ctypes学习 + GearDVFS源码分析(/src/perf_lib)
最近在尝试复现GearDVFS的代码,代码结构很复杂,由于需要获取硬件信息,作者使用ctypes实现与底层的交互,任务紧迫,开始学习吧!
1. ctypes介绍
资料的来源已经放在了后文的链接中,由于我的基础实在很薄弱,因此看了很多资料才搞懂ctypes的实现原理,如果有和我一样的菜鸟,在学习之前可以先了解一下:
1. C语言的编译原理
2. gcc的基本使用
3. Windows API 和 POSIX
已经修成正佛的请忽略这些 Q_Q 。
1.1 为什么需要ctypes
C语言可以对内存、文件接口等底层资源进行访问,因此当我们想获取一些底层信息来作为训练数据时就需要调用C的方法,同时当运算量较大时,可以使用C语言提升代码性能。Python调用C程序通常有三种方法:
- Cython:将 Python 代码转化为 C 代码。
- ctypes:加载底层动态链接库(.dll或.so),并使用其中的函数。
- SWIG:将 C/C++ 代码包装成 Python 库的工具。
GearDVFS选择使用ctypes实现。
1.2 ctypes基本使用
想要实现C语言和Python的交互,C代码需要使用Python的C API,而Python代码则需要使用ctypes库。资料来源[2]介绍了ctypes的原理,简单的来说,就是使用不同平台(Windows/Linux)API中提供的动态加载动态链接库的方法来达到链接的目的。ctypes就像C语言和Python语言之间的转换器一样,定义了一些数据类型,函数调用方法等作为C和Python的转换,即C <-> ctypes <-> Python,为方便阅读,我把一部分内容搬运了过来,想要详细了解的可以直接跳转到来源资料[3]和[4]中,建议先看官网的,不懂再看别人解释的。
1.2.1 加载动态链接库
在linux下,有两种方式加载动态链接库:
# 使用 dll 加载程序的方法
cdll.LoadLibrary("libc.so.6")
# 调用创建 CDLL 实例来加载库
libc = CDLL("libc.so.6")
libc
1.2.2 加载的 dll 访问函数
访问函数使用库.函数名:
from ctypes import *
libc.printf
print(windll.kernel32.GetModuleHandleA)
print(windll.kernel32.MyOwnFunction)
1.2.3 ctypes的数据类型
ctypes和C以及Python的对应关系如下:

数组、指针等定义如下:
# int类型
num = ctypes.c_int(1992)
# int指针
ctypes.POINTER(ctypes.c_int)
# int数组
int_arr = ctypes.c_int * 5 # 相当于C语言的 int[5]
# 可以指定数据来初始化数组
my_arr = int_arr(1, 3, 5, 7, 9)
1.2.4 ctypes函数调用
调用函数可以设置参数和返回类型,调用的方式和访问是一样的:
# 调用可变参数类函数
libc.printf.argtypes = [ctypes.c_char_p]
# 自定义数据类型调用函数,下面这个例子就设置了printd的参数类型
printf.argtypes = [c_char_p, c_char_p, c_int, c_double]
printf(b"String '%s', Int %d, Double %f\n", b"Hi", 10, 2.2)
# 默认情况下,假定函数返回 C int 类型,其他可以通过设置
2. GearDVFS源码分析(/src/perf_lib)
GearDVFS的项目框架如下:
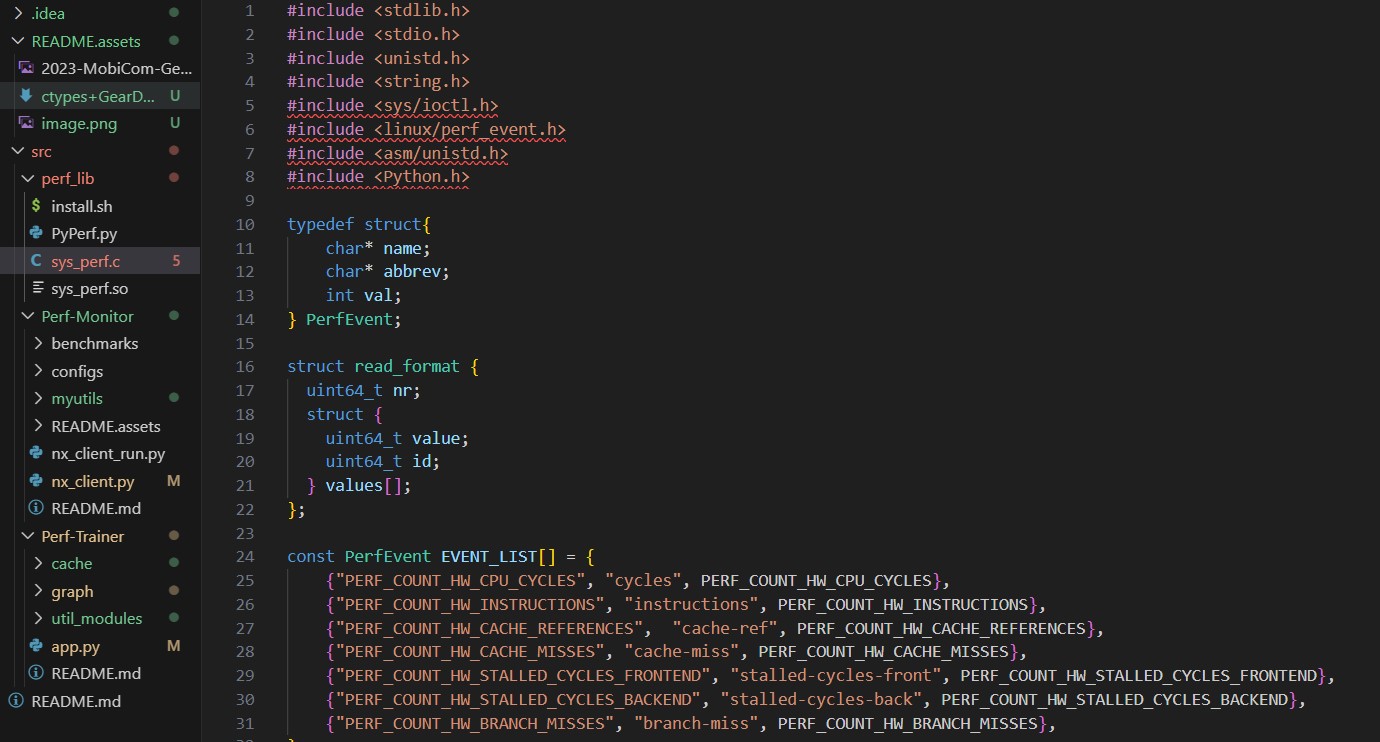
项目由三部分组成,各部分大致负责的是,perf_lib用于采集cpu利用率等硬件信息,Perf_Moniter写了一个客户端用于监测采集的数据,Perf_Trainer用于训练模型。perf_lib下有四个文件,分别是install.sh、PyPerf.py、sys_perf.c、sys_perf.so。sys_perf.so是sys_perf.c编译生成的动态链接库,我们主要看PyPerf.py和sys_perf.c。
2.1 sys_perf.c
perf_event.h头文件中包含了一些用于性能计数器的宏定义、数据结构和函数声明,以便于使用和操作性能计数器,对于每一个性能事件的监测,我们都需要配置性能计数器。头文件中的一些常见定义和声明包括:
- struct perf_event_attr:这是一个结构体,用于描述性能事件的属性。它包含了事件类型、计数器的配置和其他相关的信息。
- perf_event_open函数:这个函数用于创建和配置一个性能计数器事件。通过传递合适的参数,可以指定需要监测的事件类型,创建一个性能计数器的实例,并返回一个文件描述符,用于后续的操作和访问。
- ioctl函数:这个函数用于在打开的性能计数器文件描述符上执行控制操作。通过传递不同的控制命令和参数,可以对性能计数器进行启动、停止、重置、读取计数器值等操作。
- 相关的宏定义:
PERF_TYPE_HARDWARE、PERF_COUNT_HW_CPU_CYCLES、PERF_COUNT_SW_CPU_CLOCK等宏定义,定义了不同类型的性能事件和事件计数器。
sys_perf.c实现了对perf_event_attr的配置,建议配合源码一起看,我的介绍逻辑可能会有点混乱,有意见感谢提出。代码定义了两个结构体变量和PerfEvent类型数组,具体含义见注释:
//性能指标
typedef struct{
//名称
char* name;
//缩写
char* abbrev;
//数据
int val;
} PerfEvent;
//配置计数器值的格式
struct read_format {
//values的长度
uint64_t nr;
//可变长数组
struct {
uint64_t value;
uint64_t id;
} values[];
};
//性能数据列表,GearDVFS使用的性能数据与HWCPipe的性能指标相似
//PERF_COUNT_HW_CPU_CYCLES等的具体含义后面会介绍
const PerfEvent EVENT_LIST[] = {
{"PERF_COUNT_HW_CPU_CYCLES", "cycles", PERF_COUNT_HW_CPU_CYCLES},
{"PERF_COUNT_HW_INSTRUCTIONS", "instructions", PERF_COUNT_HW_INSTRUCTIONS},
{"PERF_COUNT_HW_CACHE_REFERENCES", "cache-ref", PERF_COUNT_HW_CACHE_REFERENCES},
{"PERF_COUNT_HW_CACHE_MISSES", "cache-miss", PERF_COUNT_HW_CACHE_MISSES},
{"PERF_COUNT_HW_STALLED_CYCLES_FRONTEND", "stalled-cycles-front", PERF_COUNT_HW_STALLED_CYCLES_FRONTEND},
{"PERF_COUNT_HW_STALLED_CYCLES_BACKEND", "stalled-cycles-back", PERF_COUNT_HW_STALLED_CYCLES_BACKEND},
{"PERF_COUNT_HW_BRANCH_MISSES", "branch-miss", PERF_COUNT_HW_BRANCH_MISSES},
};
2.1.1 perf_event_open函数
#include <linux/perf_event.h>
#include <asm/unistd.h>
#include <Python.h>
static long
perf_event_open(struct perf_event_attr *hw_event, pid_t pid,
int cpu, int group_fd, unsigned long flags)
{
int ret;
ret = syscall(__NR_perf_event_open, hw_event, pid, cpu,
group_fd, flags);
return ret;
}
静态函数static long perf_event_open(struct perf_event_attr *hw_event, pid_t pid,int cpu, int group_fd, unsigned long flags)实现了对perf_event_open的系统调用,返回值是新的文件描述符,如果发生错误则返回错误码-1,参数为:
- pid_t pid:进程ID,指定创建性能计数器的进程。
- int cpu:CPU编号,指定创建性能计数器的CPU。
- int group_fd:性能计数器分组的文件描述符,用于将多个计数器分组在一起。如果不需要分组,则传入-1。
- unsigned long flags:标志位,添加附加功能。
- struct perf_event_attr *hw_event:指向
perf_event_attr结构体的指针,用于配置性能计数器的属性,对于每一个CPU和每一个指标,我们都需要配置一个perf_event:- type:指定性能计数器的类型,例如指令计数器、缓存事件计数器等。
- size:结构体的大小,在初始化时需要设置为sizeof(struct perf_event_attr)。
- config:指定具体的计数器配置,根据不同的type和硬件平台而有所不同。
- sample_period:设置性能采样的周期,即每隔多少事件进行一次采样。例如,设置为100表示每100个事件进行一次采样。
- sample_type:指定采样的类型,如指令指针、用户态/内核态标志等。
- read_format:指定计数器值的格式。
//perf_event_attr部分字段
struct perf_event_attr {
__u32 type; /* Type of event */
__u32 size; /* Size of attribute structure */
__u64 config; /* Type-specific configuration */
union {
__u64 sample_period; /* Period of sampling */
__u64 sample_freq; /* Frequency of sampling */
};
/*
......
*/
};
//type字段,GearDVFS的字段设置为了通用硬件事件
enum perf_type_id { /* perf 类型 */
PERF_TYPE_HARDWARE = 0, /* 通用硬件事件之一 */
PERF_TYPE_SOFTWARE = 1, /* 内核提供的一种软件定义的事件 */
PERF_TYPE_TRACEPOINT = 2, /* 内核跟踪点基础结构提供的跟踪点 /sys/bus/event_source/devices/tracepoint/type */
PERF_TYPE_HW_CACHE = 3, /* 硬件cache */
PERF_TYPE_RAW = 4, /* RAW/CPU /sys/bus/event_source/devices/cpu/type */
PERF_TYPE_BREAKPOINT = 5, /* 断点 /sys/bus/event_source/devices/breakpoint/type */
PERF_TYPE_MAX, /* non-ABI */
};
//常见的硬件事件,可以看到EVENT_LIST就是从这里面选择的
enum perf_hw_id {
/*
* Common hardware events, generalized by the kernel:
*/
PERF_COUNT_HW_CPU_CYCLES = 0,
PERF_COUNT_HW_INSTRUCTIONS = 1,
PERF_COUNT_HW_CACHE_REFERENCES = 2,
PERF_COUNT_HW_CACHE_MISSES = 3,
PERF_COUNT_HW_BRANCH_INSTRUCTIONS = 4,
PERF_COUNT_HW_BRANCH_MISSES = 5,
PERF_COUNT_HW_BUS_CYCLES = 6,
PERF_COUNT_HW_STALLED_CYCLES_FRONTEND = 7,
PERF_COUNT_HW_STALLED_CYCLES_BACKEND = 8,
PERF_COUNT_HW_REF_CPU_CYCLES = 9,
PERF_COUNT_HW_MAX, /* non-ABI */
};
更多内容请参考资料来源[6]。
2.1.2 EVENT_LIST字段get函数
PyObject* get_supported_names()函数、PyObject* get_supported_events()函数、PyObject* get_supported_abbrevs()函数提供了Python获取EVENT_LIST各字段的接口,三个函数的实现方式相同,使用Python的C API来创建和操作Python对象,返回值为PyObject指针指向Python列表对象,无参数。
PyObject*
get_supported_names()
{
//计算指标数量
int length = sizeof(EVENT_LIST)/sizeof(EVENT_LIST[0]);
PyObject* name_list = PyList_New(length);
for (int i = 0; i < length; ++i) {
PyList_SetItem(name_list,i,Py_BuildValue("s",EVENT_LIST[i].name));
}
return name_list;
}
2.1.3 sys_perf函数
共有n_event个性能事件和n_cpu个CPU,那么对于每一个CPU都需要配置和储存n_event个事件结果,因此定义并初始化了二维指针数组 fds、ids、bufs、rfs,它们的大小都是n_cpu*n_event。fds存放的是每一个perf_event_open系统调用后的返回值,也就是文件描述符;rfs存放的是每一个事件的read_format的地址;bufs是4096字节的缓冲区大小,后续将放置read_format,rfs指向该缓冲区;pea为一个perf_event_attr结构体对象;ids用于存放每一个事件的ID。
Py_ssize_t n_event = PyList_Size(events);
Py_ssize_t n_cpu = PyList_Size(cpus);
int N_COUNTER = n_cpu*n_event;
PyObject* result_list = PyList_New(n_cpu);
// initialization
struct perf_event_attr pea;
struct read_format **rfs = (struct read_format**)calloc(n_cpu, sizeof(struct read_format*));
int **fds = (int **)calloc(n_cpu, sizeof(int *));
uint64_t **ids = (uint64_t **)calloc(n_cpu, sizeof(uint64_t *));
char **bufs = (char **)calloc(n_cpu, sizeof(char *));
for (int i=0; i < n_cpu; i++) {
fds[i] = (int*)calloc(N_COUNTER,sizeof(int));//这里感觉有点小问题,应该分配n_event大小的空间
ids[i] = (uint64_t*)calloc(N_COUNTER,sizeof(uint64_t));
bufs[i] = (char*)calloc(4096,sizeof(char));
rfs[i] = (struct read_format*) bufs[i];
}
对每一个CPU的每一个事件进行初始化,将pea的内存清零,接下来设置pea的各个字段:type字段为硬件事件;size为perf_event_attr大小;config为EVENT_LIST中的各事件;disabled = 1表示性能事件会被创建但处于禁用状态,不会立即开始计数;exlude_kernel表示不排除内核空间的代码执行;·exclude_hv排除虚拟化环境(Hypervisor)的代码执行;read_format的设置中PERF_FORMAT_GROUP是一个标志,用于指示性能计数器的事件被分组,也就是多个事件被同时计数,并且在读取计数器值时以一组数据的形式返回,PERF_FORMAT_ID是另一个标志,用于指示每个计数器事件的 ID 也被返回。
那么我们就可以看到下面的代码,对于第一个事件而言,先不分组,返回的文件标识符作为后续事件的group_fd传入,效果就是事件以CPU的编号作为分组,ioctl系统调用将性能计数器的事件 ID 存储到ids数组中。
// for each cpu and each hardware event
for (int i = 0; i < n_cpu; i++) {
int cpu_index = (int)PyLong_AsLong(PyList_GetItem(cpus,i));
for (int j = 0; j < n_event; j++) {
int event_index = (int)PyLong_AsLong(PyList_GetItem(events,j));
memset(&pea, 0, sizeof(struct perf_event_attr));
pea.type = PERF_TYPE_HARDWARE;
pea.size = sizeof(struct perf_event_attr);
pea.config = EVENT_LIST[event_index].val;
pea.disabled = 1;
pea.exclude_kernel = 0;
pea.exclude_hv = 1;
pea.read_format = PERF_FORMAT_GROUP | PERF_FORMAT_ID;
if (j == 0) {
fds[i][j] = syscall(__NR_perf_event_open, &pea, -1, cpu_index, -1, 0);
// fprintf(stderr,"%d,%d,%d\n",i,j,fds[i][j]);
} else {
fds[i][j] = syscall(__NR_perf_event_open, &pea, -1, cpu_index, fds[i][0], 0);
}
if (fds[i][j] == -1) {
fprintf(stderr,"Error opening leader %llx\n", pea.config);
exit(EXIT_FAILURE);
}
ioctl(fds[i][j], PERF_EVENT_IOC_ID, &ids[i][j]);
}
}
下面的代码里面使用了几个ioctl的命令:PERF_EVENT_IOC_RESET重置性能计数器;PERF_EVENT_IOC_ENABLE启动性能计数器;PERF_EVENT_IOC_DISABLE禁用性能计数器;PERF_IOC_FLAG_GROUP以组的方式启动。根据ioctl获得的id去read_format中查找可变数组values的id即可找到对应值,保存为Python对象。
// monitoring for each cpu group
for (int i=0; i < n_cpu; i++) {
ioctl(fds[i][0], PERF_EVENT_IOC_RESET, PERF_IOC_FLAG_GROUP);
ioctl(fds[i][0], PERF_EVENT_IOC_ENABLE, PERF_IOC_FLAG_GROUP);
}
usleep(micro_seconds);
for (int i=0; i < n_cpu; i++) {
ioctl(fds[i][0], PERF_EVENT_IOC_DISABLE, PERF_IOC_FLAG_GROUP);
}
// read counters and pack into PyList
for (int i=0; i < n_cpu; i++) {
read(fds[i][0], bufs[i], 4096*sizeof(char));
PyObject* cpu_result = PyList_New(n_event);
for (int j=0; j < n_event; j++) {
// search for ids
for (int k=0; k < rfs[i]->nr; k++) {
if (rfs[i]->values[k].id == ids[i][j]) {
uint64_t val = rfs[i]->values[k].value;
PyList_SetItem(cpu_result,j,Py_BuildValue("l",val));
}
}
}
PyList_SetItem(result_list,i,cpu_result);
}
3. PyPerf.py和install.sh
剩下的就简单介绍一下,根据之前的介绍可以知道PyPerf.py中设置所有的返回类型为py_object,并对sys_perf.c中的函数进行调用,参数设置为cpus = [0,1],events = [0]即硬件事件,结果存放在result_dict中。
这个就是gcc的指令,编译sys_perf.c生成.so文件,删除.o文件。
资料来源
- [1]知乎:python 这种解释型语言与底层交互的 api 是怎么编写的?
- [2]聊聊Python ctypes 模块
- [3]ctypes的基本使用
- [4]ctypes官方介绍
- [5]PyObject介绍
- [6]perf_event_open系统调用与用户手册详解
- [7]perf_event.h
ctypes学习 + GearDVFS源码分析(/src/perf_lib)的更多相关文章
- DotNetty网络通信框架学习之源码分析
DotNetty网络通信框架学习之源码分析 有关DotNetty框架,网上的详细资料不是很多,有不多的几个博友做了简单的介绍,也没有做深入的探究,我也根据源码中提供的demo做一下记录,方便后期查阅. ...
- bootstrap-modal 学习笔记 源码分析
Bootstrap是Twitter推出的一个开源的用于前端开发的工具包,怎么用直接官网 http://twitter.github.io/bootstrap/ 我博客的定位就是把这些年看过的源码给慢慢 ...
- Android FM模块学习之四源码分析(3)
接着看FM模块的其他几个次要的类的源码.这样来看FM上层的东西不是太多. 请看android\vendor\qcom\opensource\fm\fmapp2\src\com\caf\fmradio\ ...
- 并发编程原理学习-reentrantlock源码分析
ReentrantLock基本概念 ReentrantLock是一个可重入锁,顾名思义,就是支持重进入的锁,它表示该锁能够支持一个线程对资源的重复加锁,并且在获取锁时支持选择公平模式或者非公平模式 ...
- Java基础系列--07_Object类的学习及源码分析
Object: 超类 (1)Object是类层次结构的顶层类,是所有类的根类,超类. 所有的类都直接或者间接的继承自Object类. 所有对象(包括数组)都实现这个类的方法 (2)Object ...
- mybatis 学习四 源码分析 mybatis如何执行的一条sql
总体三部分,创建sessionfactory,创建session,执行sql获取结果 1,创建sessionfactory 这里其实主要做的事情就是将xml的所有配置信息转换成一个Confi ...
- Java容器源码学习--ArrayList源码分析
ArrayList实现了List接口,它的底层数据结构是数组,因此获取容器中任意元素值的时间复杂度为O(1),新增或删除元素的时间复杂度为O(N).每一个ArrayList实例都有一个capacity ...
- Redis学习——链表源码分析
0. 前言 Redis 中的链表是以通用链表的形式实现的,而对于链表的用途来说,主要的功能就是增删改查,所以对于查找来说,redis其提供了一个match函数指针,用户负责实现其具体的匹配操作,从而实 ...
- C# DateTime的11种构造函数 [Abp 源码分析]十五、自动审计记录 .Net 登陆的时候添加验证码 使用Topshelf开发Windows服务、记录日志 日常杂记——C#验证码 c#_生成图片式验证码 C# 利用SharpZipLib生成压缩包 Sql2012如何将远程服务器数据库及表、表结构、表数据导入本地数据库
C# DateTime的11种构造函数 别的也不多说没直接贴代码 using System; using System.Collections.Generic; using System.Glob ...
- 【TencentOS tiny】深度源码分析(4)——消息队列
消息队列 在前一篇文章中[TencentOS tiny学习]源码分析(3)--队列 我们描述了TencentOS tiny的队列实现,同时也点出了TencentOS tiny的队列是依赖于消息队列的, ...
随机推荐
- Docker Swarm Mode 的容器资源回收问题
问题描述 Docker Swarm Mode 中 service 的update/scale等操作都会形成残留的容器和镜像,会造成一定程度的磁盘空间占用及缓存占用等问题... 解析 存在即合理,残留的 ...
- C#/.NET/.NET Core技术前沿周刊 | 第 33 期(2025年4.1-4.6)
前言 C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录.追踪C#/.NET/.NET Core领域.生态的每周最新.最实用.最有价值的技术文章.社区动态.优质项目和学习资源等. ...
- 使用python批量爬取wallhaven.cc壁纸站壁纸
偶然发现https://wallhaven.cc/这个壁纸站的壁纸还不错,尤其是更新比较频繁,用python写个脚本爬取 点latest,按照更新先后排序,获得新地址,发现地址是分页展示的,每一页24 ...
- 即时通信SSE和WebSocket对比
Server-Sent Events (SSE) 和 WebSocket 都是用于实现服务器与客户端实时通信的技术,但它们在设计目标.协议特性和适用场景上有显著区别.以下是两者的详细对比: 一.核心区 ...
- 获取img标签文件大小
创建一个请求,然后查看返回的content-length img.src.length * 0.75 canvas转base64后
- System Integrity Protection (SIP) iOS10.15安装软件提示文件损坏问题解决方法
方法如下:1.开机的时候立即按住command+R 组合键不要放手,直到进度条加载完才松手,进入到系统恢复工具界面 2. 然后点击"实用工具"选项卡中的"终端" ...
- 异步IO与Tortoise-ORM的数据库
title: 异步IO与Tortoise-ORM的数据库 date: 2025/04/29 13:21:47 updated: 2025/04/29 13:21:47 author: cmdragon ...
- Gnirehtet —— 通过 USB 让手机共享 PC 网络
Gnirehtet 使用教程 什么是 Gnirehtet? Gnirehtet("Tethering" 反写)是 Google 开发的开源工具,用于 通过 USB 共享 PC 网络 ...
- 【HUST】网安|计算机网络|计算机网络自顶向下方法(原书第7版)第三章部分习题答案
参考:英文版的原答案. 答案放gitee了,自取. 3-P18. 3.4.4 节我们学习的一般性 SR 协议中,只要报文可用(如果报文在窗口中) ,发送方就会不等待确认而传输报文.假设现在我们要求一个 ...
- 【安装】Linux下安装CUDA ToolKit 11.4和cuDNN 8
注意!如果你使用的是pytorch,只需要装好CUDA,不需要装cuDNN.而且完全可以等到报错了再装CUDA,一般情况系统都已经装好CUDA Toolkit了. 除非你只装了低版本的CUDA Too ...