python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel。
- 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据
- 使用语言:python
- 工具:PyCharm
- 涉及库:requests、re、openpyxl(高版本excel操作库)
实现代码

# -*- coding: utf-8 -*-
# @Author : yocichen
# @Email : yocichen@126.com
# @File : maoyan100.py
# @Software: PyCharm
# @Time : 2019
# @UpdateTime : 2020/4/26 import requests
from requests import RequestException
import re
import openpyxl
import traceback # Get page's html by requests module
def get_one_page(url):
try:
headers = {
'user-agent': 'Mozilla / 5.0(Windows NT 10.0; WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 53.0.2785.104Safari / 537.36Core / 1.53.4882.400QQBrowser / 9.7.13059.400'
}
# Sometimes, the proxies need to be replaced.
# You can get them by accessing https://www.kuaidaili.com/free/inha/
proxies = {
'http': '60.190.250.120:8080'
}
# use headers to avoid 403 Forbidden Error(reject spider)
response = requests.get(url, headers=headers, proxies=proxies)
if response.status_code == 200 :
return response.text
return None
except RequestException:
traceback.print_exc()
return None # Get useful info from html of a page by re module
def parse_one_page(html):
try:
pattern = re.compile('<dd>.*?board-index.*?>(\d+)<.*?<a.*?title="(.*?)"'
+'.*?data-src="(.*?)".*?</a>.*?star">[\\s]*(.*?)[\\n][\\s]*</p>.*?'
+'releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?'
+'fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
return items
except Exception:
traceback.print_exc()
return [] # Main call function
def main(url):
page_html = get_one_page(url)
parse_res = parse_one_page(page_html)
return parse_res # Write the useful info in excel(*.xlsx file)
def write_excel_xlsx(items):
wb = openpyxl.Workbook()
ws = wb.active
rows = len(items)
cols = len(items[0])
# First, write col's title.
ws.cell(1, 1).value = '编号'
ws.cell(1, 2).value = '片名'
ws.cell(1, 3).value = '宣传图片'
ws.cell(1, 4).value = '主演'
ws.cell(1, 5).value = '上映时间'
ws.cell(1, 6).value = '评分'
# Write film's info
for i in range(0, rows):
for j in range(0, cols):
if j != 5:
ws.cell(i+2, j+1).value = items[i][j]
else:
ws.cell(i+2, j+1).value = items[i][j]+items[i][j+1]
break
# Save the work book as *.xlsx
wb.save('maoyan_top100.xlsx') if __name__ == '__main__':
print('spider working...')
res = []
url = 'https://maoyan.com/board/4?'
for i in range(0, 10):
if i == 0:
res = main(url)
else:
newUrl = url+'offset='+str(i*10)
res.extend(main(newUrl))
print('writing into excel...')
write_excel_xlsx(res)
print('work done!\nNote: the data is in the current directory.')
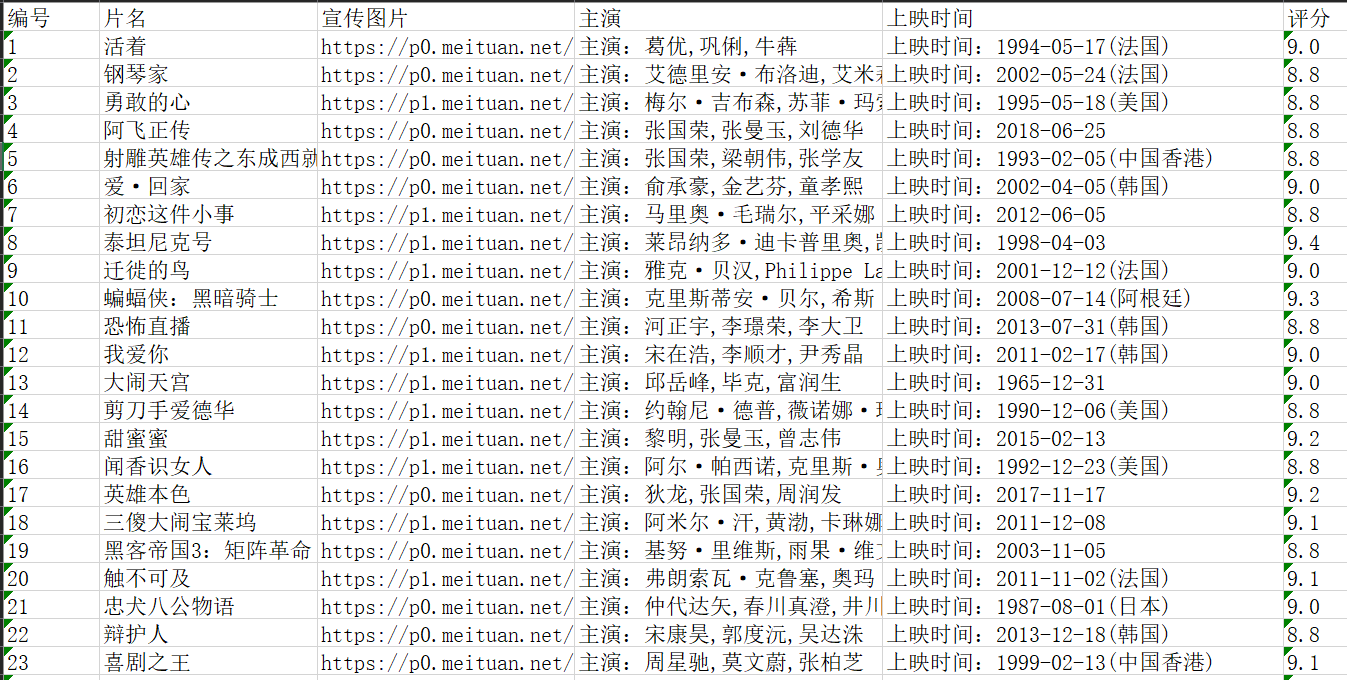
更新效果图:
后记
入门了一点后发现,如果使用正则表达式和requests库来实行进行数据爬取的话,分析HTML页面结构和正则表达式的构造是关键,剩下的工作不过是替换url罢了。
补充一个分析HTML构造正则的例子
审查元素我们会发现每一项都是<dd>****</dd>格式
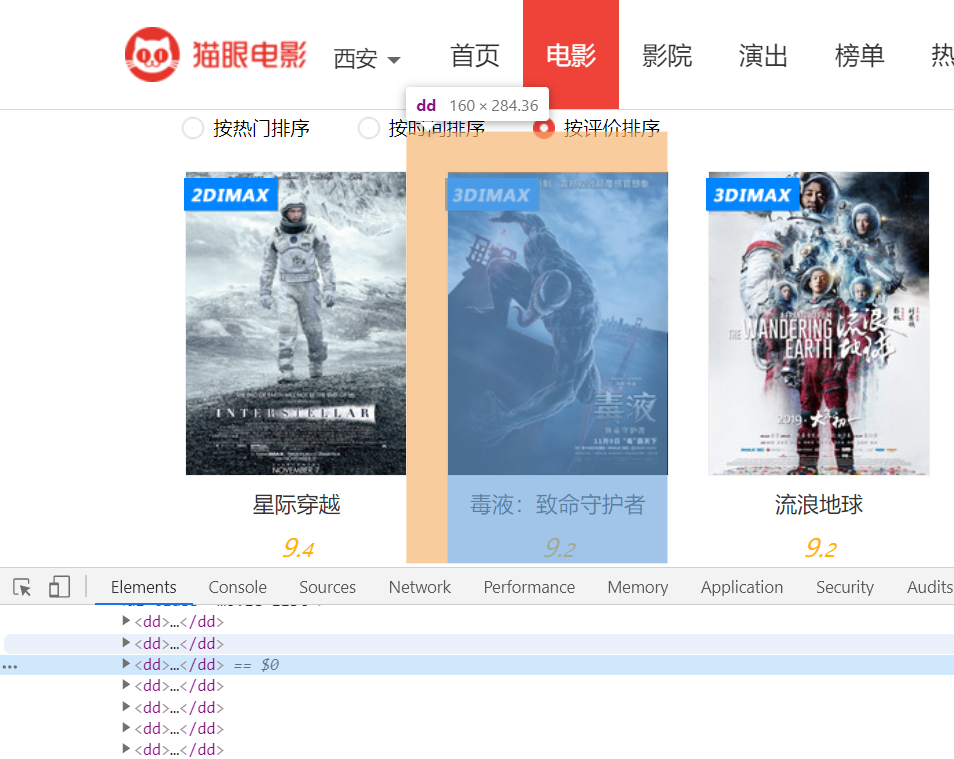
我想要获取电影名称和评分,先拿出HTML代码看一看

试着构造正则
'.*?<dd>.*?movie-item-title.*?title="(.*?)">.*?integer">(.*?)<.*?fraction">(.*?)<.*?</dd>' (随手写的,未经验证)
参考资料
【B站视频 2018年最新Python3.6网络爬虫实战】https://www.bilibili.com/video/av19057145/?p=14
【猫眼电影robots】https://maoyan.com/robots.txt (最好爬之前去看一下,那些可爬那些不允许爬)
python 爬取猫眼电影top100数据的更多相关文章
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- python爬取猫眼电影top100
最近想研究下python爬虫,于是就找了些练习项目试试手,熟悉一下,猫眼电影可能就是那种最简单的了. 1 看下猫眼电影的top100页面 分了10页,url为:https://maoyan.com/b ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- python应用-爬取猫眼电影top100
import requests import re import json import time from requests.exceptions import RequestException d ...
随机推荐
- SpringBoot自动注入分析
我们经常会被问到这么一个问题:SpringBoot相对于spring有哪些优势呢?其中有一条答案就是SpringBoot自动注入.那么自动注入的原理是什么呢?我们进行如下分析. 1:首先我们分析项目的 ...
- homebrew安装问题(Failed during: git fetch origin master:refs/remotes/origin/master --tags --force)
在mac系统中,使用homebrew可以很方便的管理包.按照官网的说明执行以下命令时总是报错: /usr/bin/ruby -e "$(curl -fsSL https://raw.gith ...
- Mac 10.14在新窗口中打开文件夹
Mac 10.14 Open folders in new window (high Sierra) System Preferences > Dock. Change "Prefer ...
- javascript生成规定范围的随机整数
Math.Random()函数能够返回带正号的double值,该值大于等于0.0且小于1.0,即取值范围是[0.0,1.0)的左闭右开区间,返回值是一个伪随机选择的数,在该范围内(近似)均匀分布. 我 ...
- tf.split
tf.split(dimension, num_split, input):dimension的意思就是输入张量的哪一个维度,如果是0就表示对第0维度进行切割.num_split就是切割的数量,如果是 ...
- js判断是否为空和typeof的用法
(1)typeof作用用于查看数据类型 (2)typeof用法typeof 返回值类型有number, string, boolean, function, undefined, objectPS:在 ...
- OCPC(Optimized Cost per Click)[Paper笔记]
背景 在线广告中,广告按照CPM排序,排在前面的广告竞争有限广告位(截断).其中,CPM=bid*pctr.注GSP二价计费的,按照下一位bid计费.适当调整bid,可以提高竞价的排名,从而获得展现的 ...
- Ubuntu 设置默认以Root用户身份登录
系统 :Linux ubuntu 4.4.0-31-generic #50-Ubuntu SMP Wed Jul 13 00:07:12 UTC 2016 x86_64 x86_64 x86_64 G ...
- JavaScript-改变this指向
一.this指向的详解 概括:this的指向到底是指向哪里?通常来说,只有当函数执行的时候才可以确定this指向的到底是谁,简单的也可以这么说:this最终指向的是那个调用它的对象. 常见的一般有以下 ...
- STL的vector略解
本文部分内容参考于这儿. vector 的基础知识,上文已经阐述地很详尽了.笔者谨给出 vector 的声明及其常用函数. 代码抬头需包含 #include<vector> using n ...