探究Presto SQL引擎(4)-统计计数
作者:vivo互联网用户运营开发团队 - Shuai Guangying
本篇文章介绍了统计计数的基本原理以及Presto的实现思路,精确统计和近似统计的细节及各种优缺点,并给出了统计计数在具体业务使用的建议。
系列文章:
一、背景
学习Hadoop时接触的第一个样例就是word count,即统计文本中词的数量。各种BI、营销产品中不可或缺的模块就是统计报表。在常见的搜索分页模块,也需要提供总记录数。
统计在SQL引擎中可谓最基础、最核心的能力之一。可能由于它太基础了,就像排序一样,我们常常会忽视它背后的原理。通常的计数是非常简单的,例如统计文本行数在linux系统上一个wc命令就搞定了。
除了通常的计数,统计不重复元素个数的需求也非常常见,这种统计称为基数统计。对于Presto这种分布式SQL引擎,计数的实现原理值得深入研究,特别是基数统计。关于普通计数和基数计数,最典型的例子莫过于PV/UV。
二、基数统计主要算法
在SQL语法里面,基数统计对应到count(distinct field)或者aprox_distinct()。通常做精确计数统计需要用到Set这种数据结构。通过Set不仅可以获得数量信息,还能不重不漏地获取每一个元素。
Set内部有两种实现实现原理:Hash和Tree。
在海量数据的前提下,Hash和Tree有一个致命的问题:内存消耗,而且随着数据量级的增长,内存消耗也是线性增长。
面对Set内存消耗的问题,通常有两种思路:
一种是选取其他内存占用更小的数据结构,例如bitmap;
另一种是放弃精确,从数学上寻求近似解,典型的算法有Linear Count和HyperLogLog。
2.1 Bitmap
在数据库领域Bitmap并不是新事物,一般用作索引,称为位图索引。所谓位图索引,就是用一个bit位向量来记录某个字段值是否存在于对应的记录。它有一个前置条件:记录要有永久的编号,类似于从1开始的自增主键。
2.1.1 位图向量的构建
举个例子,假设表user记录如下:
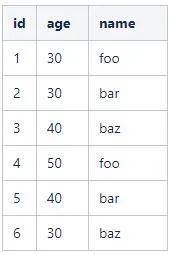
这是很典型的一张数据库表。对于表中的字段,如何构建位图索引呢?以age字段为例:
S1: 确定字段的取值集合空间: {30,40,50} 一共3个选项。
S2: 依次为每个选项构建一个长度为6的bit向量,得到一个3*6的位图。3表示字段age的取值基数,6表示记录数。
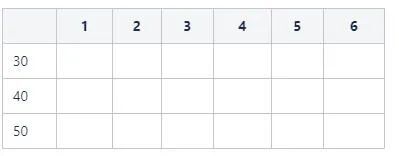
S3: 基于表设置位图相应向量值。例如:age=30的记录id分别为{1,2,6},那么在向量1,2,6位置置为1,其他置为0。得到110001。
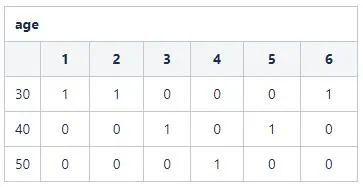
同理,对于name字段,其向量位图为:
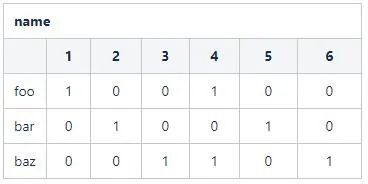
可以看出,如果对于数据表的一个字段,如果记录数为n且字段的取值基数为m,那么会得到一个m*n的位图。
2.1.2 位图向量的应用
有了位图向量,该如何使用呢?假设查询SQL为
select count(1) from user where age=40;
则取age字段位图中age=40的向量:110001。统计其中1的个数,即可得到最终结果。
假设查询SQL更复杂一些:
select count(1) from user where age=40 and name='baz'
则取age字段位图中age=40的向量:110001和name='foo'的向量:100100。两个向量进行交集运算:
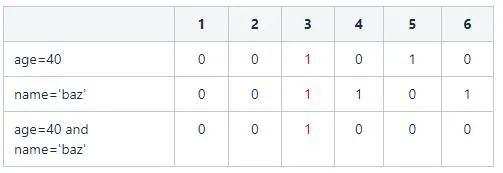
最后统计结果为1。
关于Bitmap的思想,笔者认为最巧妙的一点就是通过位运算实现了集合运算。如下图所示:
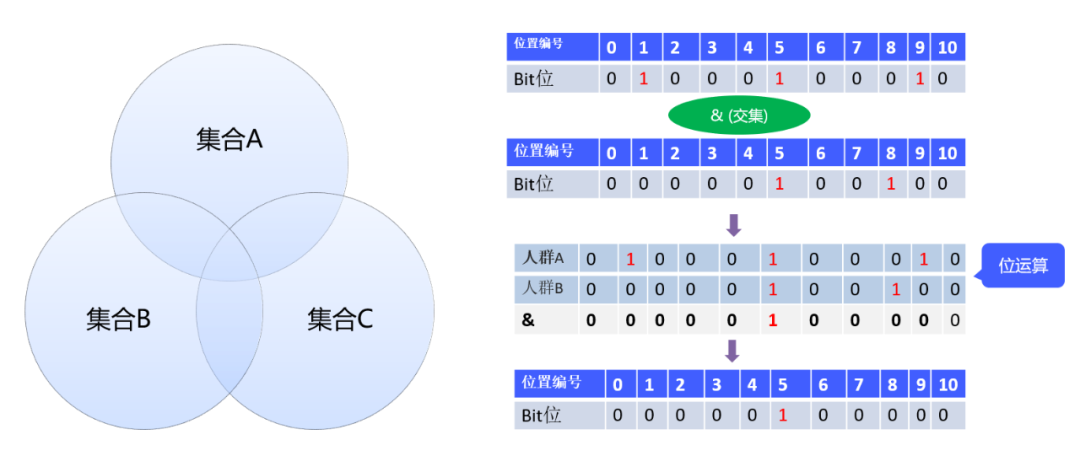
在不同的业务场景中,这里的集合可以赋予不同的业务含义。
2.1.3 位图向量的优点
将字段的筛选变成了向量计算后,会非常节约内存,而且可以通过分段长度编码等方式对bitmap向量进行压缩。而且位运算直接对内存中的二进制位进行操作,执行效率非常高,是性能提升的一大杀器。
理解了bitmap后,可以发现对于整型字段,可以直接用bitmap进行基数统计。笔者曾经实验过,对于3亿数据量级使用roaringbitmap工具,bitmap消耗内存约30M,而且如果数据分布非常密集内存消耗还有很大的压缩空间。唯一的缺点是非数值型字段,需要进行额外的转换处理。
2.2 Linear Count算法
Linear Count简称LC算法,LC算法的流程非常简单(背后的数学思想不简单)。
算法描述如下:
初始化:给定m个房间,房间存储数字,初始化为0。
迭代执行:对于要进行基数统计的集合,用一个哈希函数处理集合中的每一个元素。通过哈希函数处理后,元素就可以放置到一个房间中。
收尾:统计m个房间中空房间的数量U。
结论:集合中不重复元素的个数估计值可以通过如下公式计算:n=-m*log(U/m)。
这样就把一个统计问题转换成了一个数学问题。公式非常简洁,看到这里大脑中一定会出现许多的问题:
这个公式是怎么得到的?
这里涉及到概率论与数理统计知识,简单来说就是分布、期望、方差、最大似然估计。数学相关的知识比较初级,陈希孺的《概率论与数理统计》基本能覆盖这个公式的数学原理。
这个算法的精确度怎么样?
这个问题从数学的角度,就是问方差(标准差)。这里没法给一个具体的值,跟满桶率控制, m的选择有关。
这个算法相比精确计数很省空间吗?
这个毋庸置疑,不然直接精确统计就可以了。
m和最终结果n需要满足什么关系?
(毕竟当没有空房间时,这个公式就有问题了。) 这里直接给结论吧,随着m和n的增大,m大约为n的十分之一。
2.3 HyperLogLog算法
HyperLogLog简称HLL算法,它有如下的特点:
可以实现由极小的内存开销统计出巨量的数据。在 Redis中实现的HyperLogLog,只需要12K内存就能统计2^64个数据。
可以方便实现分布式扩展。(这个点对算法在业务系统中落地非常关键)
理解HLL算法,需要如下几个知识点的铺垫:伯努利实验、调和平均数。
伯努利实验有很多的呈现方式,本文例举其中的一种: 取一枚硬币,不断抛掷,直到硬币落地结果为正面朝上。这样的执行过程称为一轮实验。从描述可以看出一轮实验完成抛掷硬币的次数是随机的。
一轮实验对应的Java代码实现如下:
private Random random = new Random(); /**
* 0代表正面
* 1代表反面
* 抛掷直到出现正面
* @return 抛掷的次数
*/
public int tossCoin(){
int r,cnt=0;
do{
r=random.nextInt(2);
cnt++;
}while (r<1);
return cnt;
}
可以看出,每执行一轮实验就会得到一个数字,代表这轮实验抛掷硬币的次数。例如:
执行了10轮,可能的结果如下:
3,1,4,1,1,2,3,4,1,1
执行了100轮,可能的结果如下:
1,1,2,1,1,2,1,4,2,1,3,1,1,1,1,3,1,2,1,1,2,4,2,3,2,1,1,1,3,1,2,2,6,1,2,4,1,2,2,1,1,3,1,1,1,1,1,1,1,1,1,4,2,1,1,1,1,1,3,1,2,4,4,4,1,3,2,1,5,1,1,1,1,1,1,1,5,1,1,7,1,1,4,1,3,2,1,1,5,2,1,1,5,2,1,1,4,1,1,1
执行了1000轮,可能的结果如下:
1,2,1,2,1,3,3,3,1,1,2,2,1,2,1,1,1,1,1,2,1,7,1,1,1,2,2,1,1,3,5,2,3,2,3,1,1,3,1, ...,4,1,1,1,2,2,1,3,1,1,1,2,1,1,1,2,1,4,2,2,1,2,2,2,1,1,1,2,2,2,1,1,1,2,2,1,1,3,2,6,1,1,1,2,1,1,1,1,1,1,1,2,1,1,1,1,2,1
这时候问题就来了,我们这样按上面的规则不停的抛硬币只是为了应付无聊的时间吗?当然不是!我们关注的重点是:
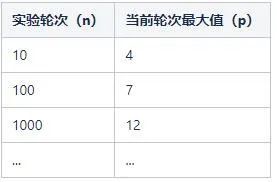
当然,这个最大值是随机变动的,它不是一个固定的值。但是隐约中有个规律:执行的轮次越多,轮次对应的最大值也越大。数学上可以给一个很粗略的公式来拟合这种关系:n=2^p。
换言之,我们可以通过p来估计n。到这里就出现了问题解决思路的转换:
将基数统计问题转换成概率论里面参数估计的问题。
思维转换到了数学领域,就可以用数学的工具来解决问题。通常用概率论的思维解决问题,会面临如下几个拦路虎。
问题一:最大值不稳定,容易受到极值影响。
在概率上,对于极值我们的处理策略是多实验几轮,通过平均值来消除极值的影响。这个就引出了第二基础知识点:调和平均数。
数学上其实有许多的平均数计算方式:算术平均数、几何平均数、平方平均数。这里选用调和平均数主要是消除极值的影响。通常有个笑话说,我的收入是1万,老板的收入是1亿,我们平均收入是5000万,我被平均了。如果用调和平均数,得到的结果就是1999.98。
关于调和平均数的公式,非常容易理解:

关于数学,确切地说是概率论的知识点,还有很多。例如估计方法是有偏估计还是无偏估计?,估计的方差和标准差是多大?这里涉及到较为底层的概率论知识,就先略过。
略过数学知识,关键的问题在于,我们如何将待基数统计问题跟上面的伯努利实验建立联系?这两个点之间的桥梁就是Hash函数。第一次见识到Hash函数还能这样用,确实大开眼界。
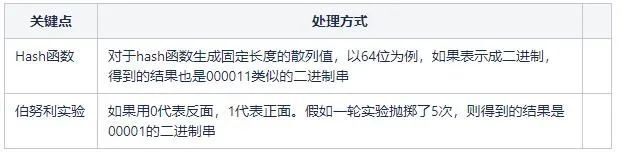
对于相同的数,通过hash函数生成的散列值是相同的,这就进行了排重。当然不排除不同的数据生成同样的hash值,形成冲突。由于选取的hash函数例如MurmurHash3冲突率低,可以忽略这个因素。
实际上,由于Hash函数生成的二进制串通常具备均匀的特性,所以Hash函数生成的二进制串可以视为抛掷硬币的结果。
对于一个待进行基数统计的集合(例如一个表中符合条件的字段值),为了降低估计的错误率,我们分成m组。某个值归属于哪个组由hash函数生成结果对应的前几位决定,剩下的二进制串用于计算当前轮伯努利实验第一次出现正面时抛掷的次数,记为p。
所以算法描述如下:

简单来说就是统计每个组最大的p, 然后用现成的公式计算结果即到达预估的结果。
三、分布式计数核心流程
对于Hadoop中的入门案例wordcount,可以发现如果用Presto SQL表达如下(以tpch数据集customer表name字段为例):
select w, count(1) cnt from (
select split(name,'#') words from customer
) t1 cross join UNNEST(t1.words) AS t (w)
group by w;
可以看出相比大段的代码,SQL处理对用于来说要简单的多。无论是哪种表达方式,核心点就是分组统计。
在MapReduce框架核心流程如下:
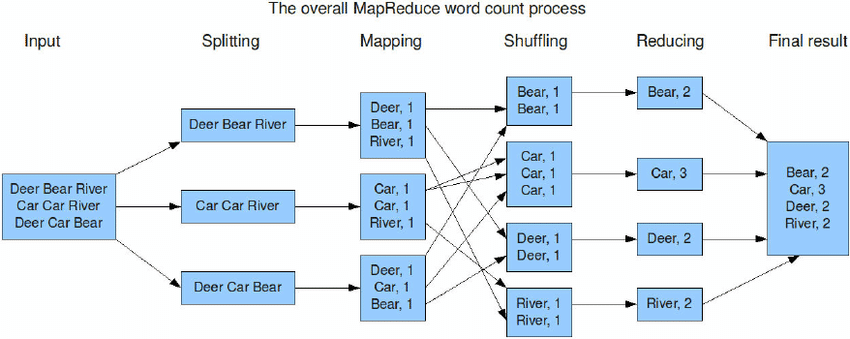
那么在Presto, 其执行流程是什么样呢?
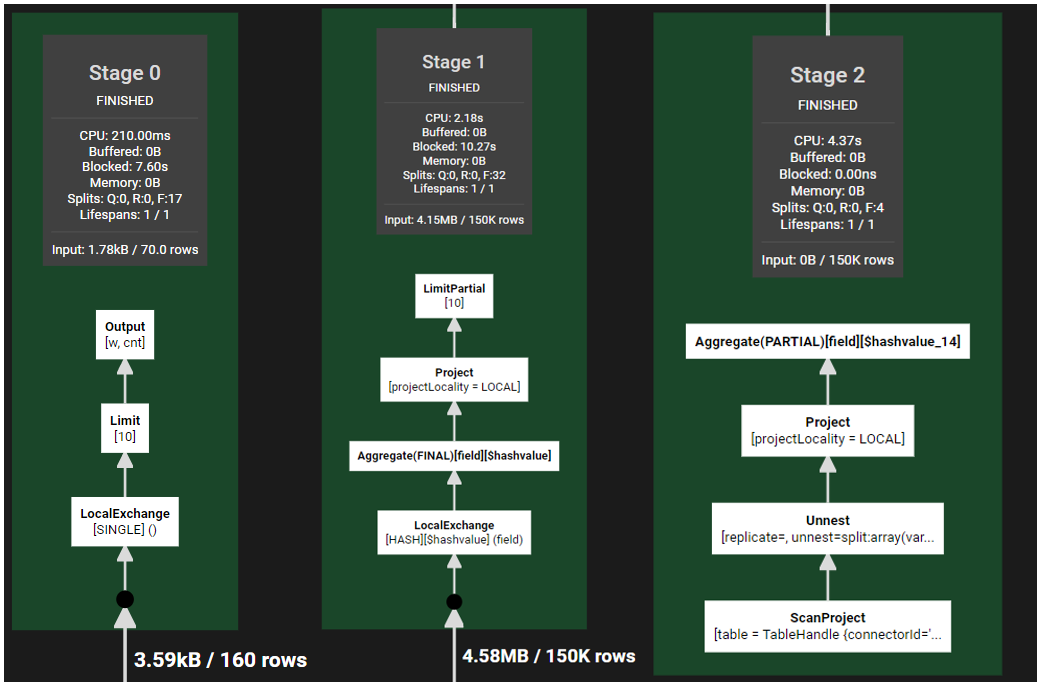
从逻辑上,都是类似的。先分组聚合,然后汇总聚合。
四、基数统计在Presto中的落地
对于基数统计问题Presto支持两种实现方式。一种是追求精确的count distinct; 另一种是提供近似统计的approx_distinct。
count distinct的核心细节
以SQL :select count(distinct id) from hive_table 为例。
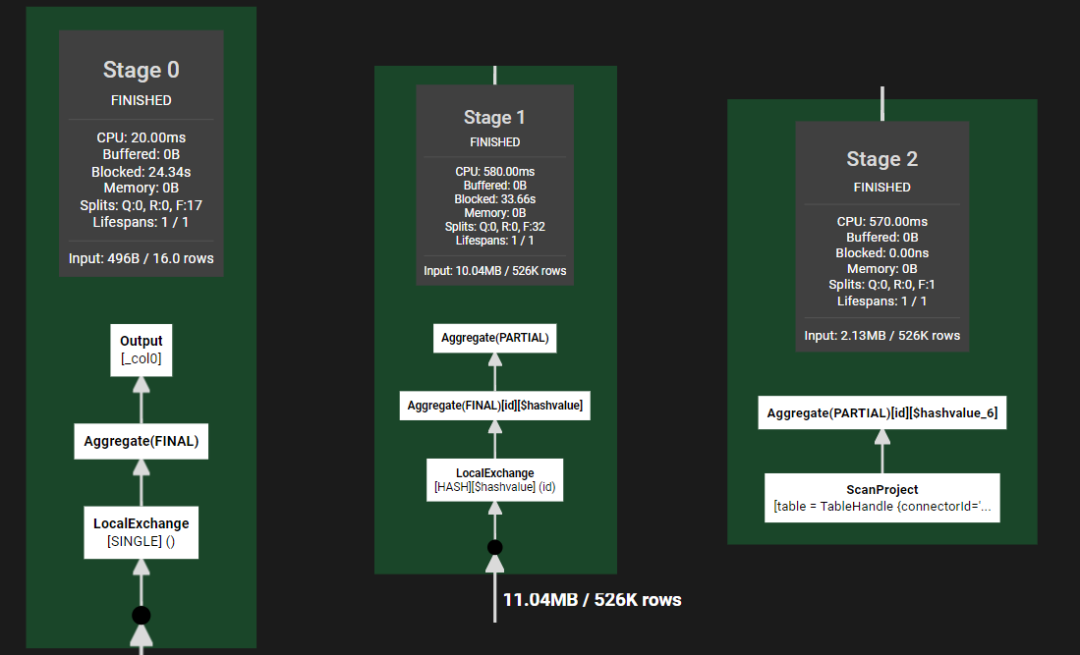
即以id为主key, 对数据进行hash分发,进行部分聚合,最终整体聚合。依然是map-reduce的思路,只不过数据按id进行了分发。
aprox_distinct的核心细节
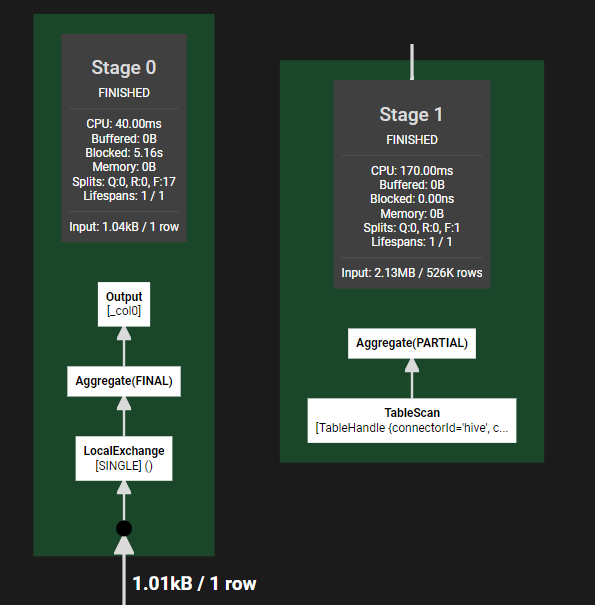
这里就免去了基于id的hash分发策略。所以也减少了一个stage。至于approx_distinct的内部细节,基础框架airlift中,封装了HyperLogLog算法的实现,采用的函数是MurMurHash3算法,生成64位散列值。前6位用于计算当前散列值所在分组m。实现过程中还有一个很有意思的细节:基于待统计的数据量,实现中同时采用了Linear Count算法和HyperLogLog算法。
五、业务建议
通过上面的分析,我们可以发现高基数统计是一个非常消耗内存的操作,特别是在分布式系统背景下,不仅消耗内存,而且涉及大量网络数据传输。如果分析对应的业务场景,可以提供近似值而非精确值,那么就能大幅度降低系统消耗和响应时间,提升用户体验。或者在设计产品的时候,对于一些场景的计数,可以优先提供近似估计,如果用户确实需要精确计数,那么在管理好用户响应时间预期下,再提供查询精确值的接口。
理解了精确统计和近似统计的细节及各种优缺点,处理问题的思路就会更开阔。例如:在设计存储索引时,我们可以优先使用HyperLogLog统计一个字段的基数近似值,如果得到的结果不是高基数,那么我们可以对字段构建bitmap索引,借此提升数据处理的效率。
在《我们如何走到今天:重塑世界的6项创新 》一书中有这样一个观点让人记忆深刻:我们衡量越精确,控制的能力就越强。但是它没有说的是,衡量越精确,成本就越大。
参考:
《数据库系统实现》
A Linear-Time Probabilistic Counting Algorithm for Database Applications
HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm
探究Presto SQL引擎(4)-统计计数的更多相关文章
- 探究Presto SQL引擎(3)-代码生成
vivo 互联网服务器团队- Shuai Guangying 探究Presto SQL引擎 系列:第1篇<探究Presto SQL引擎(1)-巧用Antlr>介绍了Antlr的基本用法 ...
- 探究Presto SQL引擎(1)-巧用Antlr
一.背景 自2014年大数据首次写入政府工作报告,大数据已经发展7年.大数据的类型也从交易数据延伸到交互数据与传感数据.数据规模也到达了PB级别. 大数据的规模大到对数据的获取.存储.管理.分析超出了 ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- facebook Presto SQL分析引擎——本质上和spark无异,分解stage,task,MR计算
Presto 是由 Facebook 开源的大数据分布式 SQL 查询引擎,适用于交互式分析查询,可支持众多的数据源,包括 HDFS,RDBMS,KAFKA 等,而且提供了非常友好的接口开发数据源连接 ...
- 六大主流开源SQL引擎
导读 本文涵盖了6个开源领导者:Hive.Impala.Spark SQL.Drill.HAWQ 以及Presto,还加上Calcite.Kylin.Phoenix.Tajo 和Trafodion.以 ...
- 六大主流开源SQL引擎总结
本文涵盖了6个开源领导者:Hive.Impala.Spark SQL.Drill.HAWQ 以及Presto,还加上Calcite.Kylin.Phoenix.Tajo 和Trafodion.以及2个 ...
- 大数据时代快速SQL引擎-Impala
背景 随着大数据时代的到来,Hadoop在过去几年以接近统治性的方式包揽的ETL和数据分析查询的工作,大家也无意间的想往大数据方向靠拢,即使每天数据也就几十.几百M也要放到Hadoop上作分析,只会适 ...
- 转:大数据时代快速SQL引擎-Impala
本文来自:http://blog.csdn.net/yu616568/article/details/52431835 如有侵权 可立即删除 背景 随着大数据时代的到来,Hadoop在过去几年以接近统 ...
- 6大主流开源SQL引擎总结,遥遥领先的是谁?
根据 O’Reilly 2016年数据科学薪资调查显示,SQL 是数据科学领域使用最广泛的语言.大部分项目都需要一些SQL 操作,甚至有一些只需要SQL.本文就带你来了解这些主流的开源SQL引擎!背景 ...
随机推荐
- navicat创建连接 2002-can‘t connect to server on ....
环境: 系统:centos7 生产环境:docker 中部署MySQL 报错提示符:"2002-Can't connect to server on '192.168.200.22'(100 ...
- Redis安装及常用配置
Redis安装说明 大多数企业都是基于Linux服务器来部署项目,而且Redis官方也没有提供Windows版本的安装包.因此课程中我们会基于Linux系统来安装Redis. 此处选择的Linux版本 ...
- 10种有用的Linux Bash_Completion 命令示例
摘要:我们可以对这个 bash 补全进行加速,并使用 complete 命令将其提升到一个新的水平. 本文分享自华为云社区<有用的 Linux Bash_Completion 命令示例(Ster ...
- ASP.NET Core 6框架揭秘实例演示[33]:异常处理高阶用法
NuGet包"Microsoft.AspNetCore.Diagnostics"中提供了几个与异常处理相关的中间件,我们可以利用它们将原生的或者定制的错误信息作为响应内容发送给客户 ...
- P4767 [IOI2000]邮局 - 平行四边形不等式优化DP
There is a straight highway with villages alongside the highway. The highway is represented as an in ...
- 【Git进阶】基于文件(夹)拆分大PR
背景 前段时间为了迁移一个旧服务到新项目,由此产生了一个巨大的PR,为了方便Code Review,最终基于文件夹,将其拆分成了多个较小的PR:现在这里记录下,后面可能还会需要. 演示 为了方便演示, ...
- flutter系列之:flutter中常用的GridView layout详解
目录 简介 GridView详解 GridView的构造函数 GridView的使用 总结 简介 GridView是一个网格化的布局,如果在填充的过程中子组件超出了展示的范围的时候,那么GridVie ...
- JS数据结构之 Map
JS数据结构之 Map Map介绍 Map(映射)是ES6引入的一种数据结构.这是一种存储键值对列表很方便的方法,类似于其他编程语言的哈希表. HashMap(哈希表),也叫做散列表.是根据关键码值 ...
- 6、Arrays类
Arrays类 Arrays里面包含了一系列静态方法,用于管理或操作数组(比如排序和搜索) 常用方法 toString 返回数组的字符串形式 Arrays.toString(arr) Integer[ ...
- es,logstash各版本对应要求的JDK版本,操作系统对应示意图
官网地址:https://www.elastic.co/cn/support/matrix