福大软工1816 · 第五次作业 - 结对作业2_map与unordered map的比较测试
测试代码:
#include <iostream>
using namespace std;
#include <string>
#include <windows.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <map>
const int maxval = 2000000 * 5;
#include <unordered_map>
void map_test()
{
printf("map_test\n");
map<int, int> mp;
clock_t startTime, endTime;
startTime = clock();
for (int i = 0; i < maxval; i++)
{
mp[rand() % maxval]++;
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("insert finish\n");
startTime = clock();
for (int i = 0; i < maxval; i++)
{
if (mp.find(rand()%maxval) == mp.end())
{
//printf("not found\n");
}
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("find finish\n");
startTime = clock();
for(auto it = mp.begin(); it!=mp.end(); it++)
{
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("travel finish\n");
printf("------------------------------------------------\n");
}
void hash_map_test()
{
printf("hash_map_test\n");
unordered_map<int, int> mp;
clock_t startTime, endTime;
startTime = clock();
for (int i = 0; i < maxval; i++)
{
mp[rand() % maxval] ++;
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("insert finish\n");
startTime = clock();
for (int i = 0; i < maxval; i++)
{
if (mp.find(rand() % maxval) == mp.end())
{
//printf("not found\n");
}
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("find finish\n");
startTime = clock();
for(auto it = mp.begin(); it!=mp.end(); it++)
{
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("travel finish\n");
printf("------------------------------------------------\n");
}
int main(int argc, char *argv[])
{
srand(0);
map_test();
Sleep(1000);
srand(0);
hash_map_test();
system("pause");
return 0;
}
详解:
map(使用红黑树)与unordered_map(hash_map)比较
map理论插入、查询时间复杂度O(logn)
unordered_map理论插入、查询时间复杂度O(1)
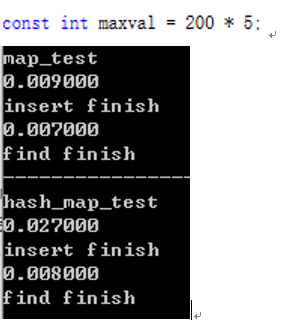
数据量较小时,可能是由于unordered_map(hash_map)初始大小较小,大小频繁到达阈值,多次重建导致插入所用时间稍大。(类似vector的重建过程)。
哈希函数也是有消耗的(应该是常数时间),这时候用于哈希的消耗大于对红黑树查找的消耗(O(logn)),所以unordered_map的查找时间会多余对map的查找时间。
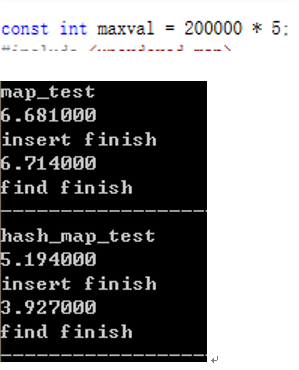
数据量较大时,重建次数减少,用于重建的开销小,unordered_map O(1)的优势开始显现
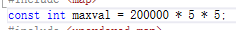
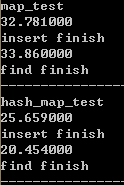
数据量更大,优势更明显
使用空间:


前半部分为map,后半部分为unordered_map
unordered_map占用的空间比map略多,但可以接受。
map和unordered_map内部实现应该都是采用达到阈值翻倍开辟空间的机制(16、32、64、128、256、512、1024……)浪费一定的空间是不可避免的。并且在开双倍空间时,若不能从当前开辟,会在其他位置开辟,开好后将数据移过去。数据的频繁移动也会消耗一定的时间,在数据量较小时尤为明显。
一种方法是手写定长开散列。这样做在数据量较小时有很好地效果(避免了数据频繁移动,真正趋近O(1))。但由于是定长的,在数据量较大时,数据重叠严重,散列效果急剧下降,时间复杂度趋近O(n)。
一种折中的方法是自己手写unordered_map(hash_map),将初始大小赋为一个较大的值。扩张可以模仿STL的双倍扩张,也可以自己采用其他方法。这样写出来的是最优的,但是实现起来极为麻烦。
综合利弊,我们组采用unordered_map。
附:使用Dev测试与VS2017测试效果相差极大???
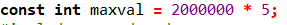
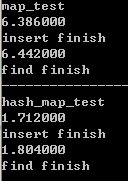
效率差了10倍???
原因:
Dev

VS2017

在Debug下,要记录断点等调试信息,的确慢。
Release:不对源代码进行调试,编译时对应用程序的速度进行优化,使得程序在代码大小和运行速度上都是最优的。
VS2017切到release后,还更快

除了前面说的Debug与release导致效率差异外,编译器的不同也会导致效率差异。
学到了。
福大软工1816 · 第五次作业 - 结对作业2_map与unordered map的比较测试的更多相关文章
- 福大软工1816 · 第五次作业 - 结对作业2_EXE图片_备用
1_每日推荐界面.png 2_论文搜索界面.png 2_论文搜索界面_搜索功能.png 3_流行趋势_十大热词排名统计图.png 4_人物界面.png 5_我的收藏界面.png 6_设置界面.png ...
- 福大软工1816:Alpha事后诸葛
福大软工·第十一次作业-Alpha事后诸葛亮 组长博客链接 本次作业博客链接 项目Postmortem 模板 设想和目标 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描 ...
- 福大软工1816 · 课程计划预报(K班)
实践课安排 对应教学周序 时间 内容 3 09.22 业界交流讲座 6 10.13 团队选题报告答辩 7 10.20 UML设计 8 10.27 团队项目需求答辩 11 11.17 团队现场编程实战与 ...
- 福大软工1816:Beta总结
第三视角Beta答辩总结 博客链接以及团队信息 组长博客链接 成员信息(按拼音排序) 姓名 学号 备注 张扬 031602345 组长 陈加伟 031602204 郭俊彦 031602213 洪泽波 ...
- 福大软工1816:Alpha(10/10)
Alpha 冲刺 (10/10) 队名:第三视角 组长博客链接 本次作业链接 团队部分 团队燃尽图 工作情况汇报 张扬(组长) 过去两天完成了哪些任务: 文字/口头描述: 1.和愈明.韫月一起对接 2 ...
- 福大软工1816:Beta(1/7)
Beta 冲刺 (1/7) 队名:第三视角 组长博客链接 本次作业链接 团队部分 团队燃尽图 工作情况汇报 张扬(组长) 过去两天完成了哪些任务 文字/口头描述 答辩 组织会议 复习课本 展示GitH ...
- 福大软工1816:Alpha(3/10)
Alpha 冲刺 (3/10) 队名:第三视角 组长博客链接 本次作业链接 团队部分 团队燃尽图 工作情况汇报 张扬(组长) 过去两天完成了哪些任务: 文字/口头描述: 1.学习qqbot库: 2.实 ...
- 福大软工1816 ·软工之404NoteFound团队选题报告
目录 NABCD分析引用 N(Need,需求): A(Approach,做法): B(Benefit,好处): C(Competitors,竞争): D(Delivery,交付): 初期 中期 个人贡 ...
- 福大软工1816 - 404 Note Found选题报告
目录 NABCD分析引用 N(Need,需求): A(Approach,做法): B(Benefit,好处): C(Competitors,竞争): D(Delivery,交付): 初期 中期 个人贡 ...
随机推荐
- CSS动画详解及transform、transition、translate的区别
刚看完一节慕课网的css动画,在此总结下 1. 先说下 transform.transition.translate的区别 transform 和 transition是css的2个属性,transl ...
- 【Hadoop故障处理】高可用(HA)环境DataNode问题
[故障背景] NameNode和DataNode进程正常运行,但是网页找不到DataNode,DataNode为空.各个节点机器之间可以ping同主机名. [日志排查] 众多日志中找到如下关键点错误信 ...
- 一、linux基本操作
1.linux界面的切换 DOS界面终端打开:Ctrl+Alt+F1 /F2/F3 退出:Ctrl+Alt+F7 终端的打开与退出 打开:Ctrl+Alt+t 退出:Ctrl+d 2.第一次 ...
- C语言之一般树
1.一般树 将这种一般的树转化成我们熟悉的单链表形式,这有三层,每一层都可以看成单链表或者多个分散的单链表 数据节点如下: struct tree { int elem; ...
- MFC实现http连接、发送和接收数据
#include <afxinet.h> // 设置超时 CInternetSession session; session.SetOption(INTERNET_OPTION_CONNE ...
- Qt :undefined reference to vtable for "xxx::xxx"
现象: 类加上宏 Q_OBJECT 就会报错 :undefined reference to vtable for "xxx::xxx" 解决方法: 重新 qmake 其他情况,查 ...
- 20145202马超《java》【课堂实验】P98测试
当时在加水印所以没来得及提交,然而我回宿舍第一时间就提交了,希望老师额能够看到
- LeetCode:33. Search in Rotated Sorted Array(Medium)
1. 原题链接 https://leetcode.com/problems/search-in-rotated-sorted-array/description/ 2. 题目要求 给定一个按升序排列的 ...
- mysql c 获取error_code
#include <stdio.h> #include <mysql.h> int main(int argc, char **argv) { MYSQL *con = mys ...
- Matlab2018年最新视频教程视频讲义(包含代码)
2018年Matlab最新视频教程视频讲义(包含代码),适合初学者入门进阶学习,下载地址:百度网盘, https://pan.baidu.com/s/1w4h297ua6ctzfturQ1791g 内 ...