基于物品的协同过滤算法(ItemCF)
最近在学习使用阿里云的推荐引擎时,在使用的过程中用到很多推荐算法,所以就研究了一下,这里主要介绍一种推荐算法—基于物品的协同过滤算法。
ItemCF算法不是根据物品内容的属性计算物品之间的相似度,而是通过分析用户的行为记录来计算用户的相似度。该算法认为物品A和物品B相似的依据是因为喜欢物品A的用户也喜欢物品B。
基于物品的协同过滤算法实现步骤:
1、计算物品之间的相似度
2、根据物品的相似度和用户的历史行为记录给用户生成推荐列表
下面我们一起来看一下这两部是如何实现的:
一、计算物品之间的相似度
通过查询一下资料,ItemCF的物品相似度计算模型如下: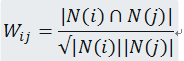
公式中|N(i)|表示喜欢物品i的用户数,|N(j)|表示喜欢物品j的用户数, |N(i)∩N(j)|表示同时喜欢物品i和物品j的用户数。从上面的公式我们可以看出物品i和物品j相似是因为他们共同别很多的用户喜欢,相似度越高表示同时喜欢他们的用户数越多。
下面举例讲解一下相似度的计算过程:
假设用户A对物品a,b,d有过评价,用户B对物品b,c,e有过评价,如下图:
A : a b d
B : b c e
C : c d
D : b c d
E : a d
根据上面用户的行为构建:用户——物品倒排表:例如:物品a有用户A和E做过评价。
a : A E
b : A B D
c : B C D
d : A C D E
e : B
根据上面的倒排表我们可以构建一个相似度矩阵: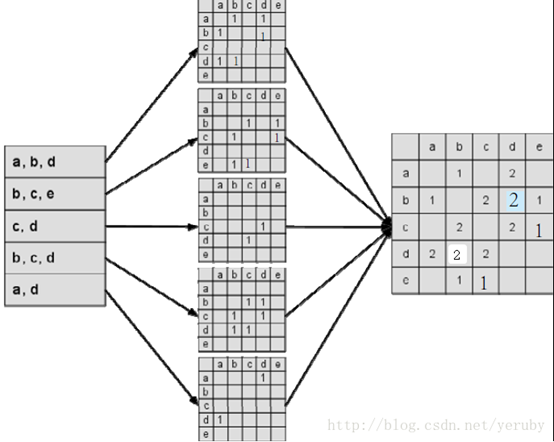
图 1.1 计算物品的相似度
图中最左边的是用户输入的用户行为记录,每一行代表用户感兴趣的物品集合,然后对每个物品集合,我们将里面的物品两两加一,得到一个矩阵。最终将这些矩阵进行相加得到上面的C矩阵。其中Ci记录了同时喜欢物品i和j的用户数。这样我们就得到了物品之间的相似度矩阵W。
二、根据物品的相似度和用户的历史行为记录给用户生成推荐列表
ItemCF通过下面的公式计算用户u对一个物品j的兴趣:
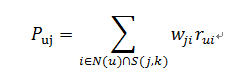
这里的N(u)代表用户喜欢的物品的集合,S(j,k)是和物品j最相似的的k个物品的集合,wij是物品j和i的相似度,r_ui代表用户u对物品i的兴趣。该公式的含义是,和用户历史上最感兴趣的物品月相似的物品,越有可能在用户的推荐列表中获得比较高的排名。
下面是查阅资料找到的一些优化方法:
(1)、用户活跃度对物品相似度的影响
即认为活跃用户对物品相似度的贡献应该小于不活跃的用户,所以增加一个IUF(Inverse User Frequence)参数来修正物品相似度的计算公式: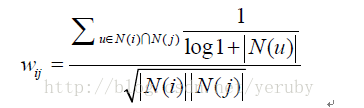
用这种相似度计算的ItemCF被记为ItemCF-IUF。
ItemCF-IUF在准确率和召回率两个指标上和ItemCF相近,但它明显提高了推荐结果的覆盖率,降低了推荐结果的流行度,从这个意义上说,ItemCF-IUF确实改进了ItemCF的综合性能。
(2)、物品相似度的归一化
Karypis在研究中发现如果将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确度。其研究表明,如果已经得到了物品相似度矩阵w,那么可用如下公式得到归一化之后的相似度矩阵w':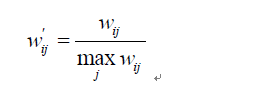
最终结果表明,归一化的好处不仅仅在于增加推荐的准确度,它还可以提高推荐的覆盖率和多样性。用这种相似度计算的ItemCF被记为ItemCF-Norm。
基于物品的协同过滤算法(ItemCF)的更多相关文章
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- 推荐召回--基于物品的协同过滤:ItemCF
目录 1. 前言 2. 原理&计算&改进 3. 总结 1. 前言 说完基于用户的协同过滤后,趁热打铁,我们来说说基于物品的协同过滤:"看了又看","买了又 ...
- 基于物品的协同过滤(ItemCF)
- 转】Mahout分步式程序开发 基于物品的协同过滤ItemCF
原博文出自于: http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ 感谢! Posted: Oct 14, 2013 Tags: Hadoopite ...
- Mahout分步式程序开发 基于物品的协同过滤ItemCF
http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, ...
- 基于物品的协同过滤ItemCF的mapreduce实现
文章的UML图比较好看..... 原文链接:www.cnblogs.com/anny-1980/articles/3519555.html 基于物品的协同过滤ItemCF 数据集字段: 1. Use ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- 基于物品的协同过滤item-CF 之电影推荐 python
推荐算法有基于协同的Collaboration Filtering:包括 user Based和item Based:基于内容 : Content Based 协同过滤包括基于物品的协同过滤和基于用户 ...
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
随机推荐
- xshell安装教程
Xshell安装使用教程 Xshell 是一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议.Xshell 通过互联网到远程主机 ...
- QP之QK原理
QK是一个很小的抢占式微内核调度程序,它专用用QP中. QK的思想源于SST,Miro Samek重写了自己前期编的SST(Super Simple Task)代码. QK循环查询AO队列的状态表QK ...
- Linux及FL2440使用过程遇到的各种问题和小技巧
原文链接:http://www.cnblogs.com/NickQ/p/8900474.html ## Linux及FL2440使用过程遇到的各种问题和小技巧 关于移植linux根文件系统中的问题 在 ...
- PAT (Basic Level) Practice 1008 数组元素循环右移问题
个人练习 一个数组A中存有N(>)个整数,在不允许使用另外数组的前提下,将每个整数循环向右移M(≥)个位置,即将A中的数据由(A0A1⋯AN−1)变换为(AN−M⋯AN ...
- Docker开篇之HelloWorld
按照程序世界的惯例,我们应该以HelloWorld的程序为起点开始介绍.那么接下来我们就看看Docker的HelloWorld是如何运行的. 安装 Docker CE 由于我的系统是OSX,个人推荐使 ...
- 常见java异常英语词汇(一)
denied /dɪ'naɪəd/ adj 拒签 v 拒绝
- springBoot整合ecache缓存
EhCache 是一个纯Java的进程内缓存框架,具有快速.精干等特点,是Hibernate中默认的CacheProvider. ehcache提供了多种缓存策略,主要分为内存和磁盘两级,所以无需担心 ...
- 长沙Uber优步司机奖励政策(12月14日到12月20日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- mongoDB在java上面的应用
1.实际应用过程中肯定不会直接通过Linux的方式来连接和使用数据库,而是通过其他驱动的方式来使用mongoDB 2.本教程只针对于Java来做操作,主要是模拟mongoDB数据库在开发过程中的应用 ...
- Mysql忘记密码处理办法
找回密码的步骤如下: 1.停止mysql服务器 sudo /opt/lampp/lampp stopmysql 2.使用`--skip-grant-tables' 参数来启动 mysqld sudo ...