使用Python爬虫整理小说网资源-自学
第一次接触python,原本C语言的习惯使得我还不是很适应python的语法风格。希望读者能够给出建议。
相关的入门指导来自以下的网址:https://blog.csdn.net/c406495762/article/details/78123502编者的文章很用心,好评。
下面是本次自学的详细说明:
----->确认目标:我选择一个不是很出名的小说网,之所以这么做,是因为一些大网站上一般都有一些反爬虫机制,作为一只弱鸡,还是选个容易上手的小网站。
->穿越小说网->《妖界之门》:http://www.15kxs.com/cbbook_22000/->这是章节汇总
点开第一章:http://www.15kxs.com/cbbook_22000/1.html 对比两个网址再多点开几个网页就很容易发现URL中的规律。但是这里为了更好的熟悉相关代码,我决定进行如下操作:
在章节汇总的网页上提取各个章节的网址并逐一请求,清洗网页源代码得到文章,并将文章汇总到本地的txt文件中。
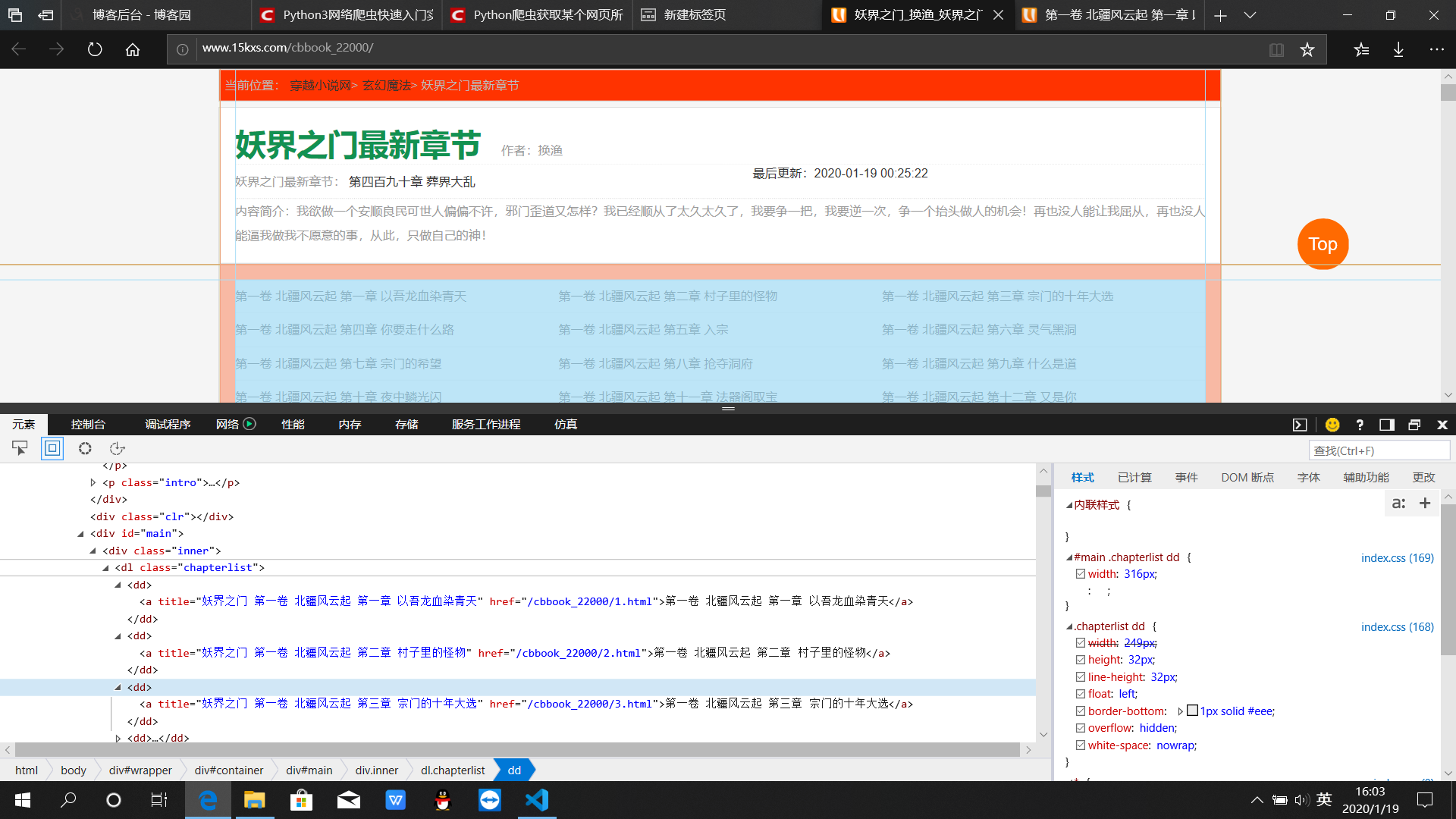
目标是提取<a>中的“href=”的地址
下面是Python代码
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
filename = 'novel.txt' if __name__ == "__main__":
aim = "http://www.15kxs.com/cbbook_22000/"
cyc = requests.get(aim)
psd = cyc.text
cnt = BeautifulSoup(psd,features="html.parser")
clc = cnt.find_all('a')
first = 0#在实验过程中发现章节网页中<a>的所有选项中提出的网址不仅仅包括着小说页面,对于其他页面进行筛选
for haim in clc:
link = haim.get('href')
lenth = len(link)
if first>2 and lenth!=0 and link[0]=='/':
"""拿到了每一个章节的链接尾地址"""
urlaim="http://www.15kxs.com"+link
request_get = requests.get(urlaim)
html = request_get.text
ctm = BeautifulSoup(html,features="html.parser")
tex = ctm.find_all('div',id='BookText')
result = tex[0].text.replace('\xa0','')#编码格式是一个难点,能够打印到屏幕上的字符不一定能写入文件
with open(filename,'a',encoding='utf-8') as file_object:
file_object.write(result)
first = first+1#用于计算数量
print(str(first)+" is ok")
print("all above is ok")
效果如下:
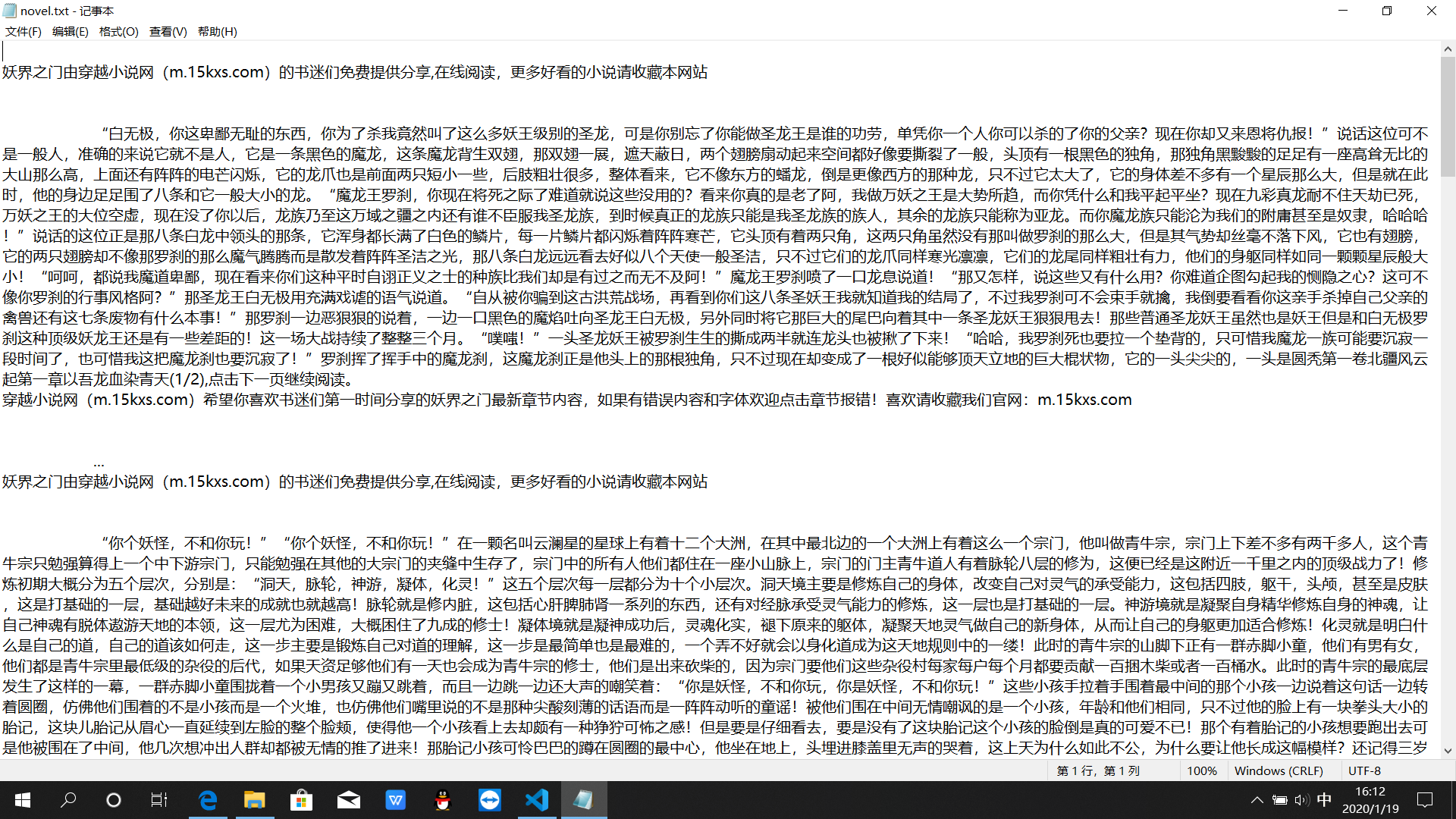
表示效果还可以
唯一不足的是:抽取速度有些慢,5分钟内只能整理110章节左右
使用Python爬虫整理小说网资源-自学的更多相关文章
- 【收藏】收集的各种Python爬虫、暗网爬虫、豆瓣爬虫、抖音爬虫 Github1万+星
收集的各种Python爬虫.暗网爬虫.豆瓣爬虫 Github 1万+星 磁力搜索网站2020/01/07更新 https://www.cnblogs.com/cilisousuo/p/1209954 ...
- python爬虫之小说网站--下载小说(正则表达式)
python爬虫之小说网站--下载小说(正则表达式) 思路: 1.找到要下载的小说首页,打开网页源代码进行分析(例:https://www.kanunu8.com/files/old/2011/244 ...
- python爬虫——《瓜子网》的广州二手车市场信息
由于多线程爬取数据比单线程的效率要高,尤其对于爬取数据量大的情况,效果更好,所以这次采用多线程进行爬取.具体代码和流程如下: import math import re from concurrent ...
- python 爬虫 scrapy1_官网教程
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- python爬虫爬小说网站涉及到(js加密,CSS加密)
我是对于xxxx小说网进行爬取只讲思路不展示代码请见谅 一.涉及到的反爬 js加密 css加密 请求头中的User-Agent以及 cookie 二.思路 1.对于js加密 对于有js加密信息,我们一 ...
- python|爬虫东宫小说
2k小说网爬取最近大火的<东宫>小说,借鉴之前看过的一段代码,修改之后,进行简单爬取. from urllib import requestfrom bs4 import Beautifu ...
- 利用Python爬虫实现百度网盘自动化添加资源
事情的起因是这样的,由于我想找几部经典电影欣赏欣赏,于是便向某老司机寻求资源(我备注了需要正规视频,绝对不是他想的那种资源),然后他丢给了我一个视频资源网站,说是比较有名的视频资源网站.我信以为真,便 ...
- 如何丧心病狂的使用python爬虫读小说
写在前边 其实一直想入门python很久了,慕课网啊,菜鸟教程啊python的基础的知识被我翻了很多遍了,但是一直没有什么实践.刚好,这两天被别人一直安利一本小说<我可能修的是假仙>,还在 ...
- Python爬虫-爬小说
用途 用来爬小说网站的小说默认是这本御天邪神,虽然我并没有看小说,但是丝毫不妨碍我用爬虫来爬小说啊. 如果下载不到txt,那不如自己把txt爬下来好了. 功能 将小说取回,去除HTML标签 记录已爬过 ...
随机推荐
- 并发编程的基石——AQS类
本博客系列是学习并发编程过程中的记录总结.由于文章比较多,写的时间也比较散,所以我整理了个目录贴(传送门),方便查阅. 并发编程系列博客传送门 本文参考了[Java多线程进阶(六)-- J.U.C之l ...
- python 读取域名信息
#!/usr/bin/env python # _*_coding:utf-8_*_ import OpenSSL from OpenSSL import crypto from dateutil i ...
- linux的那些事-时间 时区
时间表示: 用法:date [选项]... [+格式] 或:date [-u|--utc|--universal] [MMDDhhmm[[CC]YY][.ss]] 以给定的格式显示当前时间,或是设置系 ...
- 秘钥分割-Shamir秘钥分割门限方案
精选: 1.问题的提出 2.需求的抽象: 有一个秘钥S,转换成另一种数据数据形式,分配给12个人(s1,s2,.......,s12),使得任意3个人的数据拼凑在一起就可以反向计算出秘钥S. 3.解决 ...
- SpringCloud之Ribbon负载均衡的入门操作
使用Ribbon进行负载均衡 在使用Ribbon之前,我们先想一个之前的问题,之前我们将服务提供者注册进了eureka注册中心,但是在消费者端,我们还是使用的restTemplate调用的时候,其中写 ...
- uniapp简易直播
实验准备 在服务器部署nginx-rtmp作为我们直播推流和拉流的服务器(如果服务商选择七牛,也是直接给地址推流).为了加快部署,我在这一步使用Docker. docker pull tiangolo ...
- 15.Android-实现TCP客户端,支持读写
在上章14.Android-使用sendMessage线程之间通信我们学习了如何在线程之间发送数据. 接下来我们便来学习如何通过socket读写TCP. 需要注意的是socket必须写在子线程中,不能 ...
- Redis-位图
关于位图,可能大家不太熟悉, 那么位图能干啥呢?位图的内容其实就是普通的字符串,也就是byte数组,我们都知道 byte 8 位无符号整数 0 到 255 说个场景.比如你处理一些业务时候,往往会存在 ...
- STM32固件库和自定义工程模板
固件库结构 本文使用的固件库是STM32F10x_StdPeriph_Lib_V3.5.0,可以在官网获取.该固件库包含四个文件夹和一个库的说明文档,如下图所示,stm32f10x_stdperiph ...
- Html介绍,认识html文件基本结构
一个HTML文件的基本机构如下: <html><head>...</head><body>...</body></html>代码 ...