十一:Centralized Cache Management in HDFS 集中缓存管理
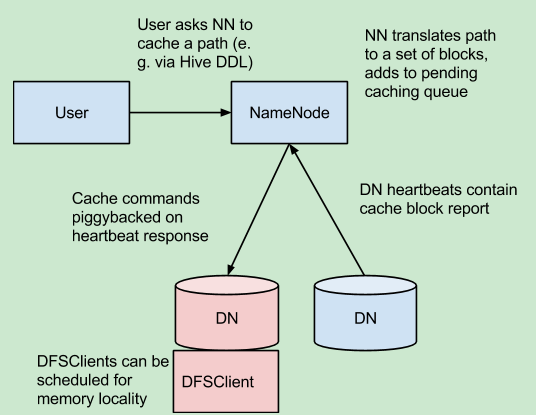
集中的HDFS缓存管理,该机制可以让用户缓存特定的hdfs路径,这些块缓存在堆外内存中。namenode指导datanode完成这个工作。
Centralized cache management in HDFS has many significant advantages.
- Explicit pinning prevents frequently used data from being evicted from memory. This is particularly important when the size of the working set exceeds the size of main memory, which is common for many HDFS workloads. 阻止经常使用的数据被逐出内存。
- Because DataNode caches are managed by the NameNode, applications can query the set of cached block locations when making task placement decisions. Co-locating a task with a cached block replica improves read performance.
- When block has been cached by a DataNode, clients can use a new , more-efficient, zero-copy read API. Since checksum verification of cached data is done once by the DataNode, clients can incur essentially zero overhead when using this new API.可以使用更高效的无复制的api读这些块。
- Centralized caching can improve overall cluster memory utilization. When relying on the OS buffer cache at each DataNode, repeated reads of a block will result in all nreplicas of the block being pulled into buffer cache. With centralized cache management, a user can explicitly pin only m of the n replicas, saving n-m memory.减少重复读时使用的
十一:Centralized Cache Management in HDFS 集中缓存管理的更多相关文章
- Centralized Cache Management in HDFS
Overview(概述) Centralized cache management in HDFS is an explicit caching mechanism that allows users ...
- HDFS集中式缓存管理(Centralized Cache Management)
Hadoop从2.3.0版本号開始支持HDFS缓存机制,HDFS同意用户将一部分文件夹或文件缓存在HDFS其中.NameNode会通知拥有相应块的DataNodes将其缓存在DataNode的内存其中 ...
- HDFS中的集中缓存管理详解
一.背景 Hadoop设计之初借鉴GFS/MapReduce的思想:移动计算的成本远小于移动数据的成本.所以调度通常会尽可能将计算移动到拥有数据的节点上,在作业执行过程中,从HDFS角度看,计算和数据 ...
- HDFS集中式的缓存管理原理与代码剖析--转载
原文地址:http://yanbohappy.sinaapp.com/?p=468 Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache ...
- HDFS集中式的缓存管理原理与代码剖析
转载自:http://www.infoq.com/cn/articles/hdfs-centralized-cache/ HDFS集中式的缓存管理原理与代码剖析 Hadoop 2.3.0已经发布了,其 ...
- 自定义缓存管理器 或者 Spring -- cache
Spring Cache 缓存是实际工作中非常常用的一种提高性能的方法, 我们会在许多场景下来使用缓存. 本文通过一个简单的例子进行展开,通过对比我们原来的自定义缓存和 spring 的基于注释的 c ...
- 【Hadoop学习】HDFS中的集中化缓存管理
Hadoop版本:2.6.0 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4146398.html 概述 ...
- HDFS集中化缓存管理
概述 HDFS中的集中化缓存管理是一个明确的缓存机制,它允许用户指定要缓存的HDFS路径.NameNode会和保存着所需快数据的所有DataNode通信,并指导他们把块数据缓存在off-heap缓存中 ...
- Webview离线功能(优先cache缓存+cache缓存管理)
在做Webview显示服务器的html功能时 需要加入离线功能. 开始思路很狭隘,以为一定应该是从服务器得到的html文件,下载到本地后加载~ 但是这样不能离线查看图片,因为图片数据并不再html中, ...
随机推荐
- js实现点击按钮可实现编辑
<script type="text/javascript">//修改密码//抓取到的数据 function edit() { document.getElementB ...
- 前端ajax的各种与后端交互的姿势
前端中常常用的与后端交换数据的话,通常是要用到ajax这种方法的 但是交互的方式有很多种,很多取决于你后端的属性,我这儿主要列举我目前项目比较常用的两种方式 --一个是我们通用的web api和控制器 ...
- VMware Workstation 安装Vmware tools 是 出现vmware tools unavailable
这个问题是因为虚拟机安装的时候操作系统选择的不对,在Virtual Machine Settings中选择Options,在General中选择正确的操作系统类型 例如Guest operating ...
- 生产环境MySQL数据库集群MHA上线实施方案
生产环境MySQL数据库集群MHA上线实施方案 一.不停库操作 1.在所有节点安装MHAnode所需的perl模块(需要有安装epel源) yum install perl-DBD-MySQL -y ...
- html+css3 实现各种loading效果
效果见下图 代码: 建议直接去本人github上浏览代码 https://github.com/wuliqiangqiang/loading <!DOCTYPE html> <htm ...
- Invoice Helper
using System; using Microsoft.Xrm.Sdk; using Microsoft.Xrm.Sdk.Query; using Microsoft.Crm.Sdk.Messag ...
- 月薪30-50K的大数据工程师们,他们背后是如何学习的
这两天小编去了解了下大数据开发相关职位的薪资,主要有hadoop工程师,数据挖掘工程师.大数据算法工程师等,从平均薪资来看,目前大数据相关岗位的月薪均在2万以上,随着项目经验的增长工资会越来越高. ...
- ElasticSearch5插件安装
http://blog.csdn.net/napoay/article/details/53896348 #更新 sudo yum update -y sudo rpm -ivh http://dl. ...
- Go 入门 - 控制流
主要内容来自中文版的官方教程Go语言之旅 目的为总结要点 循环 Go 只有 for循环 for 由三部分组成,用分号间隔开 初始化语句:在第一次迭代之前执行,通常为一句短变量声明(i:=0) 条件表达 ...
- linux redhat NFS网络共享搭建
nfs网络共享 测试环境: 服务端:redhat6.7 ip:192.168.1.100 客户端:redhat6.7 ip:192.168.1.110 一.服务端 1.创建共享文件夹 权限666即可 ...