dfs学习笔记
题目链接
可以通过参考一道例题来加深对dfs的认知和学习
题意描述
按照字典序输出自然数 1 到 n 所有不重复的排列,即 n 的全排列,要求所产生的任一数
字序列中不允许出现重复的数字。
输出格式
由 1 ∼ n 组成的所有不重复的数字序列,每行一个序列。每个数字保留 5 个场宽。
- 数据范围 :1<= n <= 9
题目分析
输入 :
1
输出 :
1 2 3
1 3 2
2 1 3
2 3 1
3 1 2
3 2 1
观察输出样例可知,5个场宽输出的意思是每个数输出时占5个位置且右对齐,就是以
" %5d "格式输出
接着分析题目,求全排列,其实可以深搜,也就是dfs。
解题思路
算法分析
我们以 n = 3 为例,可以构造一颗搜索树来进行搜索。
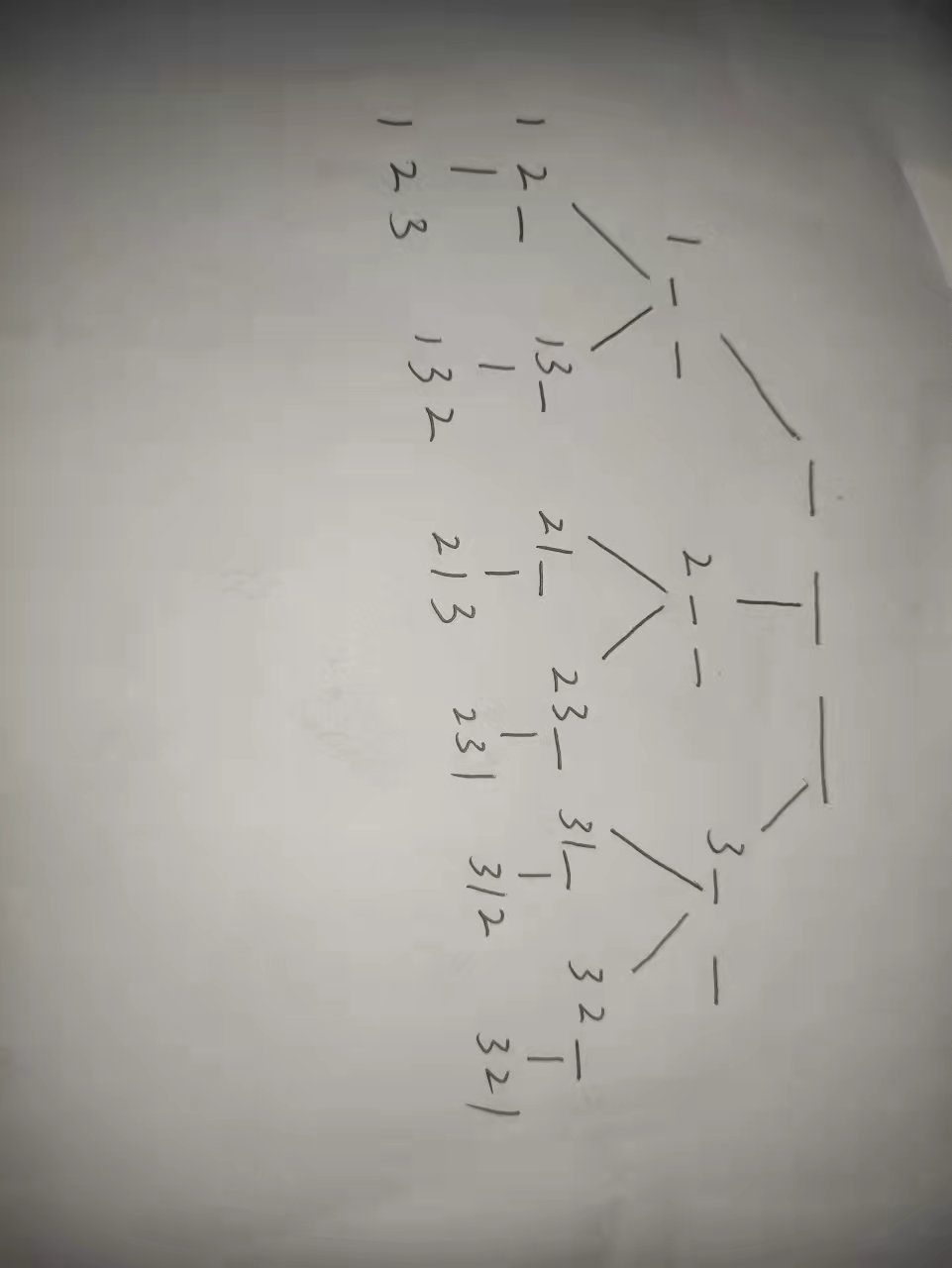
如图所示 :对一个位置进行查找,把之前没有用过的数填上去,接着对下一个位置进行
相同操作,知道每个位置填满数为止。
程序实现
我们总结一下在上一部分中的思路在程序中如何实现。
先定义两个数组,一个是用来存放解的,一个是用来标记该数是否用过。
我们可以先写一个用于打印的函数print(),每当深搜时找到一个符合条件的解时,则
print()一下,输出这个解(注意题目输出要求)。
接下来就是写深搜的函数了。主要思路:先判断格子是否填满了,如果填满,则print()一下。
如果没有填满,则开始循环,在循环中先判断当前填的数是否用过,如果没有,则填
入,搜索下一格。
代码如下
#include <iostream>
using namespace std;
const int N = 10;
int n;
int a[N];
bool q[N];
void dfs(int x){
if(x == n){
for(int i = 0 ; i < n ; i++)
printf("%5d",a[i]);
puts("");
}
for(int i = 1 ; i <= n ; i++){
if( !q[i] ){
a [x] = i;
q[i] = true ;
dfs(x+1);
q[i] = false ;
a[x] = 0;
}
}
}
int main()
{
cin >> n ;
dfs(0);
return 0;
}
dfs学习笔记的更多相关文章
- 深度优先搜索 DFS 学习笔记
深度优先搜索 学习笔记 引入 深度优先搜索 DFS 是图论中最基础,最重要的算法之一.DFS 是一种盲目搜寻法,也就是在每个点 \(u\) 上,任选一条边 DFS,直到回溯到 \(u\) 时才选择别的 ...
- DFS中的奇偶剪枝学习笔记
奇偶剪枝学习笔记 描述 编辑 现假设起点为(sx,sy),终点为(ex,ey),给定t步恰好走到终点, s | | | + — — — e 如图所示(“|”竖走,“—”横走,“+”转弯),易证abs( ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
随机推荐
- Git的使用以及常用命令(详解)
一. 版本控制工具 什么是版本控制系统? 版本控制系统(Version Control System):是一种记录一个或若干文件内容变化,以便将来查阅特定版 本修订情况的系统.版本控制系统不仅可以应用 ...
- 19.MongoDB系列之批量更新写入Groovy版
Groovy作为脚本,比Java在数据处理中具有更高的灵活性 // 获取mongo连接略 .... def count = 0 for(Township town : townships) { Doc ...
- 云计算_OpenStack
部署方式-Fuel 注:部署失败且Fuel方式已过时. 部署方式-packstack 注:基于系统版本CentOS 7.9 2009部署 系统基本设置 设置静态IP=192.168.80.60 设置h ...
- 一天一道Java面试题----第十二天(如何实现接口幂等性)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 1.如何实现接口幂等性 1.如何实现接口幂等性 唯一id.每次操作,都根据操作和内容生成唯一的id,在执行之前先判断id是 ...
- 齐博x1自定义字段关联其它字段的隐藏显示
如下图,对于单选\多选\下拉框这种表单类型, 选择某一项后, 你还想他关联其它选项的隐藏或显示,你可以加多一个参数设置处理通常情况,用得最普遍的,就是两项参数,用竖线隔开,比如下面的1|洋房2|别墅 ...
- day50-正则表达式01
正则表达式01 5.1正则表达式的作用 正则表达式的便利 在一篇文章中,想要提取相应的字符,比如提取文章中的所有英文单词,提取文章中的所有数字等. 传统方法是:使用遍历的方式,对文本中的每一个字符进行 ...
- Pycharm和IDEA利用Git操作Github仓库
1. Git Bash 选择一个本地代码仓库文件夹:D:/Github_Code/新建文件夹,然后在此目录打开git bash 依次进行: git init //首次需执行,之后可不用 git add ...
- pip 国内源 包管理
配置国内源 linux配置 修改 ~/.pip/pip.conf 文件,如下,添加了源并修改了默认超时时间 [global] timeout = 3000 index-url = http://mir ...
- 孙荣辛|大数据穿针引线进阶必看——Google经典大数据知识
大数据技术的发展是一个非常典型的技术工程的发展过程,荣辛通过对于谷歌经典论文的盘点,希望可以帮助工程师们看到技术的探索.选择过程,以及最终历史告诉我们什么是正确的选择. 何为大数据 "大 ...
- tool1
//导出 public void excel(List<Long> ids, HttpServletResponse response) { List<StockPageVo> ...