{转}用ADMM求解大型机器学习问题
从等式约束的最小化问题说起:  上面问题的拉格朗日表达式为:
上面问题的拉格朗日表达式为: 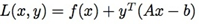 也就是前面的最小化问题可以写为: minxmaxyL(x,y) 。 它对应的对偶问题为: maxyminxL(x,y) 。 下面是用来求解此对偶问题的对偶上升迭代方法:
也就是前面的最小化问题可以写为: minxmaxyL(x,y) 。 它对应的对偶问题为: maxyminxL(x,y) 。 下面是用来求解此对偶问题的对偶上升迭代方法: 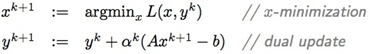 这个方法在满足一些比较强的假设下可以证明收敛。
这个方法在满足一些比较强的假设下可以证明收敛。
为了弱化对偶上升方法的强假设性,一些研究者在上世纪60年代提出使用扩展拉格朗日表达式(augmented Lagrangian)代替原来的拉格朗日表达式: 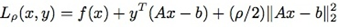 其中ρ>0。对应上面的对偶上升方法,得到下面的乘子法(method of multipliers):
其中ρ>0。对应上面的对偶上升方法,得到下面的乘子法(method of multipliers): 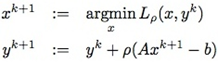
注意,乘子法里把第二个式子里的αk改成了扩展拉格朗日表达式中引入的ρ。这不是一个随意行为,而是有理论依据的。利用L(x,y)可以导出上面最小化问题对应的原始和对偶可行性条件分别为(∂L∂y=0,∂L∂x=0): 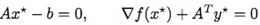 既然xk+1 最小化 Lρ(x,yk),有:
既然xk+1 最小化 Lρ(x,yk),有: 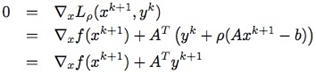 上面最后一个等式就是利用了yk+1=yk+ρ(Axk+1−b)。从上面可知,这种yk+1的取法使得(xk+1,yk+1)满足对偶可行条件∂L∂x=0。而原始可行条件在迭代过程中逐渐成立。
上面最后一个等式就是利用了yk+1=yk+ρ(Axk+1−b)。从上面可知,这种yk+1的取法使得(xk+1,yk+1)满足对偶可行条件∂L∂x=0。而原始可行条件在迭代过程中逐渐成立。
乘子法弱化了对偶上升法的收敛条件,但由于在x-minimization步引入了二次项而导致无法把x分开进行求解(详见[1])。而接下来要讲的最小化Lρ(xk+1,z,yk): 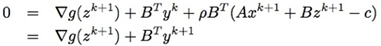 其中用到了z对应的对偶可行性式子: ∂L∂z=∇g(z)+BTy=0
其中用到了z对应的对偶可行性式子: ∂L∂z=∇g(z)+BTy=0
定义新变量u=1ρy,那么(3.2-3.4)中的迭代可以变为以下形式: 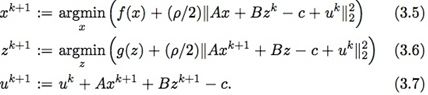 在真正求解时通常会使用所谓的over-relaxation方法,也即在z和u中使用下面的表达式代替其中的Axk+1: αkAxk+1−(1−αk)(Bzk−c), 其中αk为relaxation因子。有实验表明αk∈[1.5,1.8]可以改进收敛性([2])。
在真正求解时通常会使用所谓的over-relaxation方法,也即在z和u中使用下面的表达式代替其中的Axk+1: αkAxk+1−(1−αk)(Bzk−c), 其中αk为relaxation因子。有实验表明αk∈[1.5,1.8]可以改进收敛性([2])。
下面让我们看看ADMM怎么被用来求解大型的机器学习模型。所谓的大型,要不就是样本数太多,或者样本的维数太高。下面我们只考虑第一种情况,关于第二种情况感兴趣的读者可以参见最后的参考文献[1, 2]。样本数太多无法一次全部导入内存,常见的处理方式是使用分布式系统,把样本分块,使得每块样本能导入到一台机器的内存中。当然,我们要的是一个最终模型,它的训练过程利用了所有的样本数据。常见的机器学习模型如下: minimize x∑Jj=1fj(x)+g(x), 其中x为模型参数,fj(x)对应第j个样本的损失函数,而g(x)为惩罚系数,如g(x)=||x||1。
假设把J个样本分成N份,每份可以导入内存。此时我们把上面的问题重写为下面的形式: 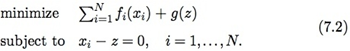 除了把目标函数分成N块,还额外加了N个等式约束,使得利用每块样本计算出来的模型参数xi都相等。那么,ADMM中的求解步骤(3.2)-(3.4)变为:
除了把目标函数分成N块,还额外加了N个等式约束,使得利用每块样本计算出来的模型参数xi都相等。那么,ADMM中的求解步骤(3.2)-(3.4)变为: 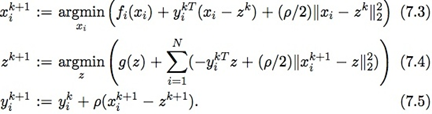 例如求解L1惩罚的LR模型,其迭代步骤如下(u=1ρy,g(z)=λ||z||1):
例如求解L1惩罚的LR模型,其迭代步骤如下(u=1ρy,g(z)=λ||z||1): 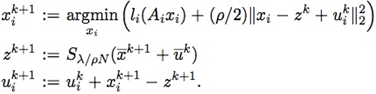 其中x¯≐1N∑Nixi,y¯的定义类似。
其中x¯≐1N∑Nixi,y¯的定义类似。
在分布式情况下,为了计算方便通常会把u的更新步骤挪在最前面,这样u和x的更新可以放在一块: 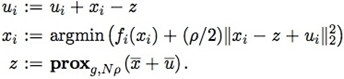
ADMM的框架确实很牛逼,把一个大问题分成可分布式同时求解的多个小问题。理论上,ADMM的框架可以解决大部分实际中的大尺度问题。我自己全部实现了一遍这个框架,主要用于求解LR问题,下面说说我碰到的一些问题: 1. 收敛不够快,往往需要迭代几十步。整体速度主要依赖于xi更新时所使用的优化方法,个人建议使用liblinear里算法,但是不能直接拿来就用,需要做一些调整。 2. 停止准则和ρ的选取:停止准则主要考量的是xi和z之间的差异和它们本身的变动情况,但这些值又受ρ的取值的影响。它们之间如何权衡并无定法。个人建议使用模型在测试集上的效果来确定是否停止迭代。 3. 不适合MapReduce框架实现:需要保证对数据的分割自始至终都一致;用MPI实现的话相对于其他算法又未必有什么优势(如L-BFGS、OwLQN等)。 4. relaxation步骤要谨慎:α的取值依赖于具体的问题,很多时候的确可以加快收敛速度,但对有些问题甚至可能带来不收敛的后果。用的时候不论是用x -> z -> u的更新步骤,还是用u -> x -> z的更新步骤,在u步使用的x_hat要和在z步使用的相同(使用旧的z),而不是使用z步刚更新的z重算。 5. warm start 和子问题求解逐渐精确的策略可以降低xi更新时的耗时,但也使得算法更加复杂,需要设定的参数也增加了。
[References] [1] S. Boyd. Alternating Direction Method of Multipliers (Slides).
[2] S. Boyd et al. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers, 2010
{转}用ADMM求解大型机器学习问题的更多相关文章
- 用ADMM求解大型机器学习问题
[本文链接:http://www.cnblogs.com/breezedeus/p/3496819.html,转载请注明出处] 从等式约束的最小化问题说起: ...
- 协同ADMM求解考虑碳排放约束直流潮流问题的对偶问题(A Distributed Dual Consensus ADMM Based on Partition for DC-DOPF with Carbon Emission Trading)
协同ADMM求解考虑碳排放约束直流潮流问题的对偶问题 (A Distributed Dual Consensus ADMM Based on Partition for DC-DOPF with Ca ...
- 100个大型机器学习数据集汇总(CV/NLP/音频方向)
网站首页: 网址:数据集
- ADMM与one-pass multi-view learning
现在终于开始看论文了,机器学习基础部分的更新可能以后会慢一点了,当然还是那句话宁愿慢点,也做自己原创的,自己思考的东西.现在开辟一个新的模块----多视图学习相关论文笔记,就是分享大牛的paper,然 ...
- 对偶上升法到增广拉格朗日乘子法到ADMM
对偶上升法 增广拉格朗日乘子法 ADMM 交替方向乘子法(Alternating Direction Method of Multipliers,ADMM)是一种解决可分解凸优化问题的简单方法,尤其在 ...
- cuda并行编程之求解ConjugateGradient(共轭梯度迭代)丢失dll解决方式
在进行图像处理过程中,我们常常会用到梯度迭代求解大型线性方程组.今天在用cuda对神秘矩阵进行求解的时候.出现了缺少dll的情况: 报错例如以下图: watermark/2/text/aHR0cDov ...
- MapReduce: 一种简化的大规模集群数据处理法
(只有文字没有图,图请参考http://research.google.com/archive/mapreduce.html) MapReduce: 一种简化的大规模集群数据处理法 翻译:风里来雨里去 ...
- MATLAB学习笔记(七)——MATLAB解方程与函数极值
(一)线性方程组求解 包含n个未知数,由n个方程构成的线性方程组为: 其矩阵表示形式为: 其中 一.直接求解法 1.左除法 x=A\b; 如果A是奇异的,或者接近奇异的.MATLAB会发出警告信息的. ...
- [Reinforcement Learning] Value Function Approximation
为什么需要值函数近似? 之前我们提到过各种计算值函数的方法,比如对于 MDP 已知的问题可以使用 Bellman 期望方程求得值函数:对于 MDP 未知的情况,可以通过 MC 以及 TD 方法来获得值 ...
随机推荐
- Swift-(OC中的enumerateObjectsUsingBlock跟Swift的enumerate区别)
OC中使用: NSArray * lists = [NSArray array]; [lists enumerateObjectsUsingBlock:^(id _Nonnull obj, NSUI ...
- TCP系列05—连接管理—4、TCP连接的ISN、连接建立超时及TCP的长短连接
一.TCP连接的ISN 之前我们说过初始建立TCP连接的时候的系列号(ISN)是随机选择的,那么这个系列号为什么不采用一个固定的值呢?主要有两方面的原因 防止同一个连接的不同实例(di ...
- windows网络模型
Windows提供了四种异步IO技术,机制几乎时相同的,区别在于通知结果的方式不同: 1.通过注册的消息函数进行通知 2.通过内核event事件进行通知 3.通过称为完成例程的回调函数进行通知 4.通 ...
- C++基础知识(一)
C++中头文件中class的两个花括号后面要加上分号,否则会出现很多的莫名奇妙的错误. 一. 每一个C++程序(或者由多个源文件组成的C++项目)都必须包含且只有一个main()函数.对于预处理指令, ...
- 使用Xcode进行调试
目录 知己知彼 百战不殆抽刀断Bug 普通操作 全局断点(Global BreakPoint) 条件断点(Condational Breakpoints)打印的艺术 NSLog 开启僵尸对象(Enab ...
- JS作用域-面向对象
1. 其它语言是以代码块作为作用域的.下面程序会报错(如C,C++中),因为局部变量name只在{ }代码块中生效.打印console.writeline(name)中的name时就会报错. pu ...
- 【题解】CF#24 D-Broken Robots
在某次考试的时候用过的办法,懒人必备……[笑哭] 一个非常显然的 dp,我们用 \(f[i][j]\) 表示第 \(i\) 行第 \(j\) 列的格子走到最后一排的期望步数转移即为 \(f[i][j] ...
- [洛谷P1341]无序字母对
题目大意:给一张无向图,找一条字典序最小的欧拉路径 题解:若图不连通或有两个以上的奇数点,则没有欧拉路径,可以$dfs$,在回溯时把这个节点加入答案 卡点:没有在回溯时加入答案,导致出现了欧拉路径没走 ...
- BZOJ4650:[NOI2016]优秀的拆分——题解
https://www.lydsy.com/JudgeOnline/problem.php?id=4650 https://www.luogu.org/problemnew/show/P1117 如果 ...
- [Leetcode] minimum window substring 最小字符窗口
Given a string S and a string T, find the minimum window in S which will contain all the characters ...