08 学生课程分数的Spark SQL分析
读学生课程分数文件chapter4-data01.txt,创建DataFrame。






用DataFrame的操作或SQL语句完成以下数据分析要求,并和用RDD操作的实现进行对比:
- 每个分数+5分。

- 总共有多少学生?
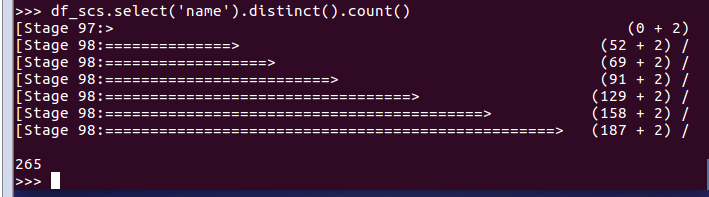
- 总共开设了哪些课程?

- 每个学生选修了多少门课?
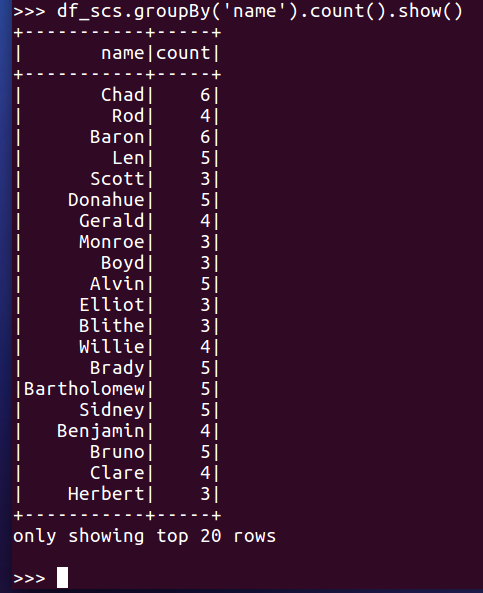
- 每门课程有多少个学生选?

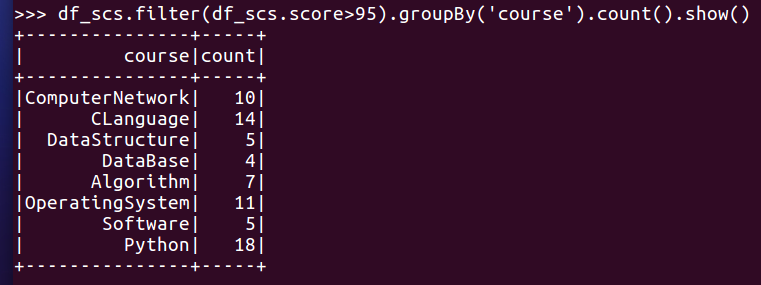
- 每门课程大于95分的学生人数?
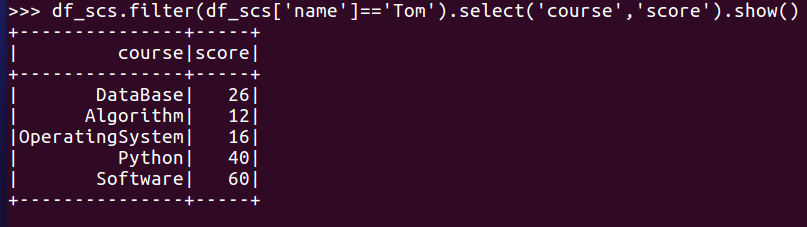
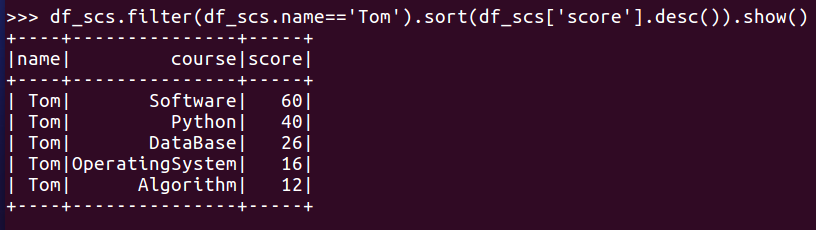
- Tom选修了几门课?每门课多少分?
- Tom的成绩按分数大小排序。
- Tom的平均分。

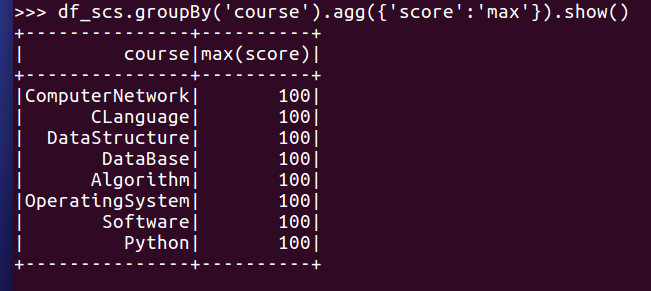
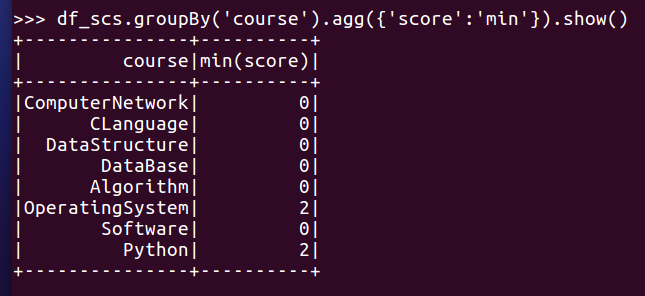
- 求每门课的平均分,最高分,最低分。

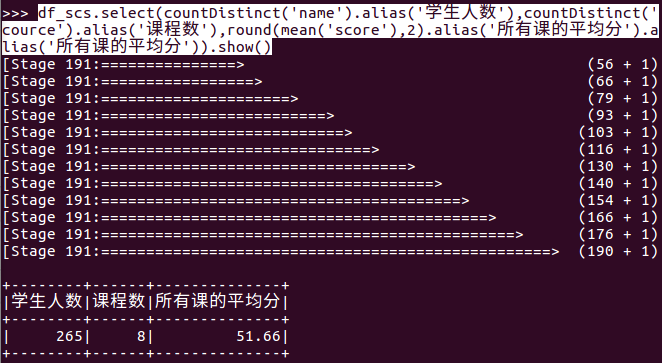
- 求每门课的选修人数及平均分,精确到2位小数。
- 每门课的不及格人数,通过率
- 结果可视化。
from pyspark.sql.types import IntegerType, StringType, StructField, StructType
fields = [StructField(...), ...]
schema = StructType(fields)
类型:http://spark.apache.org/docs/latest/sql-ref-datatypes.html
from pyspark.sql import Row
data = rdd.map(lambda p: Row(...))
Spark SQL DataFrame 操作
df.show()
df.printSchema()
df.count()
df.head(3)
df.collect()
df[‘name’]
df.name
df.first().asDict()
df.describe().show()
df.distinct()
df.filter(df['age'] > 21).show()
df.groupBy("age").count().show()
df.select('name', df['age‘] + 1).show()
df_scs.groupBy("course").avg('score').show()
df_scs.agg({"score": "mean"}).show()
df_scs.groupBy("course").agg({"score": "mean"}).show()
函数:http://spark.apache.org/docs/2.2.0/api/python/pyspark.sql.html#module-pyspark.sql.functions
08 学生课程分数的Spark SQL分析的更多相关文章
- hive Spark SQL分析窗口函数
Spark1.4发布,支持了窗口分析函数(window functions).在离线平台中,90%以上的离线分析任务都是使用Hive实现,其中必然会使用很多窗口分析函数,如果SparkSQL支持窗口分 ...
- Spark SQL大数据处理并写入Elasticsearch
SparkSQL(Spark用于处理结构化数据的模块) 通过SparkSQL导入的数据可以来自MySQL数据库.Json数据.Csv数据等,通过load这些数据可以对其做一系列计算 下面通过程序代码来 ...
- 小菜菜mysql练习解读分析1——查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数
查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数 好的,第一道题,刚开始做,就栽了个跟头,爽歪歪,至于怎么栽跟头的 ——需要分析题目,查询的是 ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- Spark SQL慕课网日志分析(1)--系列软件(单机)安装配置使用
来源: 慕课网 Spark SQL慕课网日志分析_大数据实战 目标: spark系列软件的伪分布式的安装.配置.编译 spark的使用 系统: mac 10.13.3 /ubuntu 16.06,两个 ...
- Spark SQL概念学习系列之Spark SQL 架构分析(四)
Spark SQL 与传统 DBMS 的查询优化器 + 执行器的架构较为类似,只不过其执行器是在分布式环境中实现,并采用的 Spark 作为执行引擎. Spark SQL 的查询优化是Catalyst ...
- Spark SQL 源代码分析之 In-Memory Columnar Storage 之 in-memory query
/** Spark SQL源代码分析系列文章*/ 前面讲到了Spark SQL In-Memory Columnar Storage的存储结构是基于列存储的. 那么基于以上存储结构,我们查询cache ...
- Spark SQL Catalyst源代码分析之TreeNode Library
/** Spark SQL源代码分析系列文章*/ 前几篇文章介绍了Spark SQL的Catalyst的核心执行流程.SqlParser,和Analyzer,本来打算直接写Optimizer的,可是发 ...
- Spark SQL Catalyst源代码分析Optimizer
/** Spark SQL源代码分析系列*/ 前几篇文章介绍了Spark SQL的Catalyst的核心运行流程.SqlParser,和Analyzer 以及核心类库TreeNode,本文将具体解说S ...
- Spark SQL 源代码分析系列
从决定写Spark SQL文章的源代码分析,到现在一个月的时间,一个又一个几乎相同的结束很快,在这里也做了一个综合指数,方便阅读,下面是读取顺序 :) 第一章 Spark SQL源代码分析之核心流程 ...
随机推荐
- Selenium私房菜系列4 -- Selenium IDE的使用【QQ】
前面说过,Selenium IDE是Firefox的一个插件,是可以进行脚本录制以及案例转换,所以Selenium IDE+Firebug会成为你日后写测试案例的两大助手(IE下可以使用Seleniu ...
- SignalR+Redis,SignalR+Sqlserver集群部署应对海量链接
一:SignalR+Sqlserver 1:新建一个MVC的空项目和之前一样 2:index页面的js代码如下 <script src="~/Scripts/jquery-1.10.2 ...
- moduleNotFoundError:No module named 'exceptions'
如果pip install docx 过请先卸载,输入如下指令: pip uninstall docx 方法一: pip install python-docx 方法二: 下载: python_doc ...
- nginx 反向代理 (websocket)后报 - 400 bad request
nginx的反向代理. nginx.conf中的配置如下: location / { proxy_http_version 1.1; pro ...
- 2022强网拟态 WHOYOUARE
2022强网拟态 WHOYOUARE 先说一下这个思路 由于禁用了__proto__所以我们可以通过constructor.prototype来绕过 之前一直不明白为什么是这样绕过的后来仔细研究了一下 ...
- CentOS7安装GLPI资产管理系统
1.安装配置docker-ce此步骤不在此赘述 2.启动配置MySQL容器 mkdir -p /opt/mysql5.7/{data,conf} docker pull mysql:5.7.31 do ...
- SecureCRT保存日志
1.打开Options->Session Options...,选择LogFile 2.Log file name格式 %H_%S_%Y%M%D-%h%m%s.log 参数说明: %H---主机 ...
- 查询最上活动的activity
adb shell dumpsys window windows | grep mCurrent
- es启动和停止命令
1.启动命令 使用elasticsearch用户来启动,进入bin目录(例:home/db_app/elasticsearch/elasticsearch-6.5.4/elasticsearch-cl ...
- linux 下安装部署redis
安装: 1.获取redis资源 wget http://download.redis.io/releases/redis-4.0.8.tar.gz 2.解压 tar xzvf redis-4. ...