论文解读(CDTrans)《CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation》
论文信息
论文标题:CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation
论文作者:Tongkun Xu, Weihua Chen, Pichao Wang, Fan Wang, Hao Li, Rong Jin
论文来源:ICLR 2022
论文地址:download
论文代码:download
1 Introduction
无监督域自适应(Unsupervised domain adaptation,UDA)的目的是将从标记源域学习到的知识转移到不同的未标记目标域。
UDA 方法:
① Domain-level UDA ,通过将源域和目标域在不同尺度水平上进入相同的分布来缓解源域之间的分布差异;
② fine-grained category-level UDA,通过将目标样本推向每个类别中的源样本的分布,对源域数据和目标域数据之间的每个类别分布进行对齐;(仍然存在标签噪声问题)
2 Method
2.1 The cross attention in Transformer
传统的方法给目标域打伪标签的过程中存在噪声,由于噪声的存在,需要对齐的源域和目标域的图片可能不属于同一类,强行对其可能产生很大的负面影响。而本文经过实验发现 Transformer 中的 CrossAttention 可以有效的避免噪声给对其造成的影响,CrossAttention 更多的关注源域和目标域中图片中的相似信息。换句话说,即使图片对不属于同一类,被拉近的也只会是两者相似的部分。因此,CDTrans 具有一定的抗噪能力。
由于在 UDA 任务中,目标域是没有标签的。因此只能借鉴伪标签的思路,来生成潜在的可能属于同一个 ID 的样本对。但是,伪标签生成的样本对中不可避免的会存在噪声。这时,本文发现 Cross Attention 对样本对中的噪声有着很强的鲁棒性。本文分析这主要是因为 Attention 机制所决定的,Attention 的 weight 更多的会关注两张图片相似的部分,而忽略其不相似的部分。如果源域图片和目标域图片不属于同一个类别的话,比如Figure 1.a“Car vs. Truck”的例子,Attention 的 weight 主要集中于两个图片中相似部分的对齐(比如轮胎),而对其他部位的对齐会给很小的 weight。
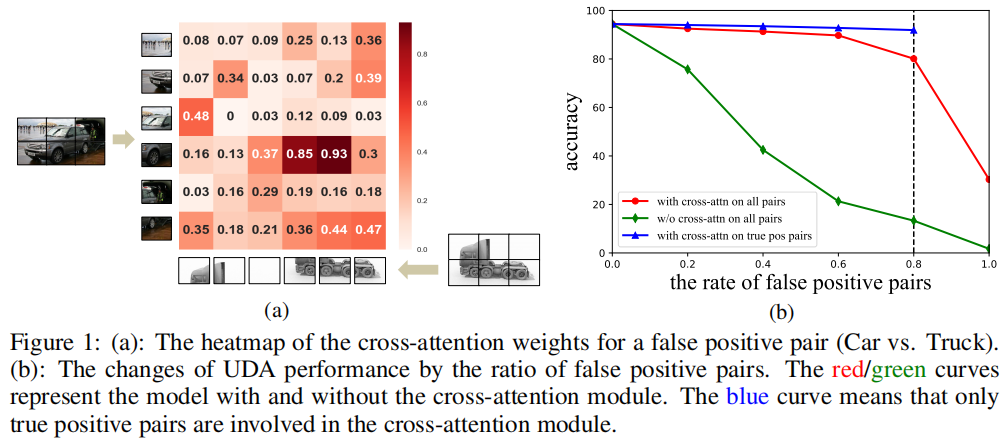
换句话说,Cross Attention 没有在使劲拉近对齐小轿车和卡车,而更多的是在努力对齐两个图片中的轮胎。一方面,Cross Attention 避免了强行拉近小轿车和卡车,减弱了噪声样本对 UDA 训练的影响;另一方面,拉近不同域的轮胎,在一定程度上可能帮助到目标域轮胎的识别。
自注意力(self-attention):
$\operatorname{Attn}_{\text {self }}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\operatorname{softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{T}}{\sqrt{d_{k}}}\right) \boldsymbol{V}\quad\quad(1)$
交叉注意力(cross-attention):
$\operatorname{Attn}_{\text {cross }}\left(\boldsymbol{Q}_{s}, \boldsymbol{K}_{t}, \boldsymbol{V}_{t}\right)=\operatorname{softmax}\left(\frac{\boldsymbol{Q}_{s} \boldsymbol{K}_{t}^{T}}{\sqrt{d_{k}}}\right) \boldsymbol{V}_{t}\quad\quad(2)$
2.2 Two way center-aware pseudo labeling
2.2.1 Two way labeling
为了构建交叉注意模块的训练对,一种直观的方法是,对源域中的每一幅图像,我们设法从目标域找到最相似的图像。所选数据对的设置 $\mathbb{P}_{S}$ 为:
$\mathbb{P}_{S}=\left\{(s, t) \mid t=\underset{k}{\text{min}} \quad d\left(\boldsymbol{f}_{s}, \boldsymbol{f}_{k}\right), \forall k \in T, \forall s \in S\right\}\quad\quad\quad(3)$
其中,$S$、$T$ 分别为源数据和目标数据。$d\left(\boldsymbol{f}_{i}, \boldsymbol{f}_{j}\right)$ 表示图像 $i$ 和图像 $j$ 的特征之间的距离。
这种策略的优点是充分利用源数据,而其弱点显然是只涉及到目标数据的一部分。为了消除目标数据的这种训练偏差,我们从相反的方式引入了更多的对 $\mathbb{P}$,包括所有目标数据及其在源域中最相似的图像。
$\mathbb{P}_{T}=\left\{(s, t) \mid s=\underset{k}{\text{min}} \quad d\left(\boldsymbol{f}_{t}, \boldsymbol{f}_{k}\right), \forall t \in T, \forall k \in S\right\}\quad\quad\quad(4)$
因此,最终的 $\mathbb{P}$ 是两个集的并集,即 $\mathbb{P}=\left\{\mathbb{P}_{S} \cup \mathbb{P}_{T}\right\}$,使训练对包括所有的源数据和目标数据。
2.2.2 Center-Aware filtering
$\mathbb{P}$ 中的 pair 是基于两个域图像的特征相似性构建的,因此 pair 的伪标签的准确性高度依赖于特征相似性。
本文发现,源数据的预训练模型也有助于进一步提高精度。首先,我们通过将所有目标数据送到通过预先训练的模型,从分类器得到它们在源类别上的概率分布 $\delta$。这些分布可以通过加权 k-means 聚类来计算目标域内每个类别的初始中心:
${\large \boldsymbol{c}_{k}=\frac{\sum_{t \in T} \delta_{t}^{k} \boldsymbol{f}_{t}}{\sum_{t \in T} \delta_{t}^{k}}}\quad\quad(5) $
其中,$\delta_{t}^{k}$ 表示图像 $t$ 在类别 $k$ 上的概率。目标数据的伪标签可以通过最近邻分类器产生:
$y_{t}=\arg \underset{k}{\text{min}} \; d\left(\boldsymbol{c}_{k}, \boldsymbol{f}_{t}\right) \quad\quad(6) $
其中,$t \in T$ 和 $d(i, j)$ 是特征 $i$ 和 $j$ 的距离。基于伪标签,我们可以计算出新的中心:
${\normalsize \boldsymbol{c}_{k}^{\prime}=\frac{\sum_{t \in T} \mathbb{1}\left(y_{t}=k\right) \boldsymbol{f}_{t}}{\sum_{t \in T} \mathbb{1}\left(y_{t}=k\right)}} \quad\quad(7) $
2.3 CDTrans:Cross-Domain Transformer
框架如下:
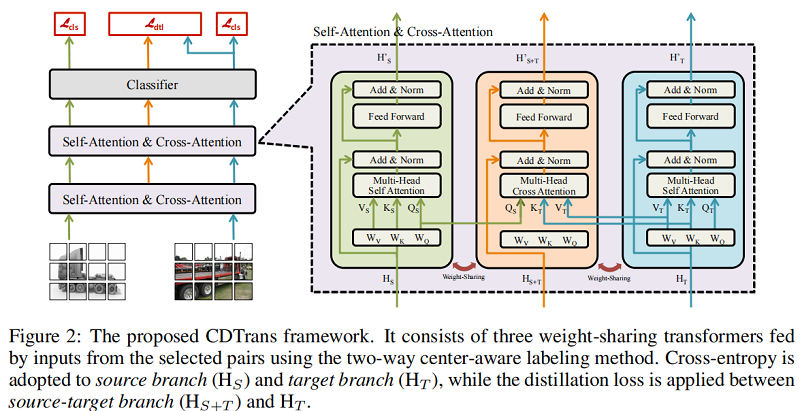
上述 CDTrans 框架包括三个权重共享的 transformer ,分别是 source branch, source-target branch, target branch 。
输入对中的源图像和目标图像分别被发送到 source branch 和 target branch 。在这两个分支中,self-attention 涉及到学习特定领域的表示。并利用 softmax cross-entropy loss 进行分类训练。值得注意的是,由于两个图像的相同标签,所有三个分支共享相同的分类器。交叉注意力模块被导入到 source-target branch 中。source-target branch 的输入来自其他两个分支。在第 $N$ 层中,交叉注意模块的 query 来自于source branch 的第 $N$ 层中的查询,而 key 和 value 来自于 target branch 的查询。source-target branch 的特征不仅对齐了两个域的分布,而且由于交叉注意模块,对输入对中的噪声具有鲁棒性。因此,本文使用 source-target branch 的输出来指导目标分支的训练。具体来说,source-target branch 和目标分支分别表示为 teacher 和 student 。本文将分类器在 source-target branch 中的概率分布作为一个软标签,可以通过蒸馏损失来进一步监督目标分支
${\large L_{d t l}=\sum\limits_{k} q_{k} \log p_{k}} \quad\quad(8) $
其中,$q_{k}$ 和 $p_{k}$ 分别是 source-target branch 和 target branch 的概率。
论文解读(CDTrans)《CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation》的更多相关文章
- [论文解读] 阿里DIEN整体代码结构
[论文解读] 阿里DIEN整体代码结构 目录 [论文解读] 阿里DIEN整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x04 模型基类 4.1 基本逻辑 ...
- CVPR2020论文解读:三维语义分割3D Semantic Segmentation
CVPR2020论文解读:三维语义分割3D Semantic Segmentation xMUDA: Cross-Modal Unsupervised Domain Adaptation for 3 ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(上)
自监督学习(Self-Supervised Learning)多篇论文解读(上) 前言 Supervised deep learning由于需要大量标注信息,同时之前大量的研究已经解决了许多问题.所以 ...
- 论文解读丨表格识别模型TableMaster
摘要:在此解决方案中把表格识别分成了四个部分:表格结构序列识别.文字检测.文字识别.单元格和文字框对齐.其中表格结构序列识别用到的模型是基于Master修改的,文字检测模型用到的是PSENet,文字识 ...
- NLP论文解读:无需模板且高效的语言微调模型(上)
原创作者 | 苏菲 论文题目: Prompt-free and Efficient Language Model Fine-Tuning 论文作者: Rabeeh Karimi Mahabadi 论文 ...
- 论文解读(SR-GNN)《Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data》
论文信息 论文标题:Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data论文作者:Qi Zhu, ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- Gaussian field consensus论文解读及MATLAB实现
Gaussian field consensus论文解读及MATLAB实现 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.Introduction ...
随机推荐
- 在 Kubernetes 集群中使用 NodeLocal DNSCache
转载自:https://www.qikqiak.com/post/use-nodelocal-dns-cache/ NodeLocal DNSCache 通过在集群节点上运行一个 DaemonSet ...
- Elasticsearch Dockerfile 例子
文章转载自:https://elasticstack.blog.csdn.net/article/details/111692444 前提条件 在继续执行本教程中概述的步骤之前,你需要具备一个关键的先 ...
- Mysql三种日志(binlog,redolog,undolog)的作用和区别
Mysql有三种很重要的日志也是面试经常涉及到的考点,分别是 binlog .redo log和undo log, 这里面binlog 是server层实现的日志,而redo log 和undo lo ...
- PAT (Basic Level) Practice 1005 继续(3n+1)猜想 分数 25
卡拉兹(Callatz)猜想已经在1001中给出了描述.在这个题目里,情况稍微有些复杂. 当我们验证卡拉兹猜想的时候,为了避免重复计算,可以记录下递推过程中遇到的每一个数.例如对 n=3 进行验证的时 ...
- 如何评判一个企业是否需要实施erp系统?
一个企业是否需要实施ERP系统很大程度上取决于其规模.这里需要向提问者说明的一点是:很多企业上ERP,并不会用得到MRP,ERP是企业资源计划,不是制造业企业专用,MRP也不是ERP必须,金融.保险之 ...
- NSIS查找文本中是否包含某个字串
!include "textfunc.nsh"!include "logiclib.nsh"OutFile "find.exe"#文本文件a ...
- C#/VB.NET 读取条码类型及条码在图片中的坐标位置
我们在创建条形码时,如果以图片的方式将创建好的条码保存到指定文件夹路径,可以在程序中直接加载图片使用:已生成的条码图片,需要通过读取图片中的条码信息,如条码类型.条码绘制区域在图片中的四个顶点坐标位置 ...
- Qemu/Limbo/KVM镜像 Ubuntu 22.04 精简版,可运行Windows软件,内存占用不到200M
镜像特征: Ubuntu 22.04系统 内置Wine 7.8,可运行大量Windows 软件 高度精简,内存占用仅200M不到. 自制UI,Windows3.1风格. 完全开源 镜像说明: 用户名为 ...
- Go实现优雅关机与平滑重启
前言 优雅关机就是服务端关机命令发出后不是立即关机,而是等待当前还在处理的请求全部处理完毕后再退出程序,是一种对客户端友好的关机方式.而执行Ctrl+C关闭服务端时,会强制结束进程导致正在访问的请求出 ...
- C++面向对象编程之类模板、函数模板等一些补充
1.static数据 和 static函数: 对于 非static函数 在内存中只有一份,当类对象调用时,其实会有该对象的this pointer传进去,那个函数就知道要对那个对象进行操作: stat ...