【算法】—— LRU算法
LRU原理
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
实现1
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下: 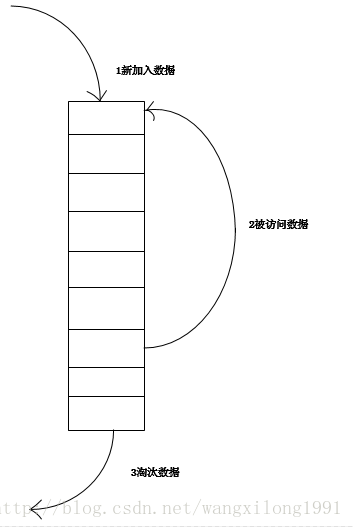
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
分析
【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】
实现简单。
【代价】
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
import java.util.ArrayList;
import java.util.Collection;
import java.util.LinkedHashMap;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.Map; /**
* 类说明:利用LinkedHashMap实现简单的缓存, 必须实现removeEldestEntry方法,具体参见JDK文档
*
* @author dennis
*
* @param <K>
* @param <V>
*/
public class LRULinkedHashMap<K, V> extends LinkedHashMap<K, V> {
private final int maxCapacity; private static final float DEFAULT_LOAD_FACTOR = 0.75f; private final Lock lock = new ReentrantLock(); public LRULinkedHashMap(int maxCapacity) {
super(maxCapacity, DEFAULT_LOAD_FACTOR, true);
this.maxCapacity = maxCapacity;
} @Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
return size() > maxCapacity;
}
@Override
public boolean containsKey(Object key) {
try {
lock.lock();
return super.containsKey(key);
} finally {
lock.unlock();
}
} @Override
public V get(Object key) {
try {
lock.lock();
return super.get(key);
} finally {
lock.unlock();
}
} @Override
public V put(K key, V value) {
try {
lock.lock();
return super.put(key, value);
} finally {
lock.unlock();
}
} public int size() {
try {
lock.lock();
return super.size();
} finally {
lock.unlock();
}
} public void clear() {
try {
lock.lock();
super.clear();
} finally {
lock.unlock();
}
} public Collection<Map.Entry<K, V>> getAll() {
try {
lock.lock();
return new ArrayList<Map.Entry<K, V>>(super.entrySet());
} finally {
lock.unlock();
}
}
}
实现2
LRUCache的链表+HashMap实现
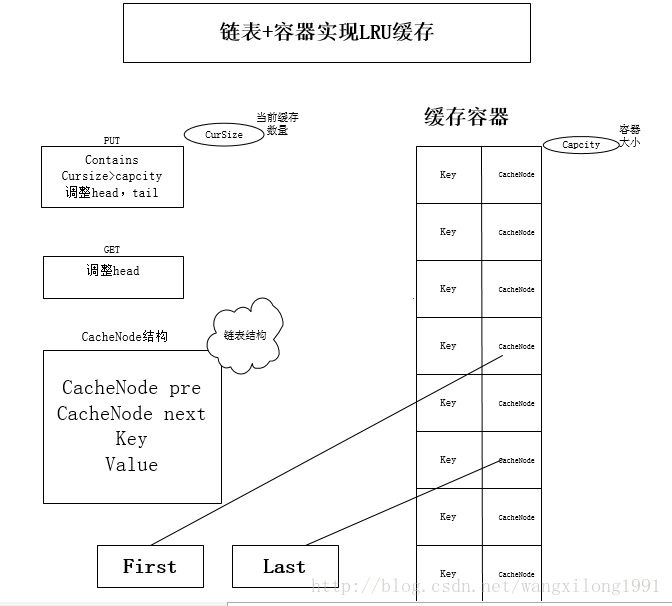
传统意义的LRU算法是为每一个Cache对象设置一个计数器,每次Cache命中则给计数器+1,而Cache用完,需要淘汰旧内容,放置新内容时,就查看所有的计数器,并将最少使用的内容替换掉。
它的弊端很明显,如果Cache的数量少,问题不会很大, 但是如果Cache的空间过大,达到10W或者100W以上,一旦需要淘汰,则需要遍历所有计算器,其性能与资源消耗是巨大的。效率也就非常的慢了。
它的原理: 将Cache的所有位置都用双连表连接起来,当一个位置被命中之后,就将通过调整链表的指向,将该位置调整到链表头的位置,新加入的Cache直接加到链表头中。
这样,在多次进行Cache操作后,最近被命中的,就会被向链表头方向移动,而没有命中的,而想链表后面移动,链表尾则表示最近最少使用的Cache。
当需要替换内容时候,链表的最后位置就是最少被命中的位置,我们只需要淘汰链表最后的部分即可。
上面说了这么多的理论, 下面用代码来实现一个LRU策略的缓存。
非线程安全,若实现安全,则在响应的方法加锁。
import java.util.HashMap;
import java.util.Map.Entry;
import java.util.Set; public class LRUCache<K, V> { private int currentCacheSize;
private int CacheCapcity;
private HashMap<K,CacheNode> caches;
private CacheNode first;
private CacheNode last; public LRUCache(int size){
currentCacheSize = 0;
this.CacheCapcity = size;
caches = new HashMap<K,CacheNode>(size);
} public void put(K k,V v){
CacheNode node = caches.get(k);
if(node == null){
if(caches.size() >= CacheCapcity){ caches.remove(last.key);
removeLast();
}
node = new CacheNode();
node.key = k;
}
node.value = v;
moveToFirst(node);
caches.put(k, node);
} public Object get(K k){
CacheNode node = caches.get(k);
if(node == null){
return null;
}
moveToFirst(node);
return node.value;
} public Object remove(K k){
CacheNode node = caches.get(k);
if(node != null){
if(node.pre != null){
node.pre.next=node.next;
}
if(node.next != null){
node.next.pre=node.pre;
}
if(node == first){
first = node.next;
}
if(node == last){
last = node.pre;
}
} return caches.remove(k);
} public void clear(){
first = null;
last = null;
caches.clear();
} private void moveToFirst(CacheNode node){
if(first == node){
return;
}
if(node.next != null){
node.next.pre = node.pre;
}
if(node.pre != null){
node.pre.next = node.next;
}
if(node == last){
last= last.pre;
}
if(first == null || last == null){
first = last = node;
return;
} node.next=first;
first.pre = node;
first = node;
first.pre=null; } private void removeLast(){
if(last != null){
last = last.pre;
if(last == null){
first = null;
}else{
last.next = null;
}
}
}
@Override
public String toString(){
StringBuilder sb = new StringBuilder();
CacheNode node = first;
while(node != null){
sb.append(String.format("%s:%s ", node.key,node.value));
node = node.next;
} return sb.toString();
} class CacheNode{
CacheNode pre;
CacheNode next;
Object key;
Object value;
public CacheNode(){ }
} public static void main(String[] args) { LRUCache<Integer,String> lru = new LRUCache<Integer,String>(3); lru.put(1, "a"); // 1:a
System.out.println(lru.toString());
lru.put(2, "b"); // 2:b 1:a
System.out.println(lru.toString());
lru.put(3, "c"); // 3:c 2:b 1:a
System.out.println(lru.toString());
lru.put(4, "d"); // 4:d 3:c 2:b
System.out.println(lru.toString());
lru.put(1, "aa"); // 1:aa 4:d 3:c
System.out.println(lru.toString());
lru.put(2, "bb"); // 2:bb 1:aa 4:d
System.out.println(lru.toString());
lru.put(5, "e"); // 5:e 2:bb 1:aa
System.out.println(lru.toString());
lru.get(1); // 1:aa 5:e 2:bb
System.out.println(lru.toString());
lru.remove(11); // 1:aa 5:e 2:bb
System.out.println(lru.toString());
lru.remove(1); //5:e 2:bb
System.out.println(lru.toString());
lru.put(1, "aaa"); //1:aaa 5:e 2:bb
System.out.println(lru.toString());
} }
【算法】—— LRU算法的更多相关文章
- 缓存淘汰算法--LRU算法
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是"如果数据最近被访问过,那么将来被访问的几率也 ...
- 近期最久未使用页面淘汰算法———LRU算法(java实现)
请珍惜小编劳动成果,该文章为小编原创,转载请注明出处. LRU算法,即Last Recently Used ---选择最后一次訪问时间距离当前时间最长的一页并淘汰之--即淘汰最长时间没有使用的页 依照 ...
- 最近最久未使用页面淘汰算法———LRU算法(java实现)
请珍惜小编劳动成果,该文章为小编原创,转载请注明出处. LRU算法,即Last Recently Used ---选择最后一次访问时间距离当前时间最长的一页并淘汰之--即淘汰最长时间没有使用的页 按照 ...
- 使用java.util.LinkedList模拟实现内存页面置换算法--LRU算法
一,LRU算法介绍 LRU是内存分配中“离散分配方式”之分页存储管理方式中用到的一个算法.每个进程都有自己的页表,进程只将自己的一部分页面加载到内存的物理块中,当进程在运行过程中,发现某页面不在物理内 ...
- 缓存淘汰算法--LRU算法(转)
(转自:http://flychao88.iteye.com/blog/1977653) 1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访 ...
- 《算法 - Lru算法》
一:概述 - LRU 用于管理缓存策略,其本身在 Linux/Redis/Mysql 中均有实现.只是实现方式不尽相同. - LRU 算法[Least recently used(最近最少使用)] - ...
- 【算法】LRU算法
缓存一般存放的都是热点数据,而热点数据又是利用LRU(最近最久未用算法)对不断访问的数据筛选淘汰出来的. 出于对这个算法的好奇就查了下资料. LRU算法四种实现方式介绍 缓存淘汰算法 利用Linked ...
- Redis的LRU算法
Redis的LRU算法 LRU算法背后的的思想在计算机科学中无处不在,它与程序的"局部性原理"很相似.在生产环境中,虽然有Redis内存使用告警,但是了解一下Redis的缓存使用策 ...
- Android图片缓存之Lru算法
前言: 上篇我们总结了Bitmap的处理,同时对比了各种处理的效率以及对内存占用大小.我们得知一个应用如果使用大量图片就会导致OOM(out of memory),那该如何处理才能近可能的降低oom发 ...
- 操作系统 页面置换算法LRU和FIFO
LRU(Least Recently Used)最少使用页面置换算法,顾名思义,就是替换掉最少使用的页面. FIFO(first in first out,先进先出)页面置换算法,这是的最早出现的置换 ...
随机推荐
- Yii2基本概念之——配置(Configurations)
在Yii中创建新对象或者初始化已经存在的对象广泛的使用配置,配置通常包含被创建对象的类名和一组将要赋值给对象的属性的初始值,这里的属性是Yii2的属性.还可以在对象的事件上绑定事件处理器,或者将行为附 ...
- js中数组的map()方法
map()方法返回一个新数组,数组中的元素为原始数组元素调用函数处理后的值 map()方法按照原是数组顺序以此处理元素 注意:map()不会对空数组进行检测 :不会改变原始的数组 实例: var nu ...
- Python全栈之路(目录) - 含资料(持续更新)
一. Python全栈之路 - 目录 Python基础 Python进阶 网络编程 并发编程 前端 数据库 Python Web框架之Django 前端框架之Vue Linux Flask+智能玩具 ...
- json 按照字段分类
let arr = [ { Category:'A', Amount:, },{ Category:'B', Amount:, },{ Category:'A', Amount:, },{ Categ ...
- HTML和CSS前端教程03-CSS选择器
目录 1. CSS定义 2. 创建CSS的三种方法 2.1. 元素内嵌(权重最高) 2.2. 文档内嵌 2.3. 外部引用 3. CSS层叠和继承 3.1. 浏览器样式 3.2. 样式表层叠 3.3. ...
- arcgis api 3.x for js 入门开发系列二不同地图服务展示(附源码下载)
前言 关于本篇功能实现用到的 api 涉及类看不懂的,请参照 esri 官网的 arcgis api 3.x for js:esri 官网 api,里面详细的介绍 arcgis api 3.x 各个类 ...
- ARouter学习随笔
今天看了会ARouter,在这里简单记录下 跟着其他大哥的博客学习了下,总感觉不牢固,借此机会再次简单记录下. 第一步:ARouter 配置 android { defaultConfig { ... ...
- 测者的性能测试手册:JVM的监控利器
测者的性能测试手册:JVM的监控利器 每次聊起性能测试,最后的终结话题就是怎么做优化.其实在Java的复杂项目中都会有内存不足问题.内存泄露问题.线程死锁问题.CPU问题.这些问题工程测试或者是小压力 ...
- WPF开源项目
WPF有很多优秀的开源项目,我以为大家都知道,结果,问了很多人,其实他们不知道.唉,太可惜了! 先介绍两个比较牛逼的界面库 1.MaterialDesignInXamlToolkit Android风 ...
- SQL server 远程连接不成功解决
一直以来打算自己做一个博客网站,前段时间开始准备做了,正好碰上新睿云服务器免费一年的活动,赶紧拿下.装好了sqlserver ,用本地访问没有问题,但是关键是外网访问一直不行找了好多资料最终才搞定.下 ...