使用Go复刻skiplist核心功能
0、引言
正好做LC每日一题要求实现一个跳表,于是学习了redis的扩展skiplist,并使用Go进行复刻学习。学习参考了文章:Redis内部数据结构详解(6)——skiplist - 铁蕾的个人博客
因为作者能力有限,本文只是对跳表的核心功能:创建节点与跳表、插入节点、删除节点、获取节点rank、根据rank获取节点、获取分数区间的ele集合进行复刻,其余的需要自己去实现。
1、跳表核心结构
源码的数据结构定义如下:
#define ZSKIPLIST_MAXLEVEL 32
#define ZSKIPLIST_P 0.25
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
- 定义了两个常量,一个是跳表的最大层数
ZSKIPLIST_MAXLEVEL,一个是当前节点含有i+1层的概率ZSKIPLIST_P - 跳表节点
zskiplistNode:ele,为string类型,存放的是节点的数据score,存放数据对应的值backward指向前一个跳表节点,只存在第一层链接中level存放多层指向下一个节点的指针forawrd,同时含有一个span用于表示当前指针跨越了多少个节点,用于实现通过排名查询。注意,span是表示当前层,从header到当前节点跨过的指针数,它不包括指针的起始节点,但是包括终点节点。
- 跳表本身
zskiplist:header和tail,指向跳表首尾的指针length跳表总节点数level跳表当前的层数
复刻:
package goskiplist
const (
SKIPLIST_MAXLEVEL = 32
SKIPLIST_P = 0.25
)
type GskiplistLevel struct {
forward *GskiplistNode
span uint64
}
type GskiplistNode struct {
ele string
score float64
backward *GskiplistNode
level []GskiplistLevel
}
type Gskiplist struct {
header *GskiplistNode
tail *GskiplistNode
length uint64
level int
}
2、创建跳表节点与跳表
创建跳表节点源码:
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}
复刻:
func createNode(level int, score float64, ele string) *GskiplistNode{
node := &GskiplistNode{
ele: ele,
score: score,
level: make([]GskiplistLevel, level),
backward: nil,
}
return node
}
创建跳表源码:
/* Create a new skiplist. */
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
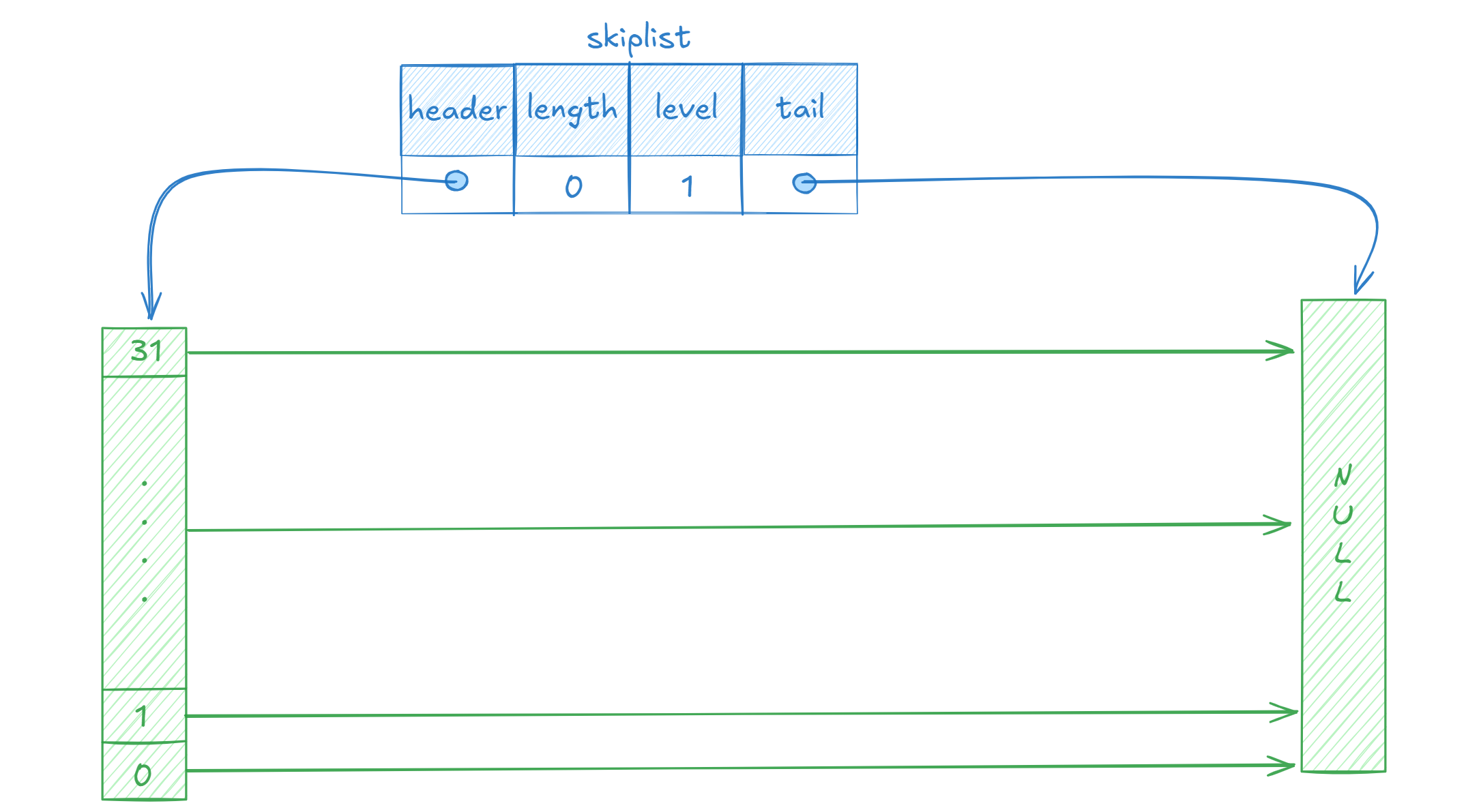
初始化设置了跳表的层数为1、节点数为0、初始化头节点指针,分配内存。注意,头节点并不计算在length中。
经过初始化,创建的跳表如下:
3、向跳表插入节点
源码:
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned long rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
zslInsert主要实现了向跳表中插入一个节点,节点的值为ele,分数为score。
解析:
(1)创建数组与断言检查
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned long rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
*update[]用于记录每一层插入的位置,update[i]表示节点在第i层,应该插入在update[i]节点之后。rank[]用于记录每一层的跨度,rank[i]表示从第i层,跳到update[i]节点的跨度。使用了前缀和的思想。*x用于节点的遍历serverAssert用于判断数值是否异常
(2)查找插入位置
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
i从当前跳表的最高层向下遍历。在每一次遍历中:
- rank[i]初始赋值上一层的结果,若为最高层则赋值0
- 若当前层的当前节点存在下一节点,并且分数<新节点分数(从小到大排序)或者分数相同但字典序要小,则累加下一步的跨度,并且移动结点至下一结点。
- 找到当前层应该插入的位置后,记录这个结点。
加入目前跳表结构如下:
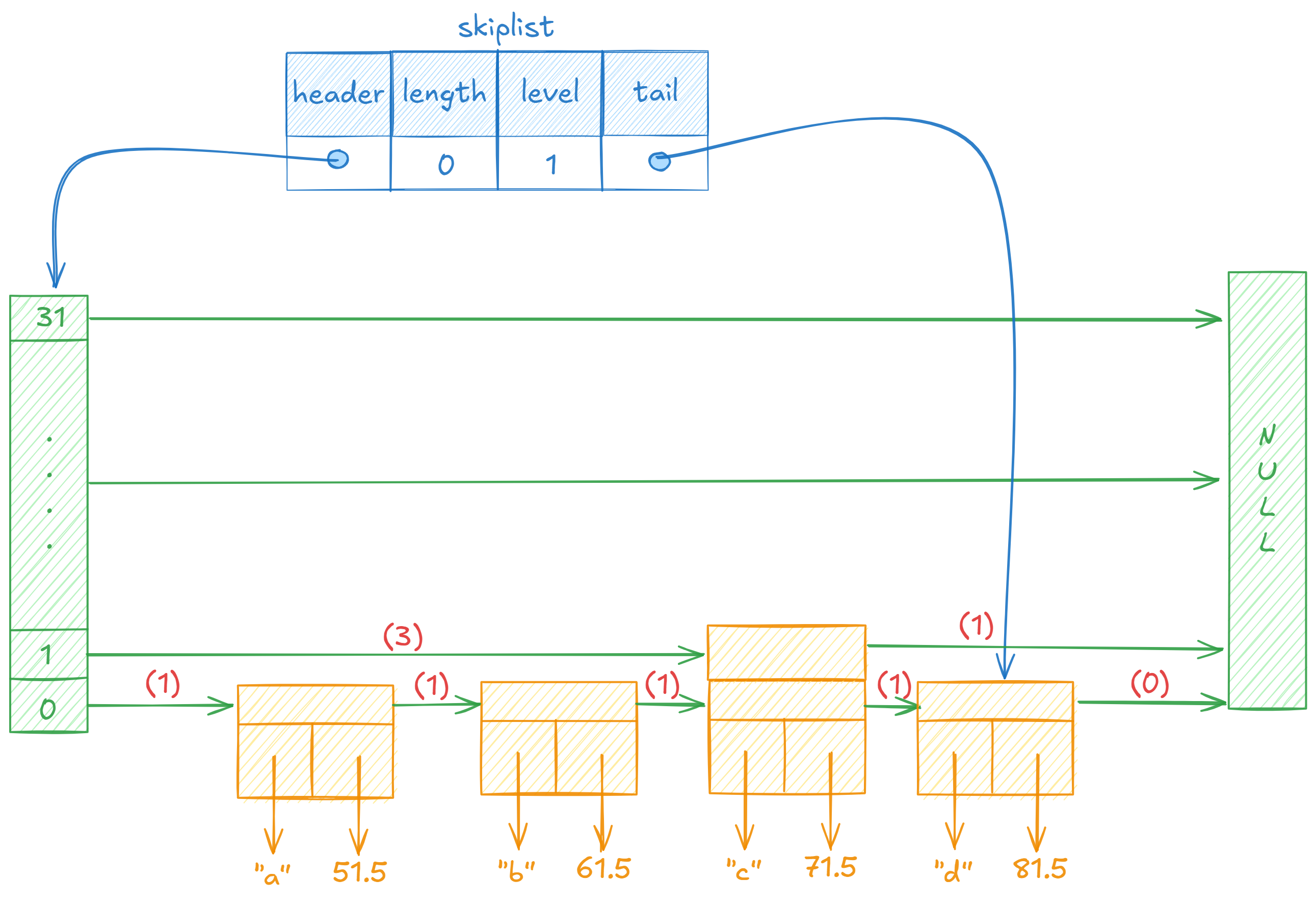
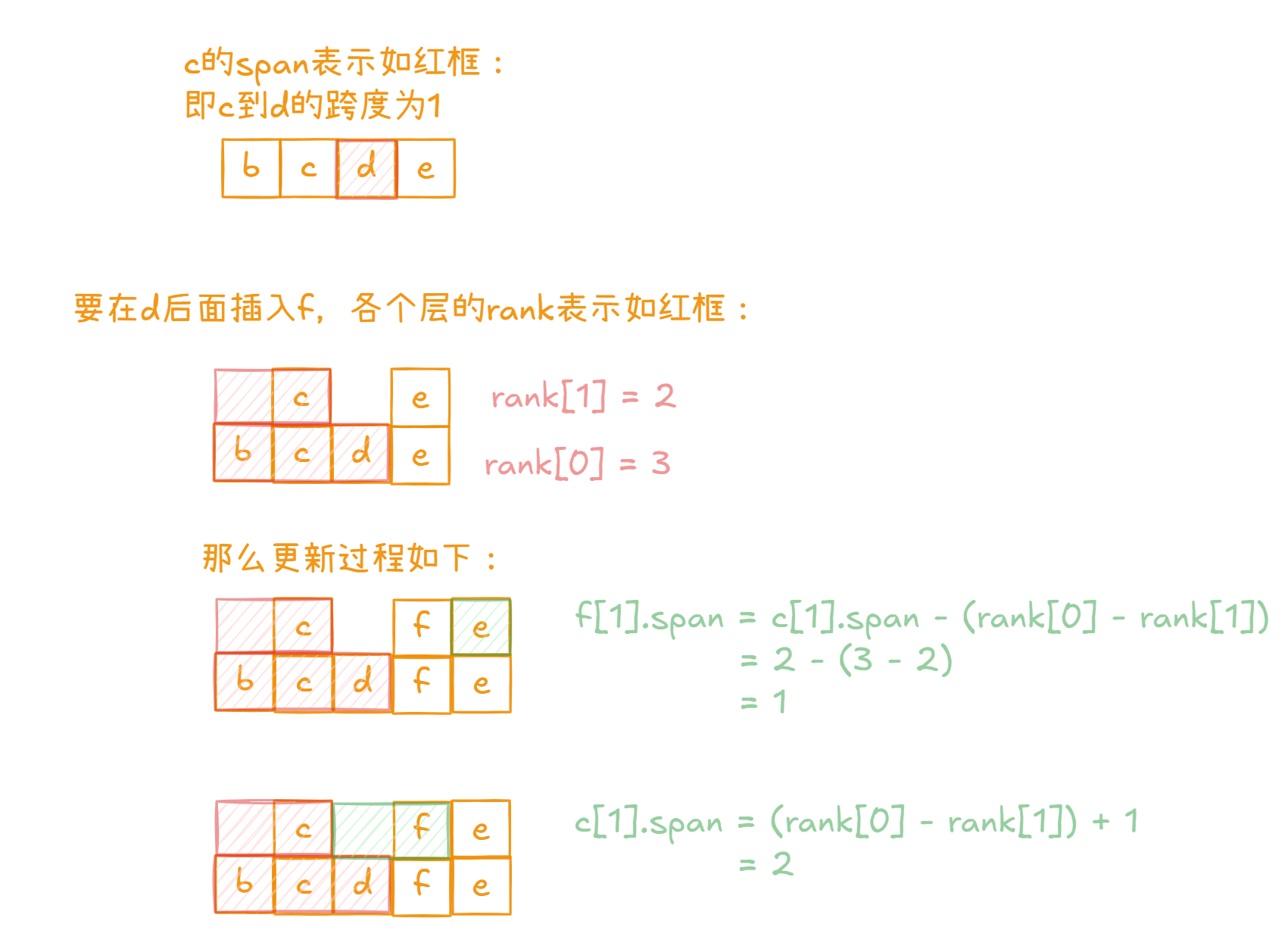
我们想要插入的新节点ele为“e”,score为“75”。那么经过更新后:
- rank[1] = 3,update[1] = c
- rank[0] = 3,update[0] = c
(3)设定新节点最大层数
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
使用zslRandomLevel函数设定新节点的最高层数。如果这个最高层数大于目前跳表的层数,那么就需要设定新高层的rank和update。
zslRandomLevel的实现如下:
int zslRandomLevel(void) {
static const int threshold = ZSKIPLIST_P*RAND_MAX;
int level = 1;
while (random() < threshold)
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
通过将浮点数映射至整数,可以加快运算效率。
假设我们要插入的(“e”,75)节点生成的层数为3,经历上述操作后,跳表结构如下:
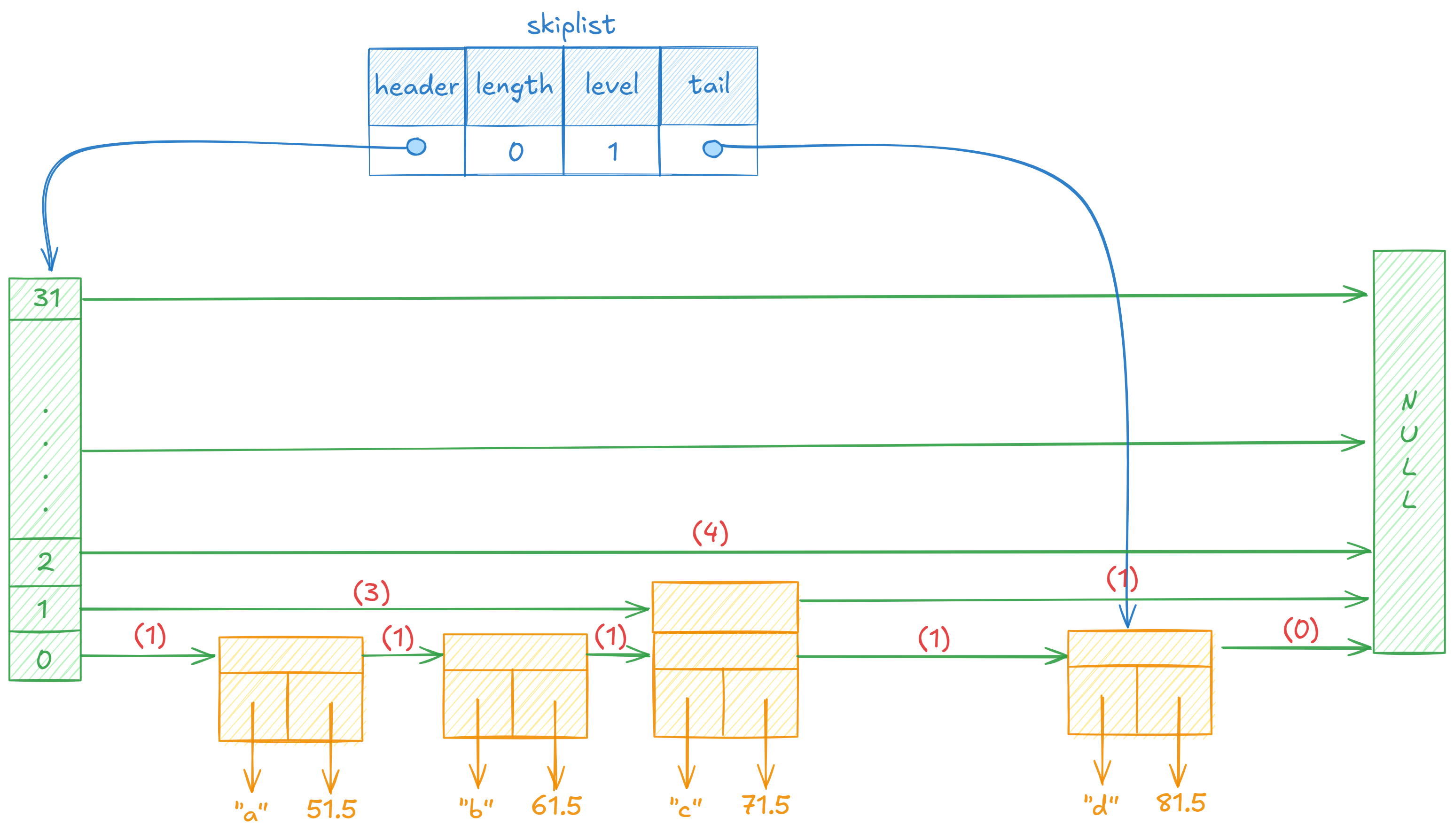
(4)插入新节点和更新跨度
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
调整每一层的要插入的位置的前一个节点的指针指向,并且更新span。
假设在第i层,我们称update[i]为pre,未更新前pre的下一个节点未next,那么因为要在pre和next之间插入新的节点,更新pre的span为pre到next的距离-cur到next的距离。更新cur的span为cur到next的距离。
第二个循环是为了更新当前节点的更高层未更新节点的span值。
经过这一次调整,如图:
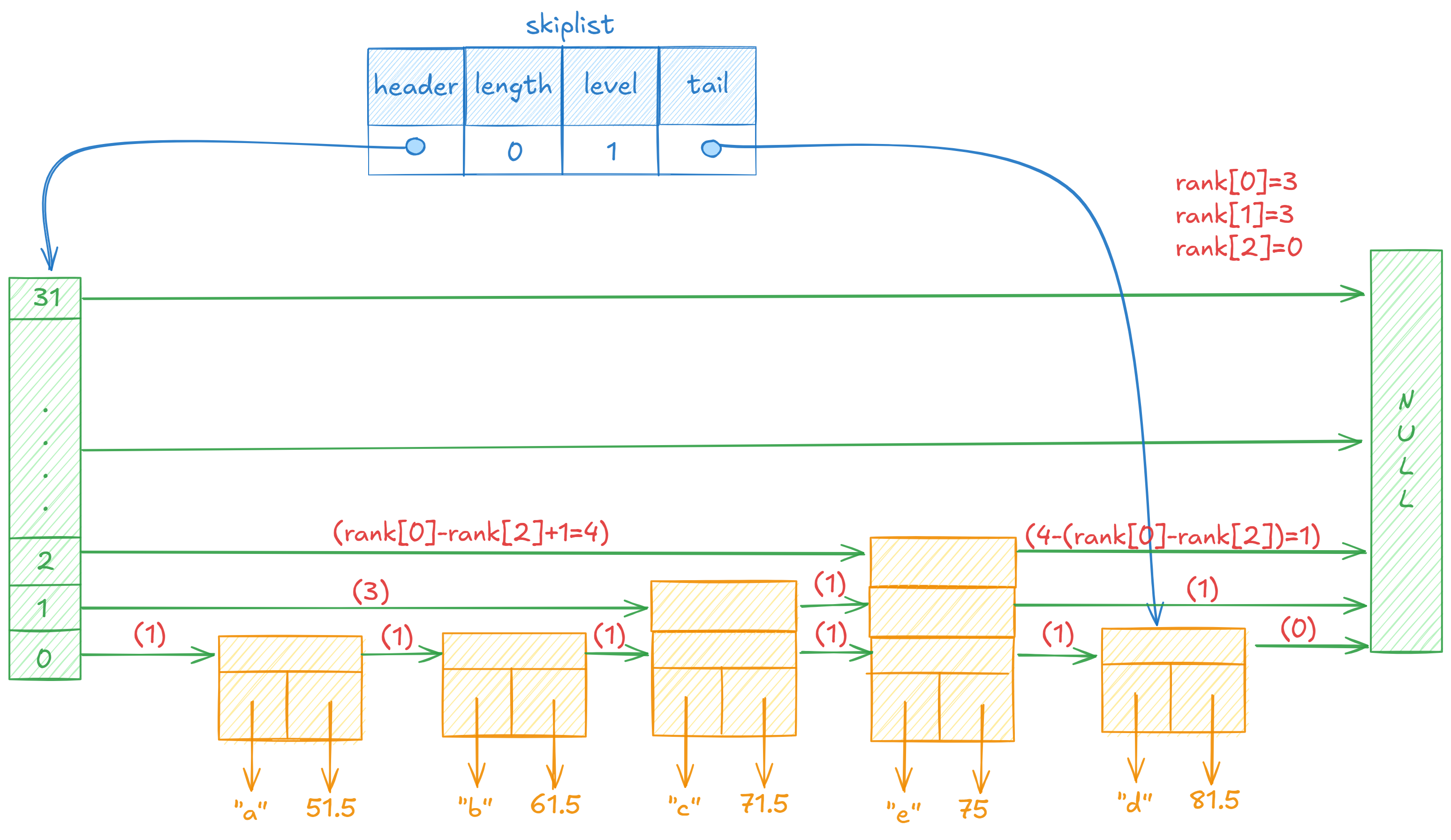
这里我画图用于形象的表示span的计算过程,它采用了前缀和的方式:
(5)更新新节点的前指针
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
如果update[0]不是头节点,那么它就是x的前一个节点。如果x的后节点存在,则更新x的后节点的前指针指向x,否则x是末尾节点,让tail指向它。
复刻Go源码:
// 向跳表插入一个节点,同时返回插入好的节点。
// ele不能为空串,否则返回nil。
func (this *Gskiplist) Insert(score float64, ele string) *GskiplistNode {
if ele == "" {
return nil
}
update := make([]*GskiplistNode, SKIPLIST_MAXLEVEL)
rank := make([]uint64, SKIPLIST_MAXLEVEL)
var x *GskiplistNode
x = this.header
//更新update以及rank
for i := this.level - 1; i >= 0; i-- {
rank[i] = 0
if i != this.level-1 {
rank[i] = rank[i+1]
}
for x.level[i].forward != nil &&
(x.level[i].forward.score < score ||
(x.level[i].forward.score == score && x.level[i].forward.ele < ele)) {
rank[i] += x.level[i].span
x = x.level[i].forward
}
update[i] = x
}
level := this.randomLevel()
//更新最大层数
if level > this.level {
for i := this.level; i < level; i++ {
rank[i] = 0
update[i] = this.header
update[i].level[i].span = this.length
}
this.level = level
}
x = createNode(level, score, ele)
//插入操作
for i := 0; i < level; i++ {
x.level[i].forward = update[i].level[i].forward
update[i].level[i].forward = x
//更新x和前一个节点的span
x.level[i].span = update[i].level[i].span - (rank[0] - rank[i])
update[i].level[i].span = (rank[0] - rank[i]) + 1
}
//更新更高层
for i := level; i < this.level; i++ {
update[i].level[i].span++
}
//更新前节点指针指向
x.backward = nil
if update[0] != this.header {
x.backward = update[0]
}
if x.level[0].forward != nil {
x.level[0].forward.backward = x
} else {
this.tail = x
}
this.length++
return x
}
4、删除跳表节点
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
}
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
zslDeleteNode(zsl, x, update);
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}
先来看zslDelete:它是删除节点的最上层,update的更新方法与插入一致。接着就是删除score和ele相同的节点,其中node参数用于提供保存删除节点的作用。在Go语言的复刻中,我们可以直接返回node和是否删除成功。
再看zslDeleteNode,它是删除节点的下游具体实现,具体细节如下:
- 逐层删除x,如果当前层有x,则需要将前一个节点的后指针指向x的后指针,然后更新前一个节点的span;否则只用更新span
- 如果x的后节点存在,则更新后节点的backward指针,否则修改跳表的tail。
- 如果存在高层,在删除x后为空层,要修改跳表的层数。
- 减去一个length
Go复刻如下:
//删除节点,返回这个节点以及是否成功
func (this *Gskiplist) Delete(score float64, ele string) (*GskiplistNode, bool) {
update := make([]*GskiplistNode, SKIPLIST_MAXLEVEL)
var x *GskiplistNode
x = this.header
for i := this.level - 1; i >= 0; i-- {
for x.level[i].forward != nil &&
(x.level[i].forward.score < score ||
(x.level[i].forward.score == score && x.level[i].forward.ele < ele)) {
x = x.level[i].forward
}
update[i] = x
}
x = x.level[0].forward
//从底层删除
if x != nil && x.score == score && x.ele == ele {
this.deleteNode(x, update)
return x, true
}
//未找到对应节点
return nil, false
}
func (this *Gskiplist) deleteNode(x *GskiplistNode, update []*GskiplistNode) {
for i := 0; i < this.level; i++ {
if update[i].level[i].forward == x {
//在这一层,存在x
update[i].level[i].span += x.level[i].span - 1
update[i].level[i].forward = x.level[i].forward
} else {
//不存在则只更新span
update[i].level[i].span--
}
}
if x.level[0].forward != nil {
x.level[0].forward.backward = x.backward
} else {
this.tail = x.backward
}
//若x独占高层,需要逐个清除
for this.level > 1 && this.header.level[this.level-1].forward == nil {
this.level--
}
this.length--
}
5、获取节点的rank
unsigned long zslGetRank(zskiplist *zsl, double score, sds ele) {
zskiplistNode *x;
unsigned long rank = 0;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) <= 0))) {
rank += x->level[i].span;
x = x->level[i].forward;
}
/* x might be equal to zsl->header, so test if obj is non-NULL */
if (x->ele && x->score == score && sdscmp(x->ele,ele) == 0) {
return rank;
}
}
return 0;
}
从高层逐个寻找,找到即返回。
6、根据排名获取节点
/* Finds an element by its rank from start node. The rank argument needs to be 1-based. */
zskiplistNode *zslGetElementByRankFromNode(zskiplistNode *start_node, int start_level, unsigned long rank) {
zskiplistNode *x;
unsigned long traversed = 0;
int i;
x = start_node;
for (i = start_level; i >= 0; i--) {
while (x->level[i].forward && (traversed + x->level[i].span) <= rank)
{
traversed += x->level[i].span;
x = x->level[i].forward;
}
if (traversed == rank) {
return x;
}
}
return NULL;
}
/* Finds an element by its rank. The rank argument needs to be 1-based. */
zskiplistNode *zslGetElementByRank(zskiplist *zsl, unsigned long rank) {
return zslGetElementByRankFromNode(zsl->header, zsl->level - 1, rank);
}
Go复刻:
// 根据排名获取节点
func (this *Gskiplist) GetElementByRank(rank uint64) *GskiplistNode {
return this.getElementByRankFromNode(this.header, this.level-1, rank)
}
func (this *Gskiplist) getElementByRankFromNode(startNode *GskiplistNode, startLevel int, rank uint64) *GskiplistNode {
x := startNode
var traversed uint64
for i := startLevel; i >= 0; i-- {
for x.level[i].forward != nil && traversed+x.level[i].span <= rank {
traversed += x.level[i].span
x = x.level[i].forward
}
//遍历完一层,查看是否到达
if traversed == rank {
return x
}
}
return nil
}
7、根据分数区间获取数据集合
现在,我们能很轻易的实现根据分数区间获取数据集合的功能。
// 根据分数区间获取数据集合,返回数据的ele集合
func (this *Gskiplist) GetElementsRangeByScore(low float64, high float64) (ans []string) {
x := this.header
var i int
for i = this.level - 1; i >= 0; i-- {
for x.level[i].forward != nil && x.level[i].forward.score < low {
x = x.level[i].forward
}
}
x = x.level[0].forward
for x != nil && x.score <= high {
ans = append(ans, x.ele)
x = x.level[0].forward
}
return ans
}
到这里为止,对skiplist的核心功能就复刻完成了,剩余的根据需要可以自己探索。
使用Go复刻skiplist核心功能的更多相关文章
- Shiro 核心功能案例讲解 基于SpringBoot 有源码
Shiro 核心功能案例讲解 基于SpringBoot 有源码 从实战中学习Shiro的用法.本章使用SpringBoot快速搭建项目.整合SiteMesh框架布局页面.整合Shiro框架实现用身份认 ...
- 复刻smartbits的国产网络测试工具minismb简介
复刻smartbits的国产网络性能测试工具minismb,是一款专门用于测试智能路由器,网络交换机的性能和稳定性的软硬件相结合的工具.可以通过此工具测试任何ip网络设备的端口吞吐率,带 ...
- 复刻smartbits的国产网络测试工具minismb功能特点-如何加载、发送PCAP数据包
复刻smartbits的网络性能测试工具minismb,是一款专门用于测试智能路由器,网络交换机的性能和稳定性的软硬件相结合的工具.可以通过此以太网测试工具测试任何ip网络设备的端口吞吐率,带宽,并发 ...
- 复刻smartbits的国产网络测试工具minismb-如何测试协议限速
复刻smartbits的网络性能测试工具MiniSMB,是一款专门用于测试智能路由器,网络交换机的性能和稳定性的软硬件相结合的工具.可以通过此工具测试任何ip网络设备的端口吞吐率,带宽,并发连接数和最 ...
- 复刻smartbits的国产网络测试工具minismb-网络连接数测试方法
复刻smartbits的网路性能测试工具MiniSMB,是一款专门用于测试智能路由器,网络交换机的性能和稳定性的软硬件相结合的工具.可以通过此工具测试任何ip网络设备的端口吞吐率,带宽,并发连接数和最 ...
- 复刻smartbits的国产网络测试工具minismb-如何测试ip限速
复刻smartbits的网路性能测试工具MiniSMB,是一款专门用于测试智能路由器,网络交换机的性能和稳定性的软硬件相结合的工具.可以通过此工具测试任何ip网络设备的端口吞吐率,带宽,并发连接数和最 ...
- 161_可视化_Power BI 复刻 GitHub 贡献热力图
161_可视化_Power BI 复刻 GitHub 贡献热力图 一.背景 在 GitHub 上,有用户的贡献度的热力图如下: Power BI 公共 web 效果:https://demo.jiao ...
- 带连接池的netty客户端核心功能实现剖解
带连接池的netty客户端核心功能实现剖析 带连接池的netty的客户端核心功能实现剖析 本文为原创,转载请注明出处 源码地址: https://github.com/zhangxianwu/ligh ...
- Chrome扩展开发之四——核心功能的实现思路
目录: 0.Chrome扩展开发(Gmail附件管理助手)系列之〇——概述 1.Chrome扩展开发之一——Chrome扩展的文件结构 2.Chrome扩展开发之二——Chrome扩展中脚本的运行机制 ...
- ES6,ES2105核心功能一览,js新特性详解
ES6,ES2105核心功能一览,js新特性详解 过去几年 JavaScript 发生了很大的变化.ES6(ECMAScript 6.ES2105)是 JavaScript 语言的新标准,2015 年 ...
随机推荐
- 前端必须知道的手机调试工具vConsole
在日常业务中我相信大家多多少少都有移动端的项目,移动端的项目需要真机调试的很多东西看不到调试起来也比较麻烦,今天给大家分享一个我认为比较好用的调试第三方库VConsole ,有了这个库咱们就在手机上看 ...
- 关于 Span 的一切:探索新的 .NET 明星: 4. Span<T> 和 Memory<T> 是如何与 .NET 库集成的?
4. Span<T> 和 Memory<T> 是如何与 .NET 库集成的? 1. Span<T> 是什么? 2. Span<T> 是如何实现的? 3. ...
- 【C#】【平时作业】习题-4-流程控制
T1 创建一个Windows应用程序,先输入年龄值,再判断是否大于18,最后显示判断结果,运行效果如图所示. 提示: 注意保持逻辑完整: 引用数据需要明确出处. [程序代码] private void ...
- Qt开发经验小技巧171-175
在Qt编程中经常会遇到编码的问题,由于跨平台的考虑兼容各种系统,而windows系统默认是gbk或者gb2312编码,当然后期可能msvc编译器都支持utf8编码,所以在部分程序中传入中文目录文件名称 ...
- Qt通用方法及类库7
函数名 //int转字节数组 static QByteArray intToByte(int i); static QByteArray intToByteRec(int i); //字节数组转int ...
- 一句话,我让 AI 帮我做了个 P 图网站!
每到过节,不少小伙伴都会给自己的头像 P 个图,加点儿装饰. 比如圣诞节给自己头上 P 个圣诞帽,国庆节 P 个小红旗等等.这是一类比较简单.需求量却很大的 P 图场景,也有很多现成的网站和小程序,能 ...
- Eclipse中如何快速查询一个类和方法在哪里被引用?
0.在Eclipse中使用全局搜索Ctrl+h的方法快速查询一个类在哪里被引用. 打开Eclipse,使用快捷键Ctrl+h,会弹出一个对话框,找到File Search页签,在Containing ...
- 总是被低估,从未被超越,揭秘QQ极致丝滑背后的硬核IM技术优化
本文由腾讯云开发者张曌.毕磊分享,原题"QQ 9"傻快傻快"的?!带你看看背后的技术秘密",本文进行了排版和内容优化等. 1.引言 最新发布的 QQ 9 自上线 ...
- 如何快速在本地运行你vue打包的的dist文件
要在本机启动运行前端提供的dist包,需要先安装一个HTTP服务器,例如Apache,Nginx,phpstudy.这里以使用Node.js的http-server为例进行说明 首先,确保已经安装了N ...
- manim边做边学--动画更新
今天介绍Manim中用于动画更新的3个类,分别是: UpdateFromFunc:根据自定义的函数来动态更新 Mobject 的属性 UpdateFromAlphaFunc:根据动画的进度来平滑地改变 ...