批量和流式应用(1)Table的基本概念
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- 使用flink Table &Sql api来构建批量和流式应用(2)Table API概述
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- 使用flink Table &Sql api来构建批量和流式应用(3)Flink Sql 使用
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- flink学习笔记-快速生成Flink项目
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- flink学习笔记-各种Time
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- 《从0到1学习Flink》—— Apache Flink 介绍
前言 Flink 是一种流式计算框架,为什么我会接触到 Flink 呢?因为我目前在负责的是监控平台的告警部分,负责采集到的监控数据会直接往 kafka 里塞,然后告警这边需要从 kafka topi ...
随机推荐
- 打破格式壁垒 !COS助力腾讯文档优化在线预览效果
说起腾讯文档,相信大家对此并不陌生.在新冠疫情防控期间,腾讯文档在人员流动排查.健康信息收集.居家学习.协同办公等场景发挥了巨大的作用. 腾讯文档不仅支持新建word.excel.ppt.思维导图.流 ...
- bouncycastle(BC) 实现SM2国密加解密、签名、验签
https://www.cnblogs.com/dashou/p/14656458.html SM2国密加解密一个类就够了 <dependency> <groupId>org. ...
- lottie-web动画库在HTML5页面中和在vue项目中的两种使用方式
本文主要介绍lottie-web动画库在HTML5页面中和在vue项目中的两种使用方式. 1.在HTML5页面中的使用方式 具体使用步骤详见下面的代码: <!DOCTYPE html> & ...
- 即时通讯框架MobileIMSDK的H5端开发快速入门
► 相关链接: ① MobileIMSDK-H5端的详细介绍 ② MobileIMSDK-H5端的开发手册new(* 精编PDF版) 一.技术准备 您是否已对Web端即时通讯技术有所了解? 1)新手入 ...
- SpringCloud-Ribbon
1. Ribbon简介 Ribbon是一个基于HTTP和TCP的客户端负载均衡器,当使用Ribbon对服务进行访问的时候,他会扩展Eureka客户端的服务发现功能,实现从Eureka注册中心获取服务端 ...
- UWP ManipulationStarted 移动图片或控件不要滑出父容器的判断
假设自定义一个用户控件用以在父容器Grid里拖动/移动: <UserControl x:Class="App6.Pic" xmlns="http://schemas ...
- linux-杂项
1.常用基础 防火墙systemctl status firewalldsystemctl stop firewalldsystemctl start firewalld find / -size + ...
- Jdk8新特性目录总结
--------------------------------------- Lambda表达式 接口新增方法 四大函数式接口 方法引用 Stream(1) Stream(2) Stream(3) ...
- 二叉树神级遍历算法:morris遍历算法
morris遍历的实质 建立一种机制,对于没有左子树的节点只到达一次,对于有左子树的节点会到达两次 morris遍历的实现原则 记作当前节点为cur. 如果cur无左孩子,cur向右移动(cur=cu ...
- 060_面向过程和面向对象区别 061_对象是什么_对象和数据管理 062_对象和类的关系_属性_成员变量_方法 063_一个典型类的写法和调用_类的UML图入门 064_内存分析详解_栈_堆_方法区_栈帧_程序执行的内存变化过程
060_面向过程和面向对象区别 061_对象是什么_对象和数据管理 062_对象和类的关系_属性_成员变量_方法 public class SxtStu {//定义了一个类,包含的成员变量,属性,方法 ...