springcloud --- spring cloud sleuth和zipkin日志管理(spring boot 2.18)
前言
在spring cloud分布式架构中,系统被拆分成了许多个服务单元,业务复杂性提高。如果出现了异常情况,很难定位到错误位置,所以需要实现分布式链路追踪,跟进一个请求有哪些服务参与,参与的顺序如何,从而去明确一个问题。
spring cloud sleuth
通常来说,一个分布式服务跟踪系统主要由三部分:数据收集、数据存储和数据展示。
对于大规模的分布式系统来说,数据存储可分为实时数据和全量数据两部分。实时数据用来排查故障,全量数据用于系统优化;数据展示涉及数据挖掘和分析。
- 名词解释
服务追踪的追踪单元是从客户端发起请求抵达被追踪的系统边界开始,到被追踪的边界开始,到被追踪的紫铜向客户返回响应为止的过程,称呼为一个 "trace"。每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的响应时间等信息,在调用每个服务时,都会迈入一个调用记录,成为一个 "span"。如此,若干个有序的 span 就组成了一个 trace。
在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace,把这些带有span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务;根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
spring cloud sleuth 为服务之间提供链路追踪。我们可以清楚的认识到一个请求经过了哪些服务,每个服务处理花了多长时间,理清服务之间的调用关系和顺序
spring cloud sleuth 主要提供了数据收集部分功能,因此需要结合 zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。
zipkin
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,主要用于数据的存储、查找和展示。 zipkin 提供了可拔插数据存储方式,生产环境中推荐使用 Elasticsearch,还能结合 kibana 使用。
Zipkin 和 Config 结构类似,分为服务端 Server,客户端Client,客户端就是各个微服务应用。
具体使用
zipkin-server服务端
在Spring boot 2.0版本之后,官方不再推荐支持自己搭建服务,而是直接提供编译好的jar包,直接运行jar包,启动服务,非常方便。还有docker启动,Running from Source等,具体的可以在官网查看,链接:https://zipkin.io/pages/quickstart.html
Docker方式(quickest)
docker run -d -p 9411:9411 openzipkin/zipkin
java(终端命令模式)
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
备注:必须环境为java8及其以上。jar包下载地址:https://search.maven.org/remote_content?g=io.zipkin&a=zipkin-server&v=LATEST&c=exec
运行
浏览器启动地址http://localhost:9411/zipkin/,成功之后看到如下界面
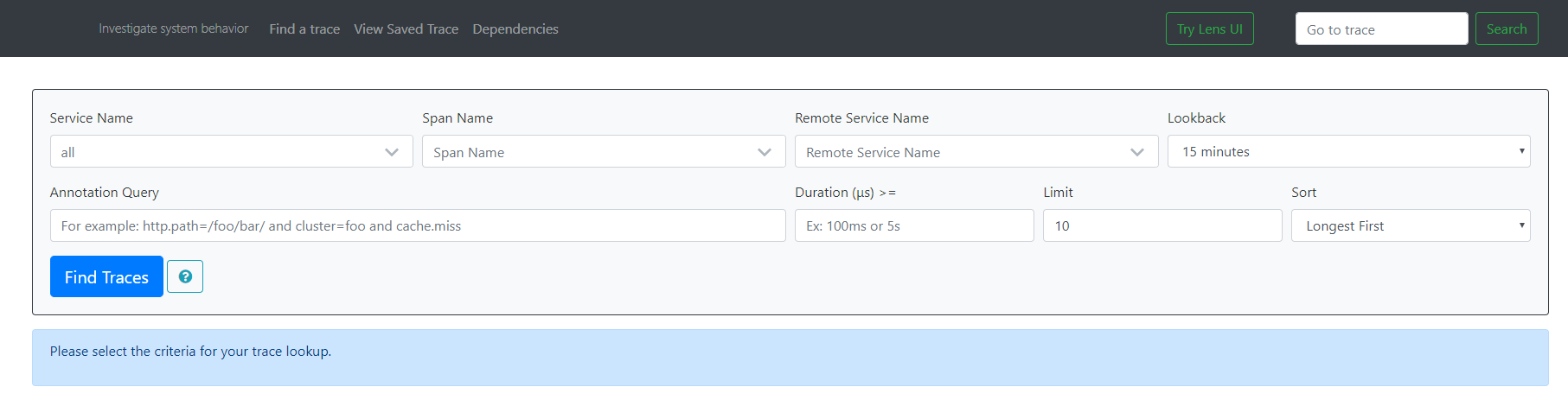
客户端
项目依赖(maven)
- 仅仅使用Spring Cloud Sleuth,不包含Zipkin
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
- 同时使用Spring Cloud Sleuth + Zipkin(HTTP查看)
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
- 使用RabbitMQ或Kafka而不是HTTP
如果使用Kafka,则必须相应地设置property spring.zipkin.sender.type属性:
spring.zipkin.sender.type: kafka
注意:
spring-cloud-sleuth-stream已不推荐使用,现已不兼容。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
详情见官网:https://cloud.spring.io/spring-cloud-sleuth/reference/html/#sleuth-adding-project
- 实例
在所有服务中引入
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
</dependencies>
Spring应用在监测到Java依赖包中有sleuth和zipkin后,会自动在RestTemplate的调用过程中向HTTP请求注入追踪信息,并向Zipkin Server发送这些信息。
配置文件(建议application.yml)
server:
port: 9400
spring:
application:
name: zipkin-server
zipkin:
base-url: http://ivms.io:9411
sender:
type: web
sleuth:
sampler:
probability: 0.1
rate: 2
eureka:
client:
serviceUrl:
defaultZone: http://192.168.2.42:8761/eureka/
logging:
level:
root: debug
Spring Cloud Sleuth有一个Sampler策略,可以通过这个实现类来控制采样算法。默认采样率为0.1,即10%,这里设置 1.0,全部采样。
注意一下,版本不同,所使用的配置也不同。sender.type需要手动指定,默认是rabbitmq,不然会导致zipkin界面没有客户端连接。还有sleuth.sampler中的percentage现在也变成了rate,要注意,之后也可能会再变化,跟着版本走,别人的例子都是参考一个大致方向
启动服务
然后把测试服务启动,随便请求一个接口
- 控制台输出

会发现有这样子的东西打印,这是好事,证明追踪到了请求记录。解释一下:
第一个值
zipkin-client1,记录了应用的名称第二个
a942e108d3baceb8,是 Spring Cloud Sleuth 生成的一个 ID,称为 Trace ID,它用来标识一条请求链路。一条请求链路中包含一个 Trace ID,多个 Span ID。(上面说过了)第三个就是
spanID了,它表示一个基本的工作单元,比如发送一个 HTTP 请求。true代表是否要将该信息输出到 Zipkin Server 中来收集和展示。因为我们设置了采集率1.0,所以自然是true
- zaipkin UI展示
然后就看一下浏览器显示什么吧,打开 http://localhost:9411/zipkin/
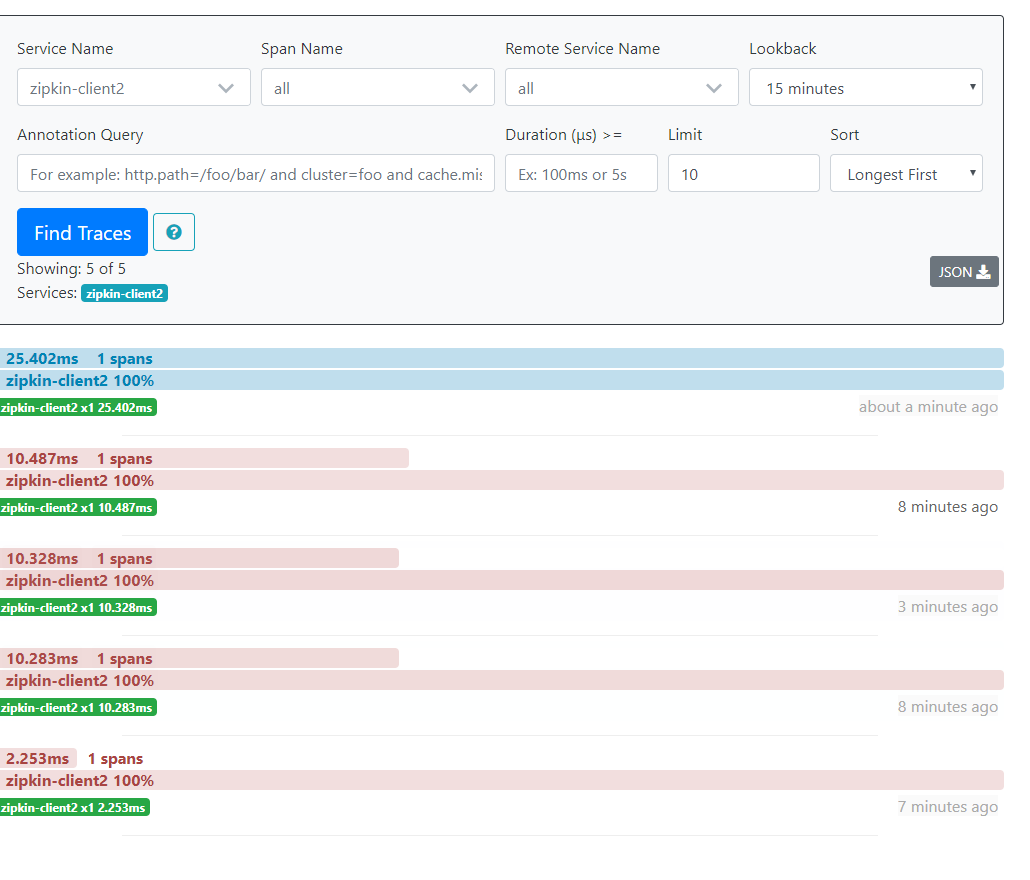
可以看到Service Name中多了一个东西 zipkin-client1(我的服务名,这不是什么专业名词哈),然后点击 Find Traces 就可以看到一条服务调用记录
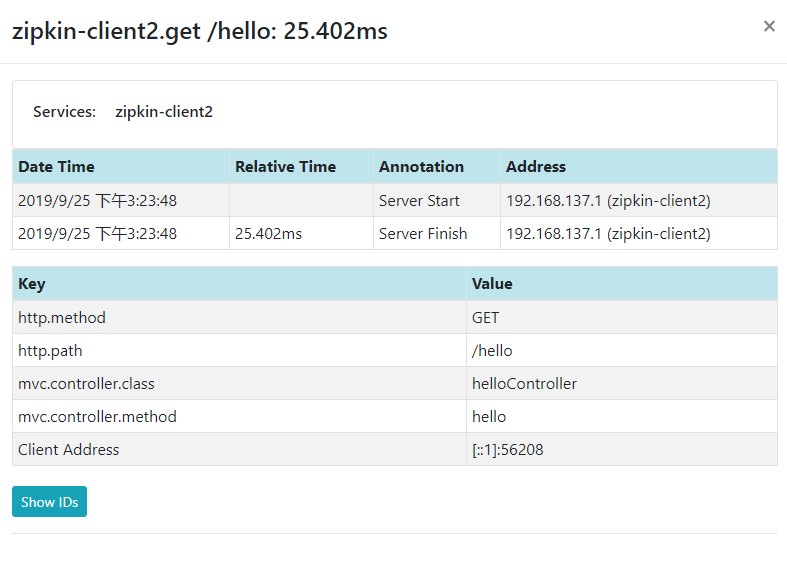
可以看到上面显示了服务调用耗时,请求数量,是否成功,然后点击记录可以看到服务调用链路关系,点击依赖分析可以看到服务之间的依赖关系,自己尝试一下
结语:很简单,但我花了两天,因为升级之后完全大改,网上也没有资料,只能去看官网文档,更坑的是中文网和官网写的不一样(对比spring cloud sleuth),摊手。之后会结合 gateway、ELK 实践一下,缘分更新。
springcloud --- spring cloud sleuth和zipkin日志管理(spring boot 2.18)的更多相关文章
- 跟我学SpringCloud | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
SpringCloud系列教程 | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪 Springboot: 2.1.6.RELEASE SpringCloud: ...
- Spring Cloud Sleuth 和 Zipkin 进行分布式跟踪使用指南
分布式跟踪允许您跟踪分布式系统中的请求.本文通过了解如何使用 Spring Cloud Sleuth 和 Zipkin 来做到这一点. 对于一个做所有事情的大型应用程序(我们通常将其称为单体应用程序) ...
- Distributed traceability with Spring Cloud: Sleuth and Zipkin
I. Sleuth 0. Concept Trace A set of spans that form a call tree structure, forms the trace of the re ...
- spring cloud 入门系列八:使用spring cloud sleuth整合zipkin进行服务链路追踪
好久没有写博客了,主要是最近有些忙,今天忙里偷闲来一篇. =======我是华丽的分割线========== 微服务架构是一种分布式架构,微服务系统按照业务划分服务单元,一个微服务往往会有很多个服务单 ...
- Spring Cloud sleuth with zipkin over RabbitMQ教程
文章目录 Spring Cloud sleuth with zipkin over RabbitMQ demo zipkin server的搭建(基于mysql和rabbitMQ) 客户端环境的依赖 ...
- springcloud(十二):使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位 ...
- 【spring cloud】spring cloud Sleuth 和Zipkin 进行分布式链路跟踪
spring cloud 分布式微服务架构下,所有请求都去找网关,对外返回也是统一的结果,或者成功,或者失败. 但是如果失败,那分布式系统之间的服务调用可能非常复杂,那么要定位到发生错误的具体位置,就 ...
- 使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
原文:http://www.cnblogs.com/ityouknow/p/8403388.html 随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成, ...
- spring cloud深入学习(十三)-----使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位 ...
随机推荐
- 背包形动态规划 fjutoj2375 金明的预算方案
金明的预算方案 TimeLimit:1000MS MemoryLimit:128MB 64-bit integer IO format:%lld Problem Description 金明今天 ...
- Codeforces Round #383 (Div. 2)D. Arpa's weak amphitheater and Mehrdad's valuable Hoses(dp背包+并查集)
题目链接 :http://codeforces.com/contest/742/problem/D 题意:给你n个女人的信息重量w和美丽度b,再给你m个关系,要求邀请的女人总重量不超过w 而且如果邀请 ...
- CF985C Liebig's Barrels 贪心 第二十
Liebig's Barrels time limit per test 2 seconds memory limit per test 256 megabytes input standard in ...
- hadoop之数据倾斜
数据倾斜介绍 在做Shuffle阶段的优化过程中,遇到了数据倾斜的问题,造成了对一些情况下优化效果不明显.主要是因为在Job完成后的所得到的Counters是整个Job的总和,优化是基于这些Count ...
- 第二章(Kotlin基础)
基本要素:函数和变量 函数 函数定义规则 函数通过关键字 fun 用来声明一个函数 参数的类型与函数返回类型写在它的名称后面,这和变量声明一样 函数可以定义在文件的最外层,不一定要把它放在类中 示例: ...
- Android源码阅读技巧--查找开发者选项中显示触摸操作源码
在开发者模式下,在开发者选项中,可以勾选“显示触摸操作”,然后只要点击屏幕就会在点击的位置有圈圈显示.如何找到绘制圈圈的代码部分,有什么技巧来阅读代码量这么大的android系统源码呢?以下请跟着小老 ...
- 去重合并两个有序链表之直接操作和Set集合操作
两者思路对比: 直接操作:因为传入的是两个有序的链表,所以说我就直接以其中一个链表为基准,与另外一个链表比较,只将比返回值链表的最后一个记录的值大的插入,不将等值的插入,理论时间复杂度为O(n) Se ...
- 多场景抢红包业务引发.NETCore下使用适配器模式实现业务接口分离
事情的起因 我们公司现有一块业务叫做抢红包,最初的想法只是实现了一个初代版本,就是给指定的好友单发红包,随着业务的发展,发红包和抢红包的场景也越来越多,目前主要应用的场景有:单聊发红包.群聊发红包.名 ...
- Redis集群增加节点和删除节点
本文主要是承接上一篇文章Redis集群的离线安装成功以后,我们如何进行给集群增加新的主从节点(集群扩容)以及如何从集群中删除节点(集群缩容),也就是集群的伸缩,集群伸缩的原理是控制虚拟槽和数据在节点之 ...
- 【学习笔记】python3核心技术与实践--如何逐步突破,成为python高手
众所周知,Facebook 的主流语言是 Hack(PHP 的进化版本).不过,我敢拍着胸脯说,就刚入职的工程师而言,100 个里至少有 95 个,以前都从未用过 Hack 或者 PHP.但是,这些人 ...