elasticsearch + hive环境搭建
一、环境介绍:
elasticsearch:2.3.1
hive:0.12
二、环境搭建
2.1 首先获取elasticsearc-hadoop的jar包
链接地址:http://jcenter.bintray.com/org/elasticsearch/elasticsearch-hadoop/2.3.1/elasticsearch-hadoop-2.3.1.jar,下载即可。需要说明的是你的elasticsearch什么版本,那么elasticsearch-hadoop的jar包就什么版本,否则后果难料
2.2 hive集成elasticsearch
将elasticsearch-hadoop-2.3.1.jar拷贝到hive的默认lib目录即可。我的目录是:$HIVE_HOME/auxlib目录
启动hive,查看效果:
/home/q/java/default/bin/java -Xmx256m -Djava.net.preferIPv4Stack=true *** -hiveconf hive.aux.jars.path=file:///home/q/hive/hive-0.12.0-bin/auxlib/elasticsearch-hadoop-2.0.1.jar
只要包含了上面的红色部分说明集成成功
三、插入数据
3.1 建立数据表
3.1.1 建立view表
CREATE EXTERNAL TABLE user (id INT, name STRING)
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES('es.resource' = 'radiott/artiststt','es.index.auto.create' = 'true','es.nodes' = 'elastisticsearch.*.qunar.com','es.port' = '');
有几个参数,es.nodes是配置的es的url地址,默认是localhost。es.port是端口号码,默认是9200
3.1.2 建立数据表
CREATE TABLE user_source (id INT, name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
3.2 加载数据
3.2.1 加载基础数据
数据示例,我放在/tmp/user_source.log
1,medcl
2,lcdem
3,tom
4,jack
加载到user_source表,命令如下:LOAD DATA LOCAL INPATH '/tmp/user_source.log' OVERWRITE INTO TABLE user_source;
3.2.2 加载到es
INSERT OVERWRITE TABLE user SELECT s.id, s.name FROM user_source s;
查看效果:
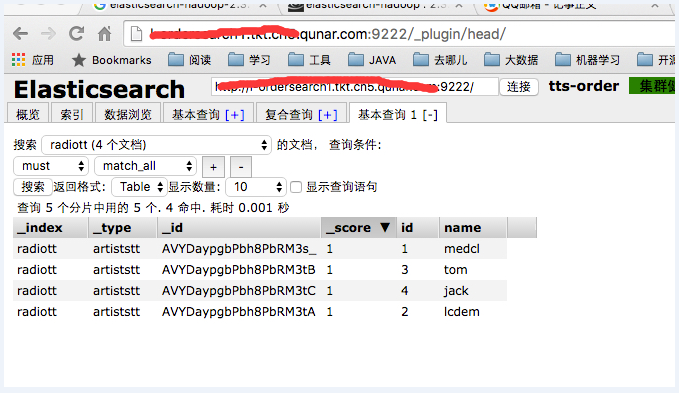
四、参考文档:
http://blog.csdn.net/sunflower_cao/article/details/39896189
https://www.elastic.co/guide/en/elasticsearch/hadoop/current/configuration.html#_essential_settings
elasticsearch + hive环境搭建的更多相关文章
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 《Programming Hive》读书笔记(一)Hadoop和hive环境搭建
<Programming Hive>读书笔记(一)Hadoop和Hive环境搭建 先把主要的技术和工具学好,才干更高效地思考和工作. Chapter 1.Int ...
- Hive环境搭建
hive 环境搭建需要hadoop的环境.hadoop环境的搭建不在这里赘述.参考:http://www.cnblogs.com/parkin/p/6952370.html 1.准备阶段 hive 官 ...
- Spark环境搭建(四)-----------数据仓库Hive环境搭建
Hive产生背景 1)MapReduce的编程不便,需通过Java语言等编写程序 2) HDFS上的文缺失Schema(在数据库中的表名列名等),方便开发者通过SQL的方式处理结构化的数据,而不需要J ...
- Hadoop生态圈-Hive快速入门篇之Hive环境搭建
Hadoop生态圈-Hive快速入门篇之Hive环境搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据仓库(理论性知识大多摘自百度百科) 1>.什么是数据仓库 数据 ...
- Hive环境搭建和SparkSql整合
一.搭建准备环境 在搭建Hive和SparkSql进行整合之前,首先需要搭建完成HDFS和Spark相关环境 这里使用Hive和Spark进行整合的目的主要是: 1.使用Hive对SparkSql中产 ...
- Hive——环境搭建
Hive--环境搭建 相关hadoop和mysql环境已经搭建好.我博客中也有相关搭建的博客. 一.下载Hive并解压到指定目录(本次使用版本hive-1.1.0-cdh5.7.0,下载地址:http ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 转载 Elasticsearch开发环境搭建(Eclipse\MyEclipse + Maven)
概要: 1.使用Eclipse搭建Elasticsearch详情参考下面链接 2.Java Elasticsearch 配置 3.ElasticSearch Java Api(一) -添加数据创建索引 ...
随机推荐
- sqlhelper sqlparameter 实现增删改查
这是sqlHelper.cs类,类内里封装了方法 using System; using System.Collections.Generic; using System.Linq; using Sy ...
- Oracle数据创建表空间
一.直接在服务器端通过sqlplus命令行创建: 如果您用的是Linux系统,那么Oracle用户名为oracle.同时,您是在oracle服务器上操作. 如果是在Windows系统下, 请先点击“开 ...
- css之 斜线
.x { border: solid 1px red; width: 100px; height: 100px; position: relative; background-color: trans ...
- Ora-01536:超出了表空间users的空间限量(转)
Ora-01536:超出了表空间users的空间限量(转) 正在开会,同事跑过来说数据库有问题,通讯程序不能入库,赶快获取一条insert into a values()语句后在toad工具中手动插入 ...
- Linux:Linux 重要人物
1.Ken Thompson:C 语言之父和 UNIX 之父 2.Dennis Ritchie:C 语言之父和 UNIX 之父 3.Stallman:著名黑客,GNU 创始人,开发了 Emacs.gc ...
- PAAS平台构建7×24小时高可用应用的方案设计
本博客迁移到部署在jae上的独立博客系统wordpress,博客地址:点击打开独立博客.欢迎大家一起来讨论IT技术. 现在很多企业都在搭建自己的私有PAAS平台,当然也有很多大型互联网公司搭建共有PA ...
- C++ 用于大型程序的工具
<C++ Primer 4th>读书笔记 相对于小的程序员团队所能开发的系统需求而言,大规模编程对程序设计语言的要求更高.大规模应用程序往往具有下列特殊要求: 1. 更严格的正常运转时间以 ...
- piap.excel 微软 时间戳转换mssql sql server文件时间戳转换unix 导入mysql
piap.excel 微软 时间戳转换mssql sql server文件时间戳转换unix 导入mysql 需要不个mssql的sql文件导入mysql.他们的时间戳格式不同..ms用的是自定义的时 ...
- nodejs学习之表单提交(1)
nodejs作为一门后端语言,接触的最多的是它的框架,但是它本身的api我觉得更是非学不可,所有才有了这篇文章 表单提交是最基本的也是最实用的入门实例 HTML: <!DOCTYPE html& ...
- JAVA “Run as administrator” “UAC disabled” alternative solution
Technorati 标签: psexec,run as administrator,UAC java.io.IOException: Cannot run program "psexec. ...