归并排序、jensen不等式、非线性、深度学习
前言
在此记录一些不太成熟的思考,希望对各位看官有所启发。
从题目可以看出来这篇文章的主题很杂,这篇文章中我主要讨论的是深度学习为什么要“深”这个问题。先给出结论吧:“深”的层次结构是为了应对现实非线性问题中的复杂度,这种“深”的分层结构能够更好地表征图像语音等数据。
好了,如果各位看官感兴趣,那就让我们开始这次思考的旅程吧!
归并排序
我们首先从归并排序算法开始,这里先跟大家回顾一下这个算法,相信大家都已经非常熟悉了。排序是计算机基础算法中的一个重要主题,要将一个无序的数组排成有序的一个容易想到的算是冒泡法,其时间复杂度为O(n^2),冒泡算法并没用到“分而治之”的思想,而是一次性地解决问题。而我们要讨论的归并算法的时间复杂度为O(nlogn),归并算法的大致原理是递归地将待排序的数组分解成更小的数组,将小数组排好序,再逐层将这些排好序的小数组拼成大数组,最终完成排序。直接上代码吧:
def merge_sort(arr):
"""
input : unsorted array
output: sorted array in ascending order
"""
if len(arr) <= 1:
return arr
half = len(arr)//2
left = merge_sort(arr[0:half])
right = merge_sort(arr[half:])
left_tail ,right_tail = 0 , 0
sorted_arr = []
while left_tail < len(left) and right_tail < len(right):
if left[left_tail] < right[right_tail]:
sorted_arr.append(left[left_tail])
left_tail += 1
else:
sorted_arr.append(right[right_tail])
right_tail += 1
if left_tail < len(left):
sorted_arr += left[left_tail:]
else:
sorted_arr += right[right_tail:]
return sorted_arr
这段代码还是比较直观吧,简单说一下代码:首先确定递归基,即递归什么时候停下来,显然当数组分解到只含一个数或者一个数也没有时就停下来并将数组返回,因为只有一个元素或没有元素的数组本身就是“有序”的了,所以我们直接返回。当数组元素个数大于1个,就可以将数组分解成左右两个子数组,递归调用merge_sort函数求出left 和 right 的有序数组,后面再将有序数组left和right合成一个大数组返回就ok了。由于每次分解数组的大小都在减少,会一步一步向递归基靠近,所以会算法是收敛的,即一定会停下来。
这个算法是比较基础的算法没什么好说的,但是让我们思考一个问题,为什么将大问题分解成小问题,这样递归地倒腾一下就能将算法复杂度从O(n^2)降为O(nlogn)?同样的问题规模,分解了再组合的复杂度为什么就比直接算的复杂度低?你或许可以直接用主定理(master theorem)计算出归并算法O(nlogn)的复杂度,但是这也不能直观解释我们上述的疑问。对于这个问题我们可以打个类似的比喻:10斤苹果榨出了5斤苹果汁,再用1斤苹果榨汁,榨10次,其总量竟然不等于之前的不相等!
所以,这个算法有效究竟是基于什么逻辑?在继续之前请好好思考一下这个问题,看各位能不能想得通。
非线性,Jensen 不等式
如果你跟我一样都想不通上一节的问题,那你跟我可能都犯了相同的错误——线性思维。首先来说一下什么是“线性”,说得学术一点就是满足我们线性代数课本里面的那个8个法则的运算,感兴趣的可以去翻一翻课本复习一下。说得稍微不严谨一点就是满足“数乘”和“加法”的运算,“数乘”是说我们这个系统如果输入翻倍其输出也会翻倍;“加法”是说”对这个系统单独输入A,输出为A_OUT,单独输入B输出为B_OUT,则输入A+B的输出为A_OUT+B_OUT"。在说简单点就是这个系统的输入输出图像是条直线或是超平面。
我们前面说的那个榨汁问题就是一个线性的系统:输入10斤苹果输出为5斤苹果汁,那么输入20斤苹果输出为10斤苹果汁;如果输入10斤葡萄输出为8斤葡萄汁,那么输入10斤苹果加上10斤葡萄的输出为5斤苹果汁和8斤葡萄汁的混合果汁。整个过程是线性的,如果我们用线性思维去思考线性系统那是ok的,一切都是合理的。但是如果我们用线性思维去思考非线性的系统那就要出问题了。回到我们那个排序问题上来,这其实是个非线性的问题,简单的思考一下:排序20个数的工作量应该要比排2次10个数的工作量大得多。如果你不信,可以自己动手排一排去感受下。所有排序的规模与时间是非线性的,上文用一个线性的系统去做类比当然是不对的。
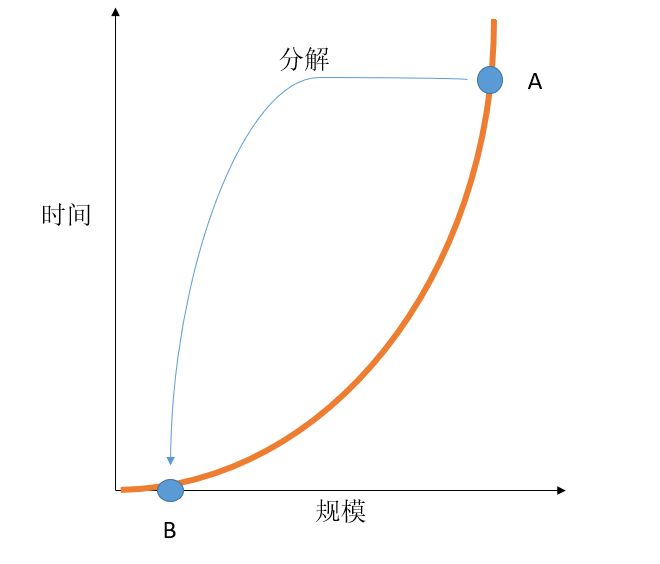
下面我们就来分析下归并排序为什么有效,如下图横轴是排序的规模,纵轴是排序的时间,我们知道,如果不将问题分解(冒泡排序),那么时间复杂度为O(N^2),我们用橙色曲线表示算法规模随时间的关系。曲线在数据规模不大的时候时间消耗并不大,甚至在规模接近0时比线性增长的时间消耗还低(此处有点不严谨,规模是离散的),当问题规模大到一定程度时消耗的时间才开始“起飞”。如图中的A点,这个时候规模已经比较大了,消耗的时间也非常大。归并排序主要思想就是将A规模的排序问题分解成若干个B规模的排序问题,“宁愿解决多个简单的B问题再将结果综合起来也不愿意解决一个复杂度很高的A问题”。正因为问题是非线性的,所以将问题分解与将问题一次解决的工作量才会不一样。如果问题是线性无论怎样分解其工作量是相等的。与归并排序类似,现实生活中也有类似的非线性例子,比如学一门课需要9个小时,一天花9个小时来学,与3天每天3个小时来学的效果肯定不一样。
下面我们进入Jenson不等式,相信你在机器学习的理论中已经接触过了,我们来大概看一下这个不等式说了什么。如果一个函数严格是严格下凸函数,那么有:
\]
其中$ \sum_{i=1}^{N}\lambda_{i}=1$。其实下凸函数简单的说就是曲线往下凸的非线性函数(好像是废话,严格定义麻烦去翻书),凸函数其实就是非线中比较简单的一种,仔细看看Jenson不等式,由上面这种问题分解的视角来看,这个不等式告诉我们对于凸函数,将问题分解来解决与一次性解决的结果是不相等的,并且还告诉了我们这个不相等的方向。在严格下凸函数中不等式左边度量的是问题分解后的输出;右边是不分解的整体输出。分解后的输出要小于问题不分解的输出。至于为什么说不等式左边是分解后的,不等式右边是整体的,请读者自行体会,这里就不啰嗦了。这就是Jenson不等式,可以看成是我们之前讨论的非线性问题的数学表示。
根据以上的分析我们可以看出如果算法的时间随规模增长是下凸函数的关系,我们都可以用归并算法这种“分层“的思想将问题逐层分解成更小的子问题,去解决规模较小的子问题,再回过头来将子问题的结果合并。Jenson不等式告诉们这样的方法比一次解决问题更省力(当然如果是上凸函数这样分解后则更费力)。
深度学习
以上讨论这些与深度学习有什么关系?我们知道深度学习与传统机器学习算法的差别之一就是它中间的隐藏层数很深,像cv的resnet,nlp的bert模型层数都非常深。从理论上来说只含有一层隐藏层的神经网络,只要这一层的神经元足够多就能以任意误差拟合任意函数。所以理想情况下,即数据足够多足够好的情况下,这种只有一层的神经网络也能够工作得很好,比如SVM就可以看成是只有一个隐藏层的模型,这么看来只要数据足够多就没有深度学习什么事了?但是现实情况下正是深度学习这种“深”层次的表征才让深度学习脱颖而出,性能超过各种浅层模型。我们之前说的数据足够多足够好的理想情况太过乌托邦,现实中数据,算力总是不足的,因此寻求对于数据更高效的表征比寻找一个乌托邦的方法更为实际。这种乌托邦的例子我还可以举一个,比如我曾经认为只要我们研究透彻了量子力学,则可以推出其他所有学科的结论,比如化学、生物、社会学。是的,的确只要有足够的算力足够的时间和耐心一定可以由量子力学推导出其他学科。但是这太理想话,用量子力学去推导生物学其复杂度与工作量可想而知,我们没有人有这样的精力去做这种工作。所以我们要将问题分层,在不同层次上去解决问题,从而降低问题的复杂度,所以量子力学的突破并不会让化学、生物这这些学科消失,不同学科它们各自需要解决的问题。再举一个例子,我们的编程语言也是分层次的,比如有接近硬件的汇编、c语言,有高级点的c++、java、python等,以及更高层次的各种编程框架与函数库,理论上说用底层的汇编语言也可以实现一切,但是问题还是一个复杂度的问题,不同的语言关注不同的问题。试想用汇编语言去编写一个3D游戏其难度如何?
说了这么多,现在说回深度学习,深度学习就是采用分层的思想将一个复杂的问题分解成不同的层次去解决,比如一个图片分类的神经网络,低层的网络去识别线条、边角等特征,高一点的层次识别圆形、方形等几何特征,再高的层次识别人、飞机、动物等更抽象的特征。至于说为什么的这样的分层有效,我觉得其实跟之前介绍的归并算法有效的原理以及Jensen不等式的原理其实是一样的。深度学习擅长的图像识别、语音识别这类问题的规模与复杂度之间其实也可以近似看成下凸的,之前的分析可以知道这种下凸的问题采用逐层分解子问题的方式能够有效降低复杂度。深度学习不仅能采用分层的方式设计模型,还能用反向传播算法自动求解各个层次的参数,这正是这种方法的奇妙之处,现实已经证明了这种方法的有效性。可以说深度学习这种分层表征数据的结构是对图像、语音、文字类数据的高效表征。当然上面的分析过于简单,现实中数据复杂的非线性可能非常复杂,而不仅仅能用一个“凸“的性质描述,所以对于不同的问题需要探索不同的模型结构。
总结
这篇博客中我们简单地介绍了归并算法,分析了这种将问题分层处理的方式为什么会高效,接着介绍了jenson不等式,并分析了对于凸性函数将输入分解和整体处理输出的大小关系,接着我们从这个角度分析了深度学习算法为什么要“深”:因为这种深度的分层结构是对“下凸”的问题的一种高效的表征。
这篇博客不太严谨,欢迎拍砖
归并排序、jensen不等式、非线性、深度学习的更多相关文章
- 深度学习——无监督,自动编码器——尽管自动编码器与 PCA 很相似,but自动编码器既能表征线性变换,也能表征非线性变换;而 PCA 只能执行线性变换
自动编码器是一种有三层的神经网络:输入层.隐藏层(编码层)和解码层.该网络的目的是重构其输入,使其隐藏层学习到该输入的良好表征. 自动编码器神经网络是一种无监督机器学习算法,其应用了反向传播,可将目标 ...
- 在排序模型方面,点评搜索也经历了业界比较普遍的迭代过程:从早期的线性模型LR,到引入自动二阶交叉特征的FM和FFM,到非线性树模型GBDT和GBDT+LR,到最近全面迁移至大规模深度学习排序模型。
https://mp.weixin.qq.com/s/wjgoH6-eJQDL1KUQD3aQUQ 大众点评搜索基于知识图谱的深度学习排序实践 原创: 非易 祝升 仲远 美团技术团队 前天
- Deep Learning(深度学习)学习笔记整理
申明:本文非笔者原创,原文转载自:http://www.sigvc.org/bbs/thread-2187-1-3.html 4.2.初级(浅层)特征表示 既然像素级的特征表示方法没有作用,那怎样的表 ...
- 【转载】Deep Learning(深度学习)学习笔记整理
http://blog.csdn.net/zouxy09/article/details/8775360 一.概述 Artificial Intelligence,也就是人工智能,就像长生不老和星际漫 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 机器学习&深度学习经典资料汇总,data.gov.uk大量公开数据
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- Deep Learning(深度学习)学习笔记整理系列之(三)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- 【转】Deep Learning(深度学习)学习笔记整理系列之(三)
好了,到了这一步,终于可以聊到Deep learning了.上面我们聊到为什么会有Deep learning(让机器自动学习良好的特征,而免去人工选取过程.还有参考人的分层视觉处理系统),我们得到一个 ...
- 近200篇机器学习&深度学习资料分享(含各种文档,视频,源码等)(1)
原文:http://developer.51cto.com/art/201501/464174.htm 编者按:本文收集了百来篇关于机器学习和深度学习的资料,含各种文档,视频,源码等.而且原文也会不定 ...
随机推荐
- win10 我的电脑下面的六个文件夹的隐藏
第一步 第二步 第三步 修改注册表,要隐藏那个文件夹,ThisPCPolicy 改为 "Hide" 修改我的文档的注册表值,使我的文档文件夹隐藏 <w ...
- 【C++】string::find函数
int vis=a.find(b):从string a开头开始查找第一个遇到的string b,返回string a中所匹配字符串的第一个字符的下标位置,找不到则返回-1. int vis=a.fin ...
- Mybatis学习笔记之---多表查询(1)
Mybatis多表查询(1) (一)举例(用户和账户) 一个用户可以有多个账户 一个账户只能属于一个用户(多个账户也可以属于同一个用户) (二)步骤 1.建立两张表:用户表,账户表,让用户表和账户表之 ...
- LD_PRELOAD和ld --wrap
前言 LD_PRELOAD和ld --wrap都能实现不修改原始代码,替换指定函数的实现.通常我们会使用这些方法,替换如malloc)()/free().read()/write()等函数,并在替换函 ...
- Unity进阶之ET网络游戏开发框架 03-Hotfix层启动
版权申明: 本文原创首发于以下网站: 博客园『优梦创客』的空间:https://www.cnblogs.com/raymondking123 优梦创客的官方博客:https://91make.top ...
- springboot+mybatis+druid+atomikos框架搭建及测试
前言 因为最近公司项目升级,需要将外网数据库的信息导入到内网数据库内.于是找了一些springboot多数据源的文章来看,同时也亲自动手实践.可是过程中也踩了不少的坑,主要原因是我看的文章大部分都是s ...
- LoRa硬件调试-前导码
前言 已知LoRa数据包在负载之前会有一段前导码,接收端是先检测前导码,收到前导码之后才认为有数据发送过来. 那么不同的前导码的长度会有什么影响呢? 前导码长短的优劣势 - 前导码实际上是占符号的,也 ...
- 三维动画形变算法(Linear rotation-invariant coordinates和As-Rigid-As-Possible)
在三维网格形变算法中,个人比较喜欢下面两个算法,算法的效果都比较不错, 不同的是文章[Lipman et al. 2005]算法对控制点平移不太敏感.下面分别介绍这两个算法: 文章[Lipman et ...
- python 23 继承
目录 继承--inheritance 1. 面向对象继承: 2. 单继承 2.1 类名执行父类的属性.方法 2.2 子类对象执行父类的属性.方法 2.3 执行顺序 2.4 既要执行子类的方法,又要执行 ...
- lua_lua与.Net互相调用
配置环境:创建C#项目,引入luainterface-1.5.3\Built下面的LuaInterface.dll文件和luanet.dll文件.引入命名空间using LuaInterface 代码 ...