mysql-canal-kafka-kettle 数据实时同步链部署bug 填坑过程
1,因为 mysql 版本从5.7 提高到 8.0 ,需要更改用户配置。
create user 'canal'@'%' identified by 'canal';
grant select , replication slave, replication client on *.* to 'canal'@'%';
还有改变用户鉴权方式;MySQL 8.0.3开始,身份验证插件默认使用caching_sha2_password
2,canal 有问题。 没启动。
因为是政府项目,使用的中标麒麟系统。
报错:VM option 'UseG1GC' is experimental and must be enabled via -XX:+UnlockExperimentalVMOptions.
-XX:+UseG1GC -Xss2m
startup.sh 脚本内删除- -XX:+UseG1GC ,增加 -XX:+UnlockExperimentalVMOptions 。 后续又报错 stack size 太小问题,增大就好
3,kafka 启动失败。
之前有运维启动了独立的zookeeper , 而不是 kafka 内置的zookeeper . 可能导致了这个问题。
爆错: 当前的集群id 和 meta.propoties内不一致。
方法: 在文件内修改了cluster id .
4,canal 内部的kafka producer 组件不能 更新 元数据库。
Caused by: java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms.
at org.apache.kafka.clients.producer.KafkaProducer$FutureFailure.<init>(KafkaProducer.java:1150) ~[na:na]
at org.apache.kafka.clients.producer.KafkaProducer.doSend(KafkaProducer.java:846) ~[na:na]
at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:784) ~[na:na]
at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:671) ~[na:na]
方法: 因为 全部组件都放在一个机器。 所以 配置了127.0.0.1,但是找不到zookeeper集群。 措施是canel 配置全部改成内网ip 。 消息进入kafka 。
5,kettle 中启动 pan.sh ,但是 启动失败。
报错:
Can't run transformation due to plugin missing
2022/11/11 15:27:10 - Kafka consumer.0 - ERROR (version 8.2.0.0-342, build 8.2.0.0-342 from 2018-11-14 10.30.55 by buildguy) : Error initializing step [Kafka consumer]
2022/11/11 15:27:10 - kafka_ktr_production - ERROR (version 8.2.0.0-342, build 8.2.0.0-342 from 2018-11-14 10.30.55 by buildguy) : Step [Kafka consumer.0] failed to initialize!
方法:根据https://forums.pentaho.com/方法,下载 pentaho-kafka-consumer 到插件文件夹。问题解决。
下载地址:https://github.com/RuckusWirelessIL/pentaho-kafka-consumer/releases/tag/v1.7
6,上述kafka 消费setp 解决完之后,直接在kettel 的最后一个step 报错:
报错:执行SQL脚本.0 - ERROR (version 8.2.0.0-342, build 8.2.0.0-342 from 2018-11-14 10.30.55 by buildguy) : An error occurred, processing will be stopped:
2022/11/16 10:03:38 - 执行SQL脚本.0 - Error occurred while trying to connect to the database
2022/11/16 10:03:38 - 执行SQL脚本.0 -
2022/11/16 10:03:38 - 执行SQL脚本.0 - Driver class 'org.gjt.mm.mysql.Driver' could not be found, make sure the 'MySQL' driver (jar file) is installed.
2022/11/16 10:03:38 - 执行SQL脚本.0 - org.gjt.mm.mysql.Driver
方法: 手动添加 mysql 8 driver 到 /lib 目录下。
继续报错:不能连接到server 服务器.
方法:报出的问题描述比较模糊,所以直接从基本需求出发,搜索kettle 8 如何连接 mysql 8的问题。 随后答案清晰;
kettle 官方论坛:
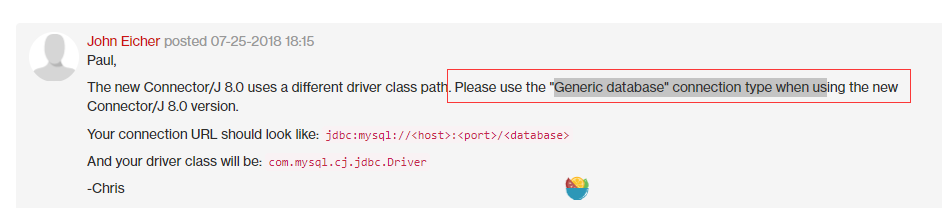
要求对 kettle转换中的step 进行重新配置。改为 ‘generic database(通用数据库)’ ,设置URL 和 驱动类名。
最后,kettel 的 pan.sh 启动成功。 源数据MySQL的 binlog 日志进入kafka , kafka 消息进入kettle 处理后变成sql 语句插入到 目标mysql (版本8).
mysql-canal-kafka-kettle 数据实时同步链部署bug 填坑过程的更多相关文章
- canal整合springboot实现mysql数据实时同步到redis
业务场景: 项目里需要频繁的查询mysql导致mysql的压力太大,此时考虑从内存型数据库redis里查询,但是管理平台里会较为频繁的修改增加mysql里的数据 问题来了: 如何才能保证mysql的数 ...
- Mysql数据实时同步
企业运维的数据库最常见的是 mysql;但是 mysql 有个缺陷:当数据量达到千万条的时候,mysql 的相关操作会变的非常迟缓; 如果这个时候有需求需要实时展示数据;对于 mysql 来说是一种灾 ...
- 【转】美团 MySQL 数据实时同步到 Hive 的架构与实践
文章转载自公众号 美团技术团队 , 作者 萌萌 背景 在数据仓库建模中,未经任何加工处理的原始业务层数据,我们称之为ODS(Operational Data Store)数据.在互联网企业中,常见的 ...
- mysql数据实时同步到Elasticsearch
业务需要把mysql的数据实时同步到ES,实现低延迟的检索到ES中的数据或者进行其它数据分析处理.本文给出以同步mysql binlog的方式实时同步数据到ES的思路, 实践并验证该方式的可行性,以供 ...
- MySQL 到 ES 数据实时同步技术架构
MySQL 到 ES 数据实时同步技术架构 我们已经讨论了数据去规范化的几种实现方式.MySQL 到 ES 数据同步本质上是数据去规范化多种实现方式中的一种,即通过"数据迁移同步" ...
- Linux下Rsync+sersync实现数据实时同步
inotify 的同步备份机制有着缺点,于是看了sersync同步,弥补了rsync的缺点.以下转自:http://www.osyunwei.com/archives/7447.html 前言: 一. ...
- sersync实现数据实时同步
1.1 第一个里程碑:安装sersync软件 1.1.1 将软件上传到服务器当中并解压 1.上传软件到服务器上 rz -E 为了便于管理上传位置统一设置为 /server/tools 中 2.解压软件 ...
- Rsync+sersync实现数据实时同步
前言: 一.为什么要用Rsync+sersync架构? 1.sersync是基于Inotify开发的,类似于Inotify-tools的工具 2.sersync可以记录下被监听目录中发生变化的(包括增 ...
- Linux下Rsync+Inotify-tools实现数据实时同步
Linux下Rsync+Inotify-tools实现数据实时同步 注意:下面的三个案例都是rsync 每次都是全量的同步(这就坑爹了),而且 file列表是循环形式触发rsync ,等于有10个文件 ...
- CentOS7下Rsync+sersync实现数据实时同步
近期公司要上线新项目,后台框架选型我选择当前较为流行的laravel,运行环境使用lnmp. 之前我这边项目tp32+apache,开发工具使用phpstorm. 新建/编辑文件通过phpstorm配 ...
随机推荐
- 四数相加II & 赎金信 & 三数之和 & 四数之和
一.四数相加Ⅱ 454. 四数相加 II 1.方法概述 首先定义一个map,key放a和b两数之和,value 放a和b两数之和出现的次数.遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到 ...
- 银河麒麟服务器操作系统安装VMware Tool
安装前提:确保虚拟机连接iso 注:因为我已经安装过VMware Tools,因此此时是显示重新安装 点击重新安装后,会弹出如下对话框,选择"是" 选择"确定" ...
- UBUNTU切换内核
查询可更换内核的序号 gedit /boot/grub/grub.cfg查询已安装的内核和内核的序号.找到文件中的menuentry (图中在一大堆fi-else底下)menuentry底下还有 ...
- web自动化中如何使用cookie登录
做web自动化的时候,登录是关键的一步.但每次频繁的输入用户名.密码导致心态有些爆炸,所以使用cookie登录势在必行.下面是两种场景的cookie登录. 一. cookie登录1 这种是界面地址跳转 ...
- JZOJ 3207.Orthogonal Anagram
\(\text{Problem}\) 给出一个字符串,求经过重新排列的另一个字典序最小的字符串,满足:相同的位置上 原串与结果串的字符不同.不存在则输出空串. \(\text{Solution}\) ...
- 使用IDM从Google 云端硬盘链接上下载超大文件
1.将原始文件以快捷方式存放到自己的网盘中. 2.进入自己的网盘,找到存放好的目标文件快捷方式,点击右键,选择下载. 3.如果电脑上IDM且浏览器装有IDM插件,会弹出下载框,点击下载即可. 4.然后 ...
- SQL 注入之:SQL Server 数据库
郑重声明: 本笔记编写目的只用于安全知识提升,并与更多人共享安全知识,切勿使用笔记中的技术进行违法活动,利用笔记中的技术造成的后果与作者本人无关.倡导维护网络安全人人有责,共同维护网络文明和谐. SQ ...
- vue 获取select选中的当前option所在对象的各种值
- LeetCode-539 最小时间差
来源:力扣(LeetCode)链接:https://leetcode-cn.com/problems/minimum-time-difference 题目描述 给定一个 24 小时制(小时:分钟 &q ...
- LeetCode-846 一手顺子
来源:力扣(LeetCode)链接:https://leetcode-cn.com/problems/hand-of-straights 题目描述 Alice 手中有一把牌,她想要重新排列这些牌,分成 ...