Django批量插入(自定义分页器)
一:批量插入
1.常规批量插入数据(时间长,效率低 不建议使用)
def ab_pl(request):
# 先给Book插入一万条数据
for i in range(10000):
models.Book.objects.create(title='第%s本书'%i)
# 再将所有的数据查询并展示到前端页面
book_queryset = models.Book.objects.all()
2.使用orm提供的bulk_create方法批量插入数据(效率高 减少操作时间)
def ab_pl(request):
# 批量插入
# 1.定义一个列表
book_list = []
# 循环批量插入
for i in range(10000):
book_obj = models.Book(title='第%s本书'%i)
# 将循环书籍添加到列表内
book_list.append(book_obj)
# 批量插入列表
models.Book.objects.bulk_create(book_list)
# 返回到页面 locals 将当前名称空间内数据全部返回到页面
return render(request,'ab_pl.html',locals())
- ab_pl
{#循环数据#}
{% for book_obj in book_list %}
<p>{{ book_obj.title }}</p>
{% endfor %}
3.总结
当你想要批量插入数据的时候 使用orm给你提供的bulk_create能够大大的减少操作时间
二:自定义分页器
1.自定义分页器简介
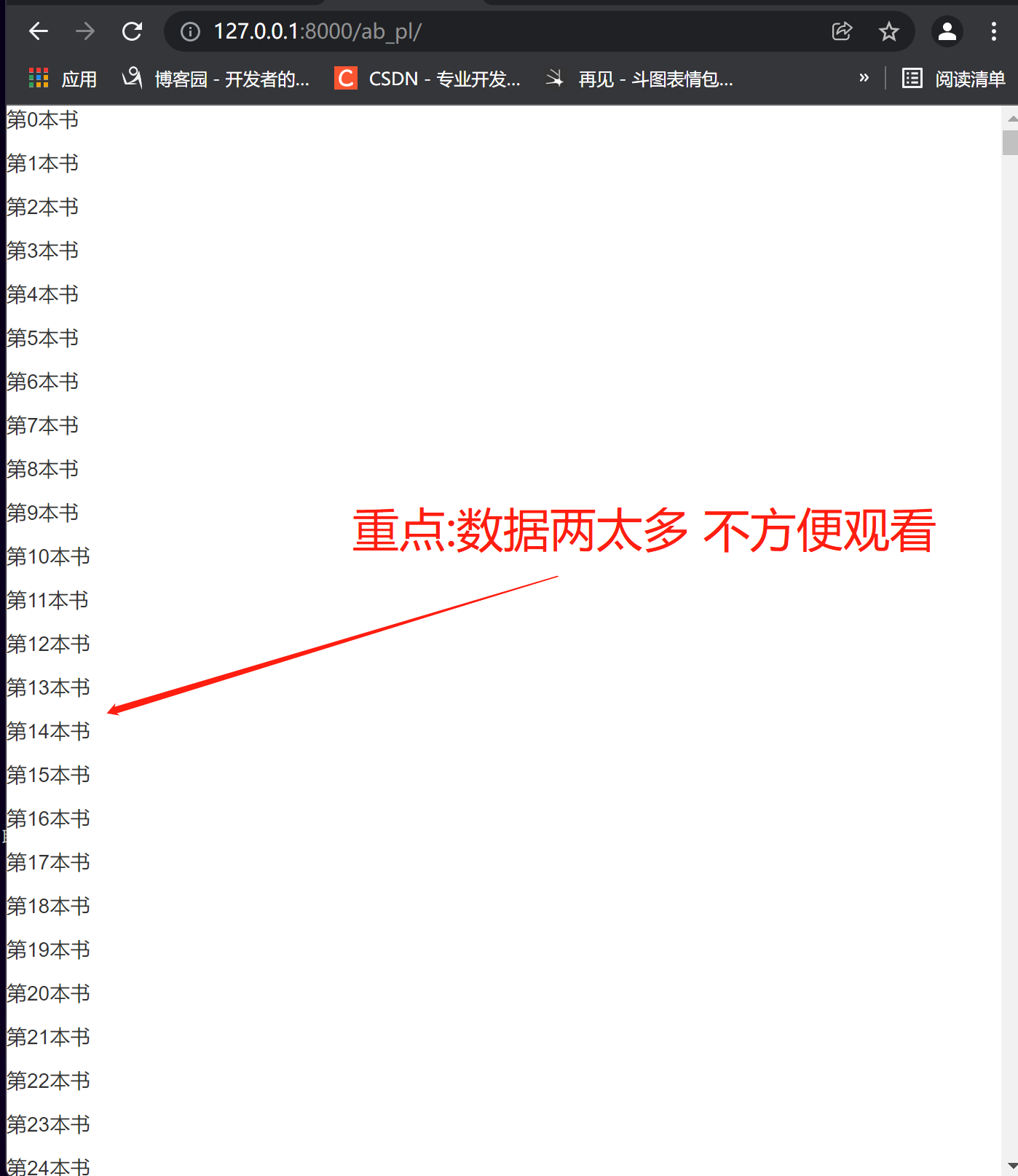
1.针对上一小节批量插入的数据,我们在前端展示的时候发现一个很严重的问题,一页展示了索引的数据,数据量太大,查看不方便
2.针对数据量大但又需要全部展示给用户观看的情况下,我们统一做法都是做分页处理。
2.分页推导
1.首先我们需要明确的时候,get请求也是可以携带参数的,索引我们在朝后端发送查看数据的同时可以携带一个参数告诉后端我们想看第几页的数据。
2.其次我们还需要知道一个点,queryset对象是支持索引取值和切片操作的,但是不支持负数索引情况。
接下来我们就可以推导我们的自定义分页器步骤了:
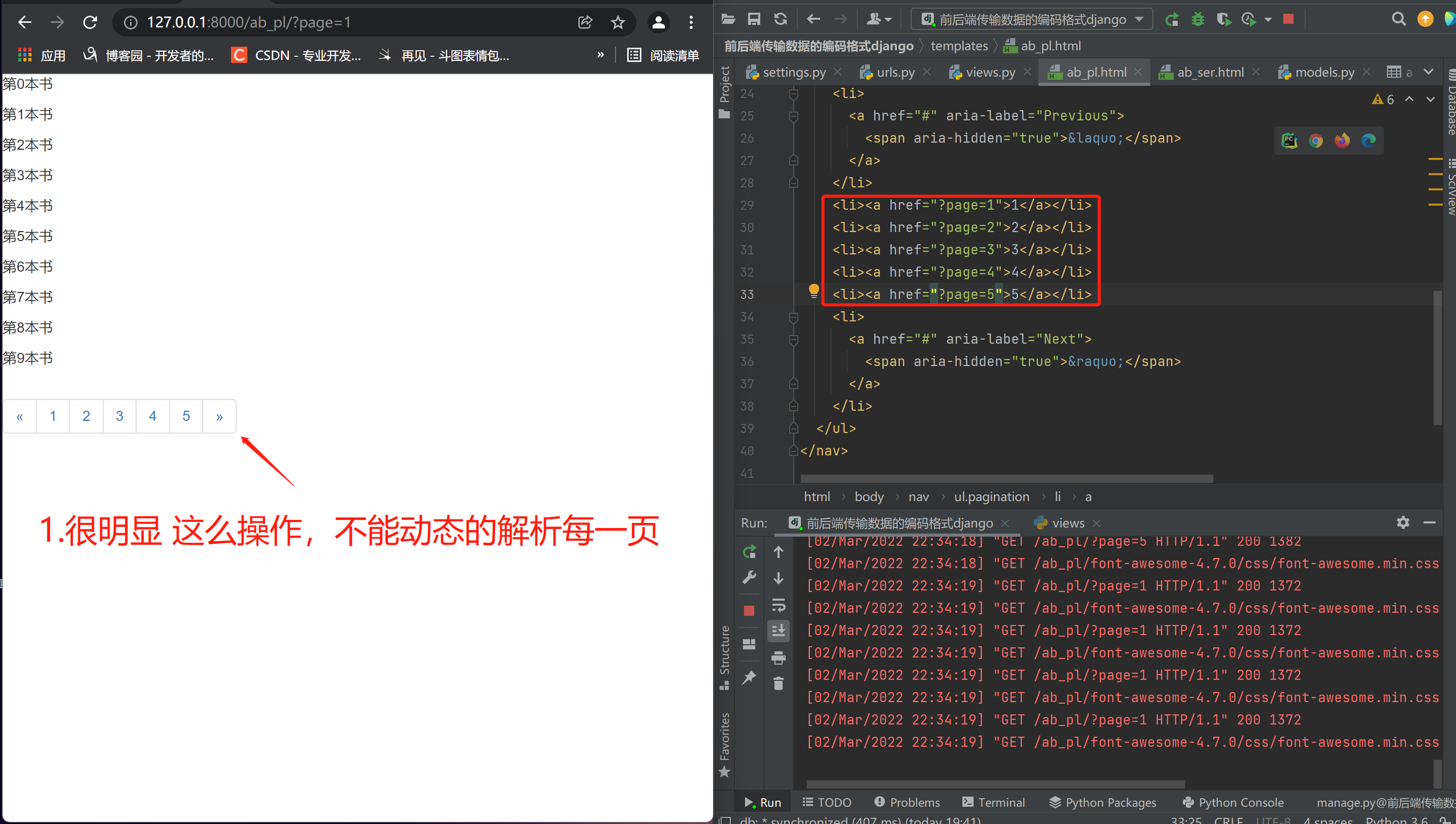
3.自定义分页(依靠索引切片 不能动态解析)
def ab_pl(request):
# 想访问那一页
current_page = request.GET.get('page', 1) # 获取用户想访问的页码 如果没有 默认展示第一页
# 数据类型转换
try: # 由于后端接受到的前端数据是字符串类型所以我们这里做类型转换处理加异常捕获
current_page = int(current_page)
except Exception:
current_page = 1 # 转换失败 默认等于1
# 每页展示多少条
per_page_num = 10
# 起始位置
# start_page = 0
start_page = (current_page - 1) * per_page_num
# 终止位置
# end_page = 0
end_page = current_page * per_page_num
# 分页 # 起始位置 终止位置
book_queryset = models.Book.objects.all()[start_page:end_page]
return render(request,'ab_pl.html',locals())
动态计算/解析出 起始位置 与 终止位置
# 每页展示10条
per_page_num = 10
页 起始位置 终止位置
current_page start_page end_page
1 0 10
2 10 20
3 20 30
4 30 40
# 每页展示5条
per_page_num = 5
页 起始位置 终止位置
current_page start_page end_page
1 0 5
2 5 10
3 10 15
4 15 20
计算出 起始位置 与 终止位置
0 = (1 - 1) * 5
start_page = (current_page - 1) * per_page_num
5 = 1 * 5
end_page = current_page * per_page_num
4.html
{#循环数据#}
{% for book_obj in book_queryset %}
<p>{{ book_obj.title }}</p>
{% endfor %}
<nav aria-label="Page navigation">
<ul class="pagination">
<li>
<a href="#" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
<li><a href="?page=1">1</a></li>
<li><a href="?page=2">2</a></li>
<li><a href="?page=3">3</a></li>
<li><a href="?page=4">4</a></li>
<li><a href="?page=5">5</a></li>
<li>
<a href="#" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
</ul>
</nav>
三:自定义分页器(通过代码动态的计算出到底需要多少页)
1.需求与分析
总数据100 每页展示10 需要10
总数据101 每页展示10 需要11
总数据99 每页展示10 需要10
1.在制作页码个数的时候 一般情况下都是奇数个 符合中国人对称美的标准
2.内置方法之divmod
内置方法之divmod
>>> divmod(100,10)
(10, 0) # 10页
>>> divmod(101,10)
(10, 1) # 11页
>>> divmod(99,10)
(9, 9) # 10页
# 余数只要不是0就需要在第一个数字上加一
3.显示每页数据实现
- 我们可以判断元祖的第二个数字是否为0从而确定到底需要多少页来展示数据
# 1.当前数据的总条数
book_list = models.Book.objects.all()
# 2.计算出到底需要多少页
all_count = book_list.count() # 数据总条数
# 3. 页 余数 总条数 每一页多少条
page_count, more = divmod(all_count, per_page_num)
if more:
# 如果more有余数就给page_count加1 没有就没有
page_count += 1
至此分页器大致的功能及思路我们就已经大致清楚了
4.最后我们只需要利用start_page和end_page对总数据进行切片取值再传入前端页面就能够实现分页展示
# 分页 # 起始位置 终止位置
book_queryset = book_list[start_page:end_page]
return render(request,'ab_pl.html',locals())
5.接下来就是前端页面的代码编写了
{#循环数据#}
{% for book_obj in book_queryset %}
<p>{{ book_obj.title }}</p>
{% endfor %}
现在我们实现了最简单的分页,但是前端没有按钮去让用户点击需要看第几页,所以我们需要渲染分页器相关代码,这里我们不做要求直接去bootstrap框架拷贝代码即可
6.自定义分页器实现
def ab_pl(request):
# 想访问那一页
current_page = request.GET.get('page', 1) # 获取用户想访问的页码 如果没有 默认展示第一页
# 数据类型转换
try: # 由于后端接受到的前端数据是字符串类型所以我们这里做类型转换处理加异常捕获
current_page = int(current_page)
except Exception as e:
current_page = 1 # 转换失败 默认等于1
# 每页展示多少条
per_page_num = 10
# 起始位置
# 起始位置 = (页 - 1) * 10
start_page = (current_page - 1) * per_page_num
# 终止位置
# 终止位置 = 页 * 10
end_page = current_page * per_page_num
# 1.定义空字符串
page_html = ''
# 限制负数
xxx = current_page
# 当前页数小于6
if current_page < 6:
# 就让当前页数等于6
current_page = 6
# 当前页面 减 5 加 6
for i in range(current_page - 5, current_page +5):
# 判断用户想访问的页数是否等于循环出来的页数
if xxx == i: # 高亮显示
page_html += '<li class="active"><a href="?page=%s">%s</a></li>'%(i, i)
else:
page_html += '<li><a href="?page=%s">%s</a></li>'%(i, i)
ab_pl.html
{#循环数据#}
{% for book_obj in book_queryset %}
<p>{{ book_obj.title }}</p>
{% endfor %}
<nav aria-label="Page navigation">
<ul class="pagination">
<li>
<a href="#" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
{#前端模板语法没有range 后端封装 传到前端#}
{{ page_html|safe }} {# 转义 #}
<li>
<a href="#" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
</ul>
</nav>
1.django中有自带的分页器模块 但是书写起来很麻烦并且功能太简单
所以我们自己想法和设法的写自定义分页器
2.我们基于上述的思路 已经封装好了我们自己的自定义分页器
之后需要使用直接拷贝即可
Django批量插入(自定义分页器)的更多相关文章
- django ajax 及批量插入数据 分页器
``` Ajax 前端朝后端发送请求都有哪些方式 a标签href GET请求 浏览器输入url GET请求 form表单 GET/POST请求 Ajax GET/POST请求 前端朝后端发送数据的编码 ...
- Django批量插入数据和分页器
目录 一.ajax结合sweetalert实现删除按钮动态效果 二.bulk_create批量插入数据 1. 一条一条插入 2. 批量插入 三.自定义分页器 一.ajax结合sweetalert实现删 ...
- Django基础之自定义分页器
自定义分页器 针对批量插入的数据,我们在前端展示的时候发现一个很严重的问题,一页展示了所有的数据,数据量太大,查看不方便 针对数据量大但又需要全部展示给用户观看的情况下,我们统一做法都是做分页处理 分 ...
- django中的自定义分页器
1.什么是自定义分页器 当我们需要在前端页面展示的数据太多的时候,我们总不能将数据展示在一页上面吧!这时,我们就需要自定义一个分页器,将数据分成特定的页数进行展示,每一页展示固定条数的数据! 2.为什 ...
- django之ajax结合sweetalert使用,分页器和bulk_create批量插入 07
目录 sweetalert插件 bulk_create 批量插入数据 分页器 简易版本的分页器的推导 自定义分页器的使用(组件) sweetalert插件 有这么一个需求: 当用户进行一个删除数据 ...
- Django ajax的简单使用、自定义分页器
一. ajax初识 1. 前后端传输数据编码格式contentType 使用form表单向后端提交数据时,必须将form表单的method由默认的get改为post,如果提交的数据中包含文件,还要将f ...
- django----Sweetalert bulk_create批量插入数据 自定义分页器
目录 一.Sweetalert使用AJAX操作 二.bulk_create 三.分页器 divmod 分页器组件 自定义分页器的使用 一.Sweetalert使用AJAX操作 sweetalert ...
- Django-choices字段值对应关系(性别)-MTV与MVC科普-Ajax发json格式与文件格式数据-contentType格式-Ajax搭配sweetalert实现删除确认弹窗-自定义分页器-批量插入-07
目录 models 字段补充 choices 参数/字段(用的很多) MTV与MVC模型 科普 Ajax 发送 GET.POST 请求的几种常见方式 用 Ajax 做一个小案例 准备工作 动手用 Aj ...
- django与ajax:ajax结合sweetalter ,批量插入数据 ;分页器组件
目录 一.ajax结合sweetalter 二.bulk_create批量插入数据 三.简易版分页器推导 1. 推导步骤 四.自定义分页器的使用 1. 自定义分页器模板 2. 使用方法 (1)后端代码 ...
- [Django高级之批量插入数据、分页器组件]
[Django高级之批量插入数据.分页器组件] 批量插入数据 模板层models.py from django.db import models class Books(models.Model): ...
随机推荐
- 8.maven上传jar包以及SNAPSHOT的一个坑
1,手动上传包 如何将一些新的外部包上传到私服当中呢? 首先是要登录上去,然后点击 Upload,找到 maven-local将jar包找到选中,然后填写对应的三个定位信息即可上传. 在引用的时候,道 ...
- git-flow模型
git-flow 是在 git branch 和 git tag 基础上封装出来的代码分支管理模型,把实际开发模拟称 master develop feature release hotfix sup ...
- Git使用与心得体会
Git使用与心得体会 一.闲聊 闲暇时间学一下Git,也算是不用在网页端操作github了 二.Git相关 集中式与分布式 Git是一个分布式的版本控制系统,而传统的SVN则属于集中式 集中式与分布式 ...
- 《基于Apache Flink的流处理》读书笔记
前段时间详细地阅读了 <Apache Flink的流处理> 这本书,作者是 Fabian Hueske&Vasiliki Kalavri,国内崔星灿翻译的,这本书非常详细.全面得介 ...
- 手写编程语言-如何为 GScript 编写标准库
版本更新 最近 GScript 更新了 v0.0.11 版本,重点更新了: Docker 运行环境 新增了 byte 原始类型 新增了一些字符串标准库 Strings/StringBuilder 数组 ...
- java.util.Arrays----操作数组的工具类
java.util.Arrays操作数组的工具类,里面定义了很多操作数组的方法 1.boolean equals(int[] a,int[] b):判断两个数组是否相等. 2.String toStr ...
- JPA入门学习集合springboot(一)
1.在pom.xml文件中添加相应依赖 SpringData jpa和数据库MySql <!-- Spring Data JPA 依赖(重要) --> <dependency> ...
- http://localhost:8282/user/findsomeuser[object%20Object]
查看vue中的方法的访问路径是否填写正确. 后端:
- 齐博x1标签之异步加载标签数据
为什么要异步加载标签?他有什么好处 如果一个页面的标签太多,又或者是页面中某一个标签调用数据太慢的话,就会拖慢整个页面的打开,非常影响用户体验.这个时候,用异步加载的话,就可以一块一块的显示,用户体验 ...
- 一篇文章带你了解服务器操作系统——Linux简单入门
一篇文章带你了解服务器操作系统--Linux简单入门 Linux作为服务器的常用操作系统,身为工作人员自然是要有所了解的 在本篇中我们会简单介绍Linux的特点,安装,相关指令使用以及内部程序的安装等 ...