打通 Spark 系统运行内幕机制循环流程
本课主题
- 打通 Spark 系统运行内幕机制循环流程
引言
通过 DAGScheduelr 面向整个 Job,然后划分成不同的 Stage,Stage 是从后往前划分的,执行的时候是從前往后执行的,每个 Stage 内部有一系列任务,前面有分享过,任务是并行计算啦,这是并行计算的逻辑是完全相同的,只不过是处理的数据不同而已,DAGScheduler 会以 TaskSet 的方式把我们一个 DAG 构造的 Stage 中的所有任务提交给底层的调度器 TaskScheduler,TaskScheduler 是一个接口,它作为接口的好处就是更具体的任务调到器解耦,这就 Spark 就可以运行在不同的调度模式上,包括可以让它运行在 Standalone、Yarn、Mesos。希望这篇文章能为读者带出以下的启发:
- 了解 Spark 系统运行内幕机制循环流程
Spark 系统运行内幕机制循环流程
DAGScheduler 在提交 TaskSet 给底层的调度器的时候是面向接口 TaskScheduler的,这符合面向对象中依赖抽象而不依赖具体的原则,带来底层资源调度器的可插拔性。导致 Spark 可以运行在众多的资源调度器的模式上,例如 Standalone 、Yarn、Mesos、Local、EC2、其它自定义的资源调度器;在 Standalone 的模式下,我们聚焦于 TaskSchedulerImpl。它会通过 TaskSet Manager 来管理我们这个具体的任务。
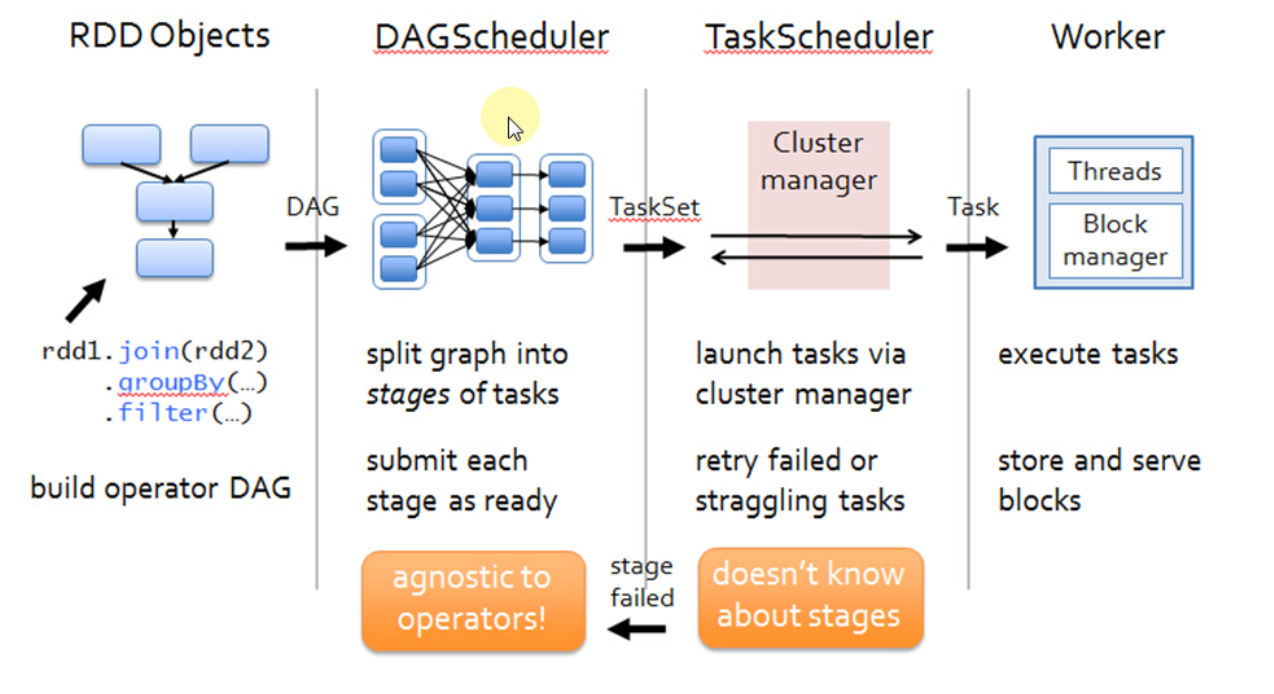
TaskScheduler 的核心任务是提交 TaskSet 到集群运算并汇报结果
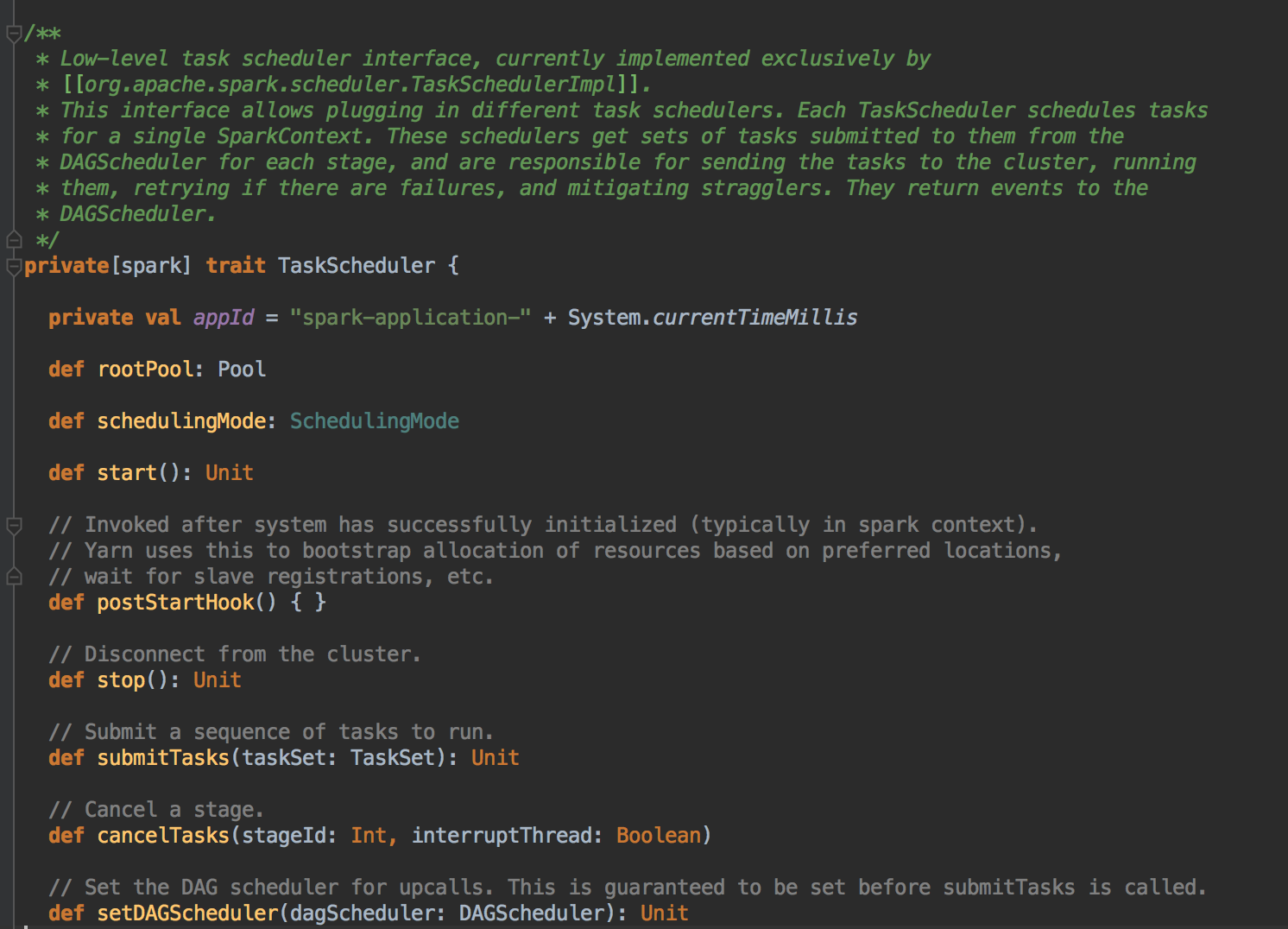
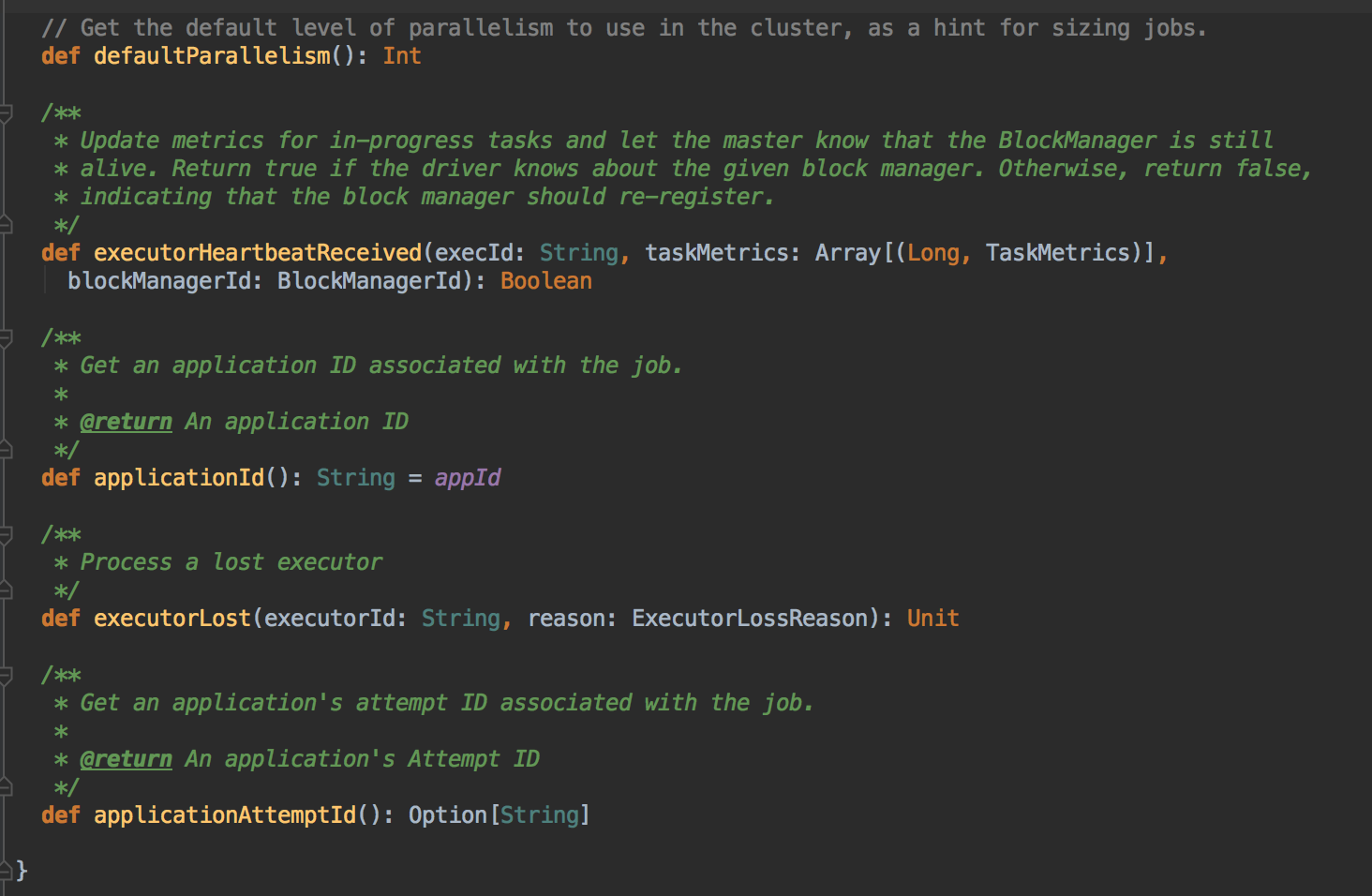
为 TaskSet 创建和维护一个 TaskSetManager 并追踪任务的本地性以及错误信息;遇到 Struggle 任务的时候会放到其他的节点进行重试;TaskScheduler 必须向 DAGScheduler 汇报执行情况,包括在 Shuffle 输出 lost 的时候报告 fetch failed 错误等信息;TaskScheduler 内部会握有 SchedulerBackend,它主要是负责管理 Executor 资源的,从 Standalone 的模式来讲具体实现是 SparkDeploySchedulerBackend; 下图是 SchedulerBackend 的源码
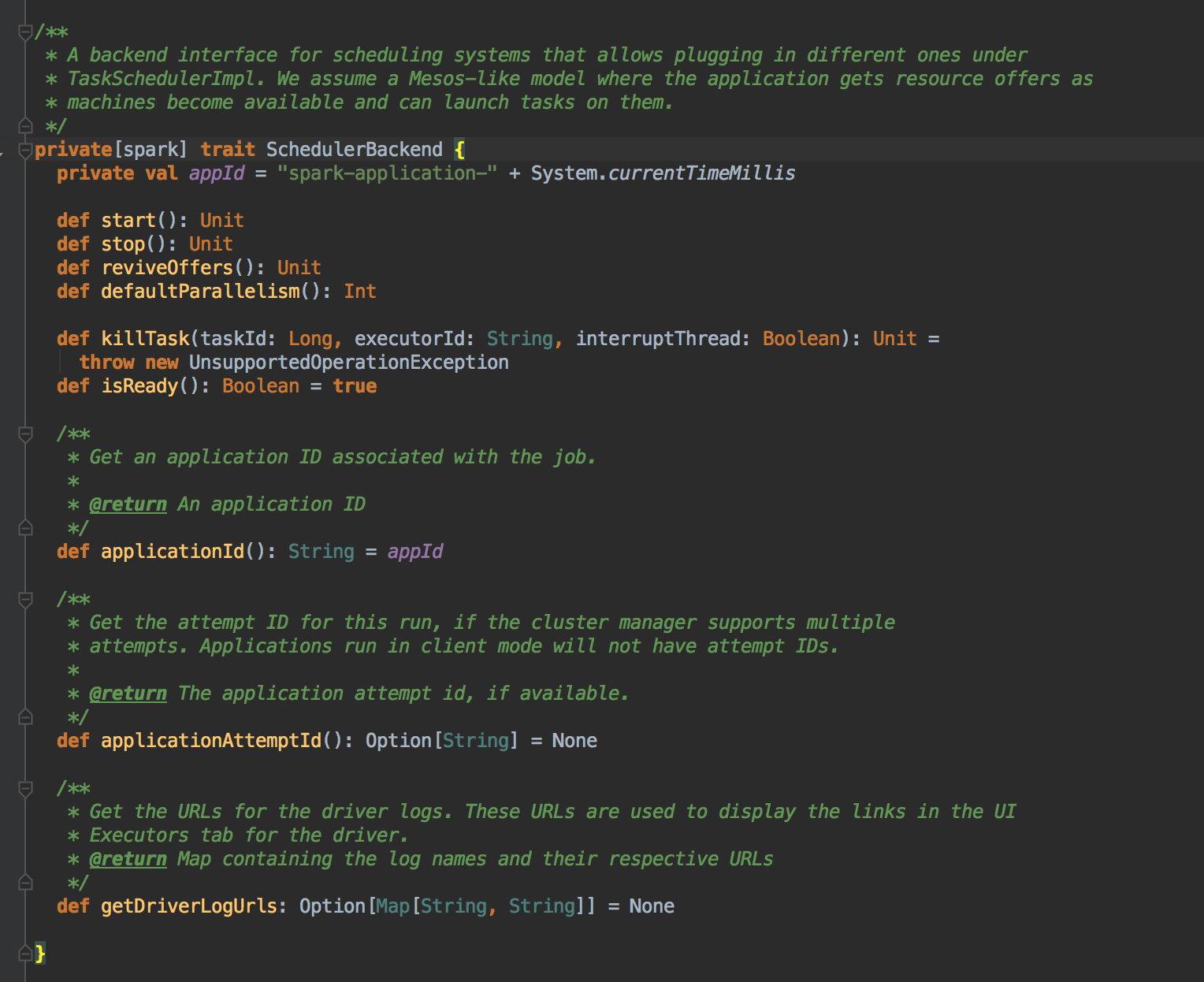
SparkDeploySchedulerBackend 专门收集 Worker 上的资源信息的。它会接受 Worker 向 Driver 注册的信息,而这个注册的时候其实就是 ExecutorBackend 启动的时候为我们当前应用程序准备的计算资源,但它是以进程为单位的。SparkDeploySchedulerBackend 在启动的时候构造 AppClient 实例并在该实例 start 的时候启动了 ClientEndpoint 这个消息循环体,ClientEndpoint 在启动的时候会向 Master 注册当前程序。
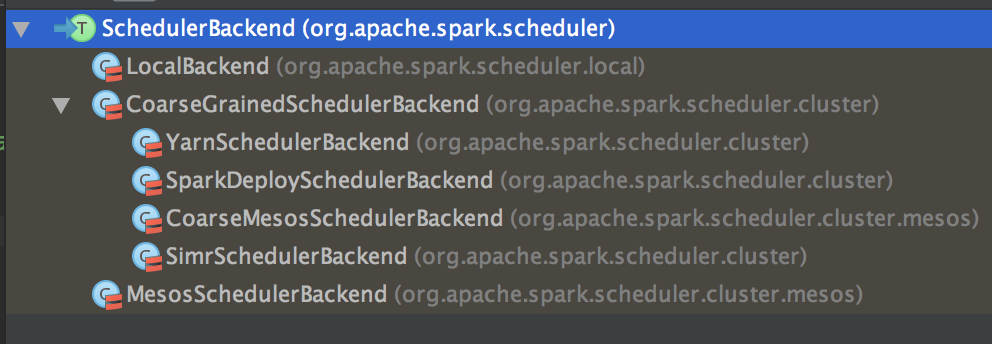
而 SparkDeploySchedulerBackend 的父类 CoraseGraninedExecutorBackend 在 start 的时候会实例化类型为 DriverEndpoint (这就是我们程序运行时候的经典的对象Driver,所以的Executor 启动时都需要向它注册) 的消息循环体,当 ExecutorBackend 启动的时候会发送 RegisterExecutor 信息向 DriverEndpoint 注册,此时 SparkDeploySchedulerBackend 就掌握了当前应用程序的计算资源,TaskScheduler 就是通过 SparkDeploySchedulerBackend 的计算资源来具体运行 Task。(SparkDeploySchedulerBackend 在整个应用程序起动一次就行啦)
SparkContext、DAGScheduler、TaskSchedulerImpl、SparkDeploySchedulerBackend 在应用程序起动的时候只实例化一次,应用程序存在期间始终存在这些对象;应用程序的总管是 DAGScheduler 和 TaskScheduler,SparkDeploySchedulerBackend 是帮助应用程序的 Task 获取具体的计算资源并把 Task 发送到集群中的。
总结
在SparkContext 实例化的时候调用 createTaskScheduler 来创建 TaskSchedulerImpl 和 SparkDeploySchedulerBackend 同时在 SparkContext 实例化的时候会调用TaskSchedulerImpl 的 start( )方法,在start( )方法中会调用 SparkDeploySchedulerBackend 的start( ),在该start( ) 方法中会创建AppClient 对象并调用AppClient 对象的start( ) 方法。在该 start( ) 方法中会创建 ClientEndpoint ,在创建 ClientEndpoint的时候会传入 Command 来指定具体为当前应用程序启动的 Executor 进程的入口类的名称为 CoraseGraninedExecutorBackend,然后ClientEndpoint 启动并通过 tryRegisterMaster 来注册当前的应用程序到 Master 中。 Master 接受到注册信息后如何可以运行程序,则会为该程序生产JobID 并通过schedule 来分配计算资源,具体计算资源的分配是通过应用程序运行方式、Memory、cores 等配置来决定的,最后Master 会发送指令给Worker。 Worker 中为当前应用程序分配计算资源时会首先分配 ExecutorRunner,ExecutorRunner 内部会通过 Thread 的方式构成 ProcessBuilder 来启动另外一个 JVM 进程。 这个 JVM 进程启动时候会加载的 main 方法 所在的类的名称就是在创建 ClientEndpoint 时传入的 Command 来指定具体名称为 CoraseGraninedExecutorBackend 的类 。 此时JVM 在通过ProcessBuilder 启动的时候获得CoraseGraninedExecutorBackend 后加载并调用其中的main 方法,在main 方法中会实例化 CoraseGraninedExecutorBackend 本身这个消息循环体,而CoraseGraninedExecutorBackend 在实例化的时候会通过回调onStart( ) 向DriverEndpoint 发送 RegisterExecutor 来注册当前的CoraseGraninedExecutorBackend,此时DriverEndpiont 收到该注册信息并保存了SparkDeploySchedulerBackend 实例的内存的数据结构中,这样Driver 就获得了计算资源!(具体的代码流程可以参考Spark天堂之门解密的博客)
打通 Spark 系统运行内幕机制循环流程的更多相关文章
- [Spark内核] 第35课:打通 Spark 系统运行内幕机制循环流程
本课主题 打通 Spark 系统运行内幕机制循环流程 引言 通过 DAGScheduelr 面向整个 Job,然后划分成不同的 Stage,Stage 是從后往前划分的,执行的时候是從前往后执行的,每 ...
- 35.Spark系统运行内幕机制循环流程
一:TaskScheduler原理解密 1, DAGScheduler在提交TaskSet给底层调度器的时候是面向接口TaskScheduler的,这符合面向对象中依赖抽象而不依赖的原则,带来底层资 ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 2.Spark Streaming运行机制和架构
1 解密Spark Streaming运行机制 上节课我们谈到了技术界的寻龙点穴.这就像过去的风水一样,每个领域都有自己的龙脉,Spark就是龙脉之所在,它的龙穴或者关键点就是SparkStreami ...
- 【Spark 深入学习 04】再说Spark底层运行机制
本节内容 · spark底层执行机制 · 细说RDD构建过程 · Job Stage的划分算法 · Task最佳计算位置算法 一.spark底层执行机制 对于Spark底层的运行原理,找到了一副很好的 ...
- Spark Streaming运行流程及源码解析(一)
本系列主要描述Spark Streaming的运行流程,然后对每个流程的源码分别进行解析 之前总听同事说Spark源码有多么棒,咱也不知道,就是疯狂点头.今天也来撸一下Spark源码. 对Spark的 ...
- 通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制
本期内容: 1. Spark Streaming架构 2. Spark Streaming运行机制 Spark大数据分析框架的核心部件: spark Core.spark Streaming流计算. ...
- Linux硬件资源管理与外设设备使用、系统运行机制及用户管理
Linux硬件资源管理 PCI设备 显卡 $>>dmesg |grep -i vga[ 0.000000] Console: colour VG ...
- Spark基本运行流程
不多说,直接上干货! Spark基本运行流程 Application program的组成 Job : 包含多个Task 组成的并行计算,跟Spark action对应. Stage : Job 的调 ...
随机推荐
- iOS 系统架构及常用框架(iOS的系统架构分为四个层次)
1.iOS基于UNIX系统,因此从系统的稳定性上来说它要比其他操作系统的产品好很多 2.iOS的系统架构分为四层,由上到下一次为:可触摸层(Cocoa Touch layer).媒体层(Media l ...
- Orcale 之基本术语一
数据字典 数据字典是 Orcale 的重要组成部分.它有一系列的拥有数据库元数据信息的数据字典表和用户可以读取的数据字典视图组成,存放着数据库的有关信息.因此数据字典可以看作一组表和试图的集合.它们存 ...
- poj 2259 Team Queue
Team Queue Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 2977 Accepted: 1092 Descri ...
- Codeforces 639B——Bear and Forgotten Tree 3——————【构造、树】
Bear and Forgotten Tree 3 time limit per test 2 seconds memory limit per test 256 megabytes input st ...
- 【转】.net MVC 生命周期
对于Asp.net MVC,我对它的生命周期还是兴趣很浓,于是提出两个问题: 一个HTTP请求从IIS移交到Asp.net运行时,Asp.net MVC是在什么时机获得了控制权并对请求进行处理呢?处理 ...
- Ubuntu17.10下编译Openjdk8u
一开始笔者用的系统和软件版本都是最新的,导致编译了好几次都失败,最后找到解决的办法,现在记录一下编译及解决的方法 避免以后忘记 所用操作系统 Ubuntu17.10 所用软件及版本 make 3.8. ...
- 互联网轻量级框架SSM-查缺补漏第九天
简言: 第九章 Spring Ioc的概念 IoC(Inversion of Control)控制反转:比如想喝橙汁,在没有饮品店的日子,最直观的做法是买果汁机.橙汁.这是你自己“主动”创造的过程,也 ...
- C10K问题摘要
本文的内容是下面几篇文章阅读后的内容摘要: http://www.kegel.com/c10k.html (英文版) http://www.oschina.net/translate/c10k (中文 ...
- How to limit Dialog's max height?
1. We can make it to play trick in code. At Dialog's show function, after app has set contentView, w ...
- linux设置静态获取ip
vsphere client 创建虚拟机后,默认是动态获取ip ,如果想要改为静态ip: 修改网卡eth0 (不一定每个人都是eth0,比如有的是ens160) vim /etc/sysconfig/ ...