Python爬虫之小试牛刀——使用Python抓取百度街景图像
之前用.Net做过一些自动化爬虫程序,听大牛们说使用python来写爬虫更便捷,按捺不住抽空试了一把,使用Python抓取百度街景影像。
这两天,武汉迎来了一个德国总理默克尔这位大人物,又刷了一把武汉长江大桥,今天就以武汉长江大桥为例,使用Python抓取该位置的街景影像。

百度街景URL分析
基于http抓包工具,可以很轻松的获取到浏览百度街景时的http请求数据。如下图所示,即是长江大桥某位置点街景影像切片:

该切片对应的URL请求为:
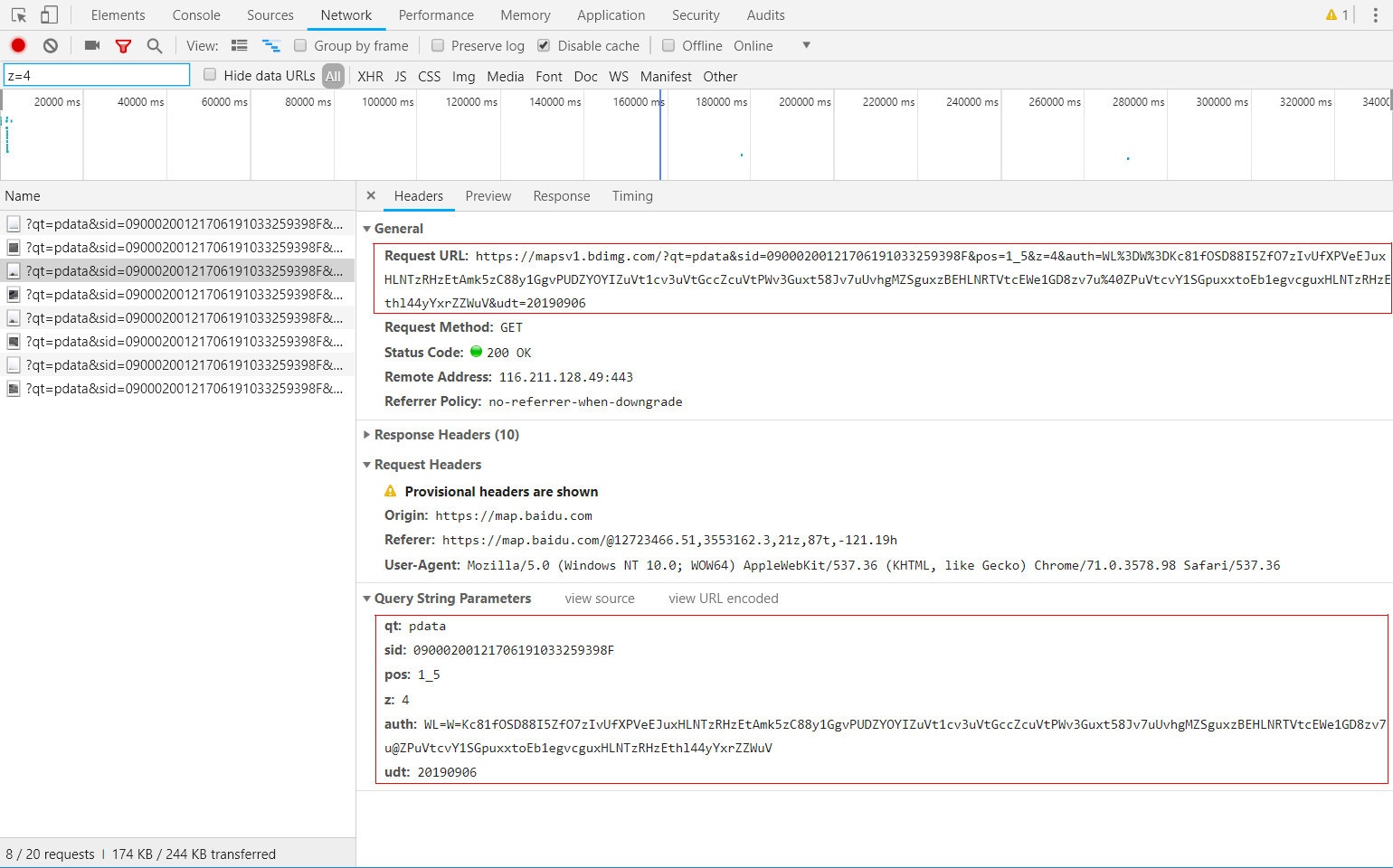
细致分析该URL请求,并经过模拟测试,可以总结出如下初步结论
请求影像切片所需的几个关键参数分别为:
① sid:代表某个具体的街景点位;
② pos:代表该切片在完整的全景影像图上的切片坐标;
③ z:代表街景影像切片级别。
单个位置的街景影像图可以生产出多种级别的切片,不同的级别下,切片的数量是不同的;切片的坐标使用行号、列号予以区分。
明确了以上百度街景影像的切片规则,就可以用代码开撸了。
Python源码
要求:一次性抓取连续10个全景点的所有级别切片信息。
源码如下:
import urllib2
import threading
from optparse import OptionParser
# from bs4 import BeautifulSoup
import sys
import re
import urlparse
import Queue
import hashlib
import os def download(url, path, name):
conn = urllib2.urlopen(url)
if not os.path.exists(path):
os.makedirs(path)
f = open(path + name, 'wb')
f.write(conn.read())
f.close() fp = open("E:\\Workspaces\\Python\\panolist.txt", "r")
for line in fp.readlines():
line = (lambda x: x[1:-2])(line)
# url = line
for zoom in range(1, 6):
row_max = 0
col_max = 0
row_max = pow(2, zoom - 2) if zoom > 1 else 1
col_max = pow(2, zoom - 1)
for row in range(row_max):
for col in range(col_max):
z = str(zoom)
y = str(row)
x = str(col)
print(y + "_" + x)
url = line + "&pos=" + y + "_" + x + "&z=" + z
path = "E:\\Workspaces\\Python\\pano\\" + url.split('&')[1].split('=')[1] + "\\" + z + "\\"
name = y + "_" + x + ".jpg"
print url
print name
download(url, path, name)
fp.close()
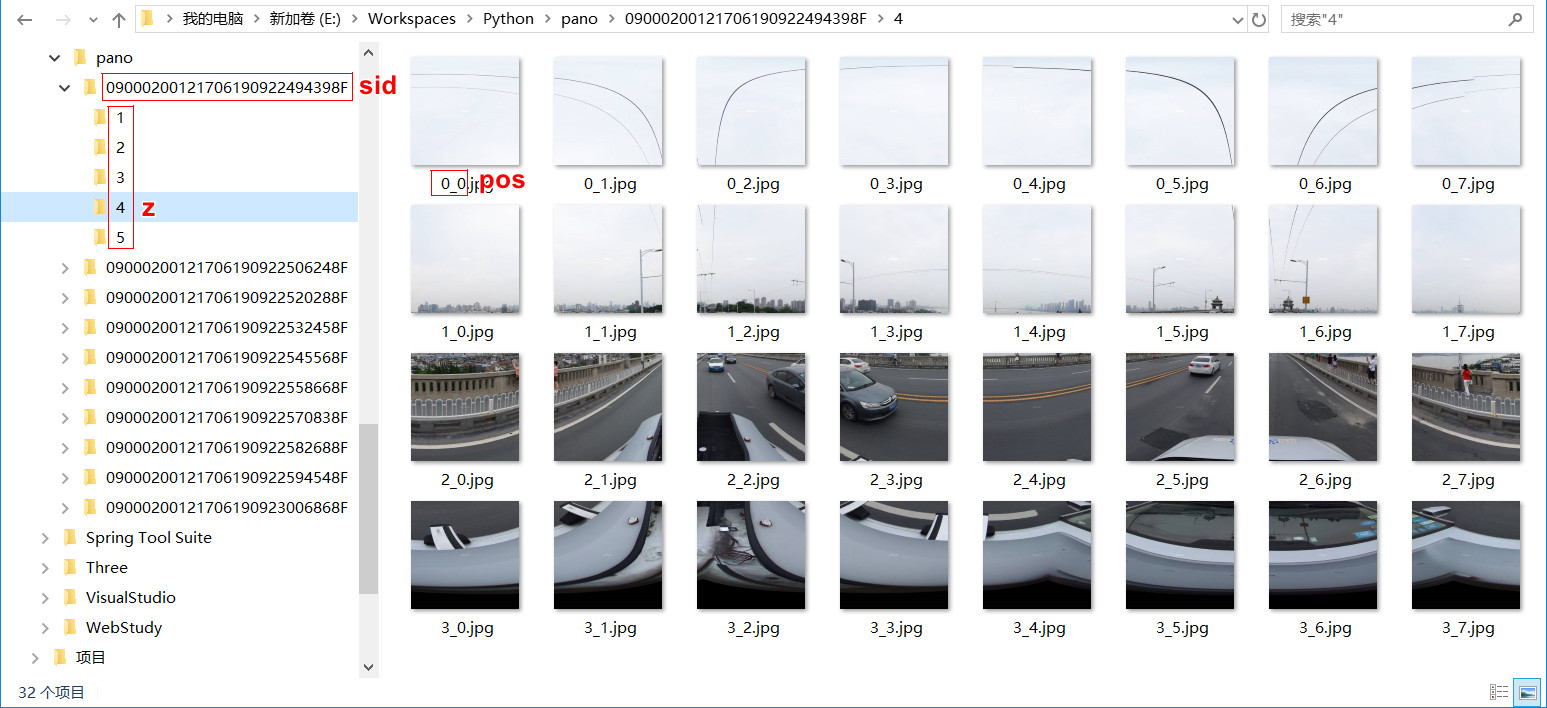
抓取结果如下,按上述分析的规则进行本地化存储,可以看到各级别下,所有的切片拼接起来,刚好是一张完整的全景图。
小结
① Python这门语言真的是蛮便捷,安装和配置都十分方便,也有很多IDE都支持,我初次使用,遇上问题就随手查Python语言手册,基本上半天完成该代码示例。
② 在爬虫程序方面,Python相关资源十分丰富,是爬虫开发的一把利器。
上述代码简要的实现了批量抓取百度街景影像切片数据,大量使用的话,建议继续处理一下,加上模拟浏览器访问的处理,否则很容易被服务方直接侦测到来自网络爬虫的资源请求,而导致封堵。
附 python爬虫入门(一)urllib和urllib2 https://www.cnblogs.com/derek1184405959/p/8448875.html
Python爬虫之小试牛刀——使用Python抓取百度街景图像的更多相关文章
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- python爬虫构建代理ip池抓取数据库的示例代码
爬虫的小伙伴,肯定经常遇到ip被封的情况,而现在网络上的代理ip免费的已经很难找了,那么现在就用python的requests库从爬取代理ip,创建一个ip代理池,以备使用. 本代码包括ip的爬取,检 ...
- Python爬虫实战:使用Selenium抓取QQ空间好友说说
前面我们接触到的,都是使用requests+BeautifulSoup组合对静态网页进行请求和数据解析,若是JS生成的内容,也介绍了通过寻找API借口来获取数据. 但是有的时候,网页数据由JS生成,A ...
- Python爬虫之-动态网页数据抓取
什么是AJAX: AJAX(Asynchronouse JavaScript And XML)异步JavaScript和XML.过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新.这意 ...
- Python爬虫入门教程 45-100 Charles抓取兔儿故事-下载小猪佩奇故事-手机APP爬虫部分
1. Charles抓取兔儿故事背景介绍 之前已经安装了Charles,接下来我将用两篇博客简单写一下关于Charles的使用,今天抓取一下兔儿故事里面关于小猪佩奇的故事. 爬虫编写起来核心的重点是分 ...
- [Python爬虫] 之八:Selenium +phantomjs抓取微博数据
基本思路:在登录状态下,打开首页,利用高级搜索框输入需要查询的条件,点击搜索链接进行搜索.如果数据有多页,每页数据是20条件,读取页数 然后循环页数,对每页数据进行抓取数据. 在实践过程中发现一个问题 ...
- python爬虫实战(2)--爬取百度贴吧
本篇目标 1.对百度贴吧的任意帖子进行抓取 2.指定是否只抓取楼主发帖内容 3.将抓取到的内容分析并保存到文件 1.URL格式的确定 先观察百度贴吧url格式,以中南财经政法大学迎新帖为例,URL我们 ...
- Python 爬虫实例(1)—— 爬取百度图片
爬取百度图片 在Python 2.7上运行 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Author: loveNight import jso ...
- Python爬虫实例(一)爬取百度贴吧帖子中的图片
程序功能说明:爬取百度贴吧帖子中的图片,用户输入贴吧名称和要爬取的起始和终止页数即可进行爬取. 思路分析: 一.指定贴吧url的获取 例如我们进入秦时明月吧,提取并分析其有效url如下 http:// ...
随机推荐
- 使用Arthas 获取Spring ApplicationContext还原问题现场
## 背景 最近来了个实习僧小弟,安排他实现对目标网站 连通性检测的小功能,简单讲就是将下边的shell 脚本换成Java 代码来实现 ``` 1#!/bin/bash 2URL="http ...
- 跟着大彬读源码 - Redis 9 - 对象编码之 三种list
目录 1 ziplist 2 skiplist 3 quicklist 总结 Redis 底层使用了 ziplist.skiplist 和 quicklist 三种 list 结构来实现相关对象.顾名 ...
- 【Java笔记】【Java核心技术卷1】chapter3 D1JavaStandard
package chapter3;/*有包名,命令行编译javac -d . 名字.java(注意空格)运行时用java chapter3.JavaStandard*/ public/*访问修饰符*/ ...
- python第二课--分支结构与循环结构
if语句---分支结构 在Python中,要构造分支结构可以使用if.elif和else关键字.所谓关键字就是有特殊含义的单词,像if和else就是专门用于构造分支结构的关键字,很显然你不能够使用它作 ...
- 一段代码分清global和nonlocal
废话不多说,直接代码啊~~~ a=999 b=99999 def test1(): a=888 b=88888 print('a={}'.format(a)) print('b={}'.format( ...
- 8.7 day28 网络编程 socket套接字 半连接池 通信循环 粘包问题 struct模块
前置知识:不同计算机程序之间的数据传输 应用程序中的数据都是从程序所在计算机内存中读取的. 内存中的数据是从硬盘读取或者网络传输过来的 不同计算机程序数据传输需要经过七层协议物理连接介质才能到达目标程 ...
- Sqlmap过waf命令tamper各脚本的适用环境
0x00 相信很多小伙伴和我一样感同身受,站上明明有注入可是被万恶的WAF拦截了或者过滤了,这时候就需要用到SQLMAP强大的tamper了. 0x01 使用方法--tamper xxx.py apo ...
- 使用 php 内部web服务器
使用 php 内部web服务器如网站目录 d:\web\index.php1.打开命令窗口,输入下列3条命令cd d:cd d:\web\index.phpphp -S localhost:80802 ...
- Mysql优化(出自官方文档) - 第八篇(索引优化系列)
目录 Mysql优化(出自官方文档) - 第八篇(索引优化系列) Optimization and Indexes 1 Foreign Key Optimization 2 Column Indexe ...
- 记录一次Jquery中 this 关键字使用出现的问题
今天在用Jquery改造之前的JS代码过程中,遇到了一个让我懵逼了三小时的问题. 问题的关键在 this 的使用.在这里与大家分享一下.并且分享一下我做表单提交的检查代码 错误代码如下: $(&quo ...