Scrapy详解
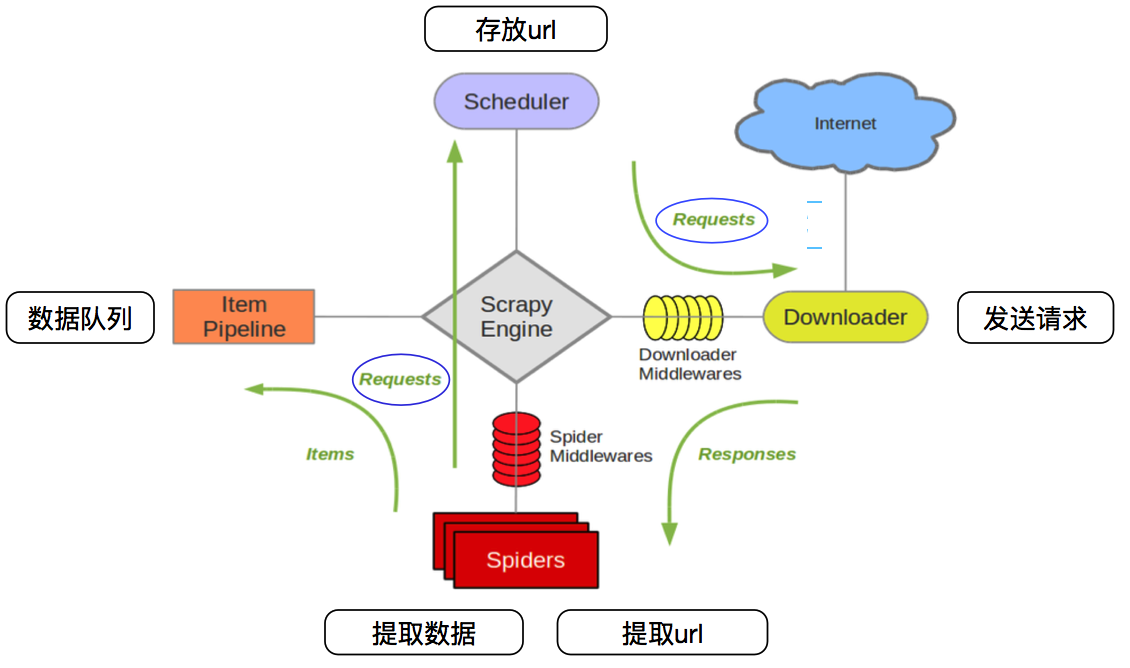
一、爬虫生态框架
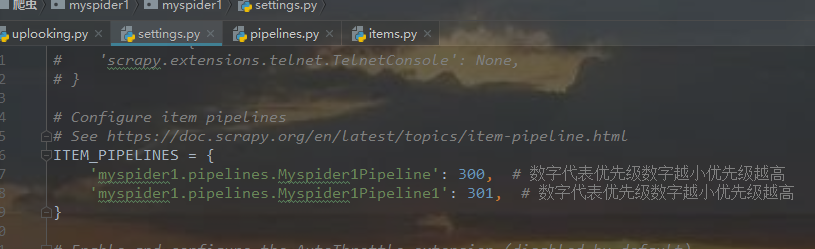
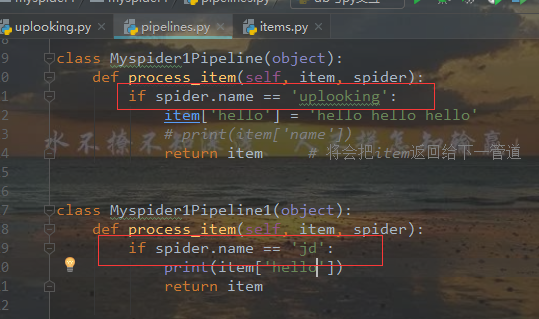
在管道传数据只能传字典和items类型。

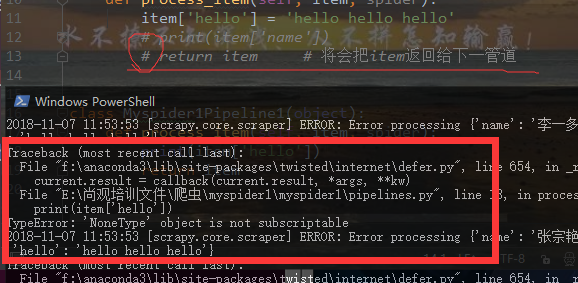
将 上一return语句注释则会报错 如:

如上图,爬虫文件中有一个name属性,如果多个爬虫可以通过这个属性在管道控制分析的是哪个爬虫的数据
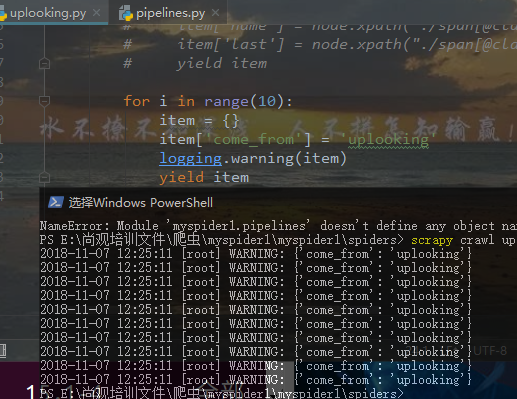
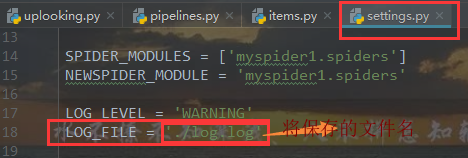
日志文件

添加红框里面的一条代码,让打印结果只显示warning级别及以上的警告
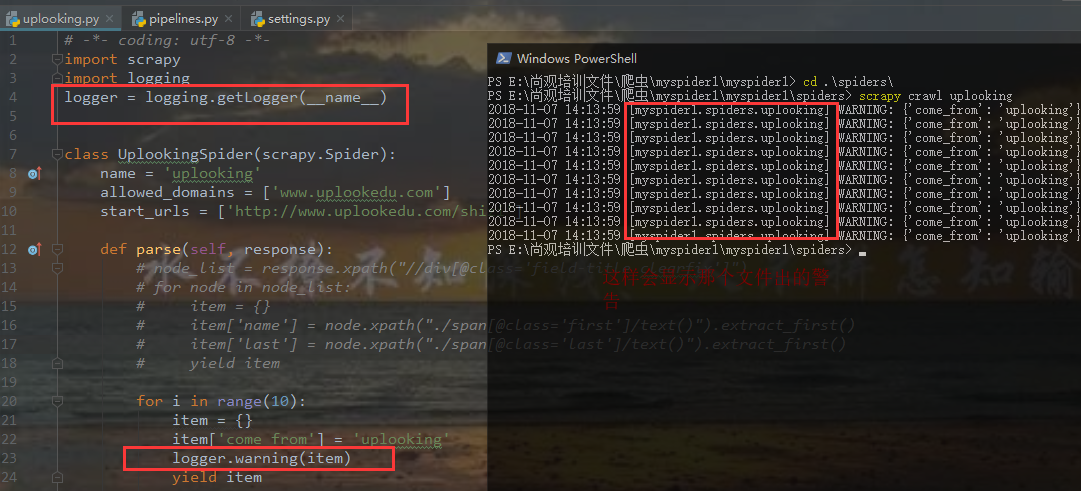
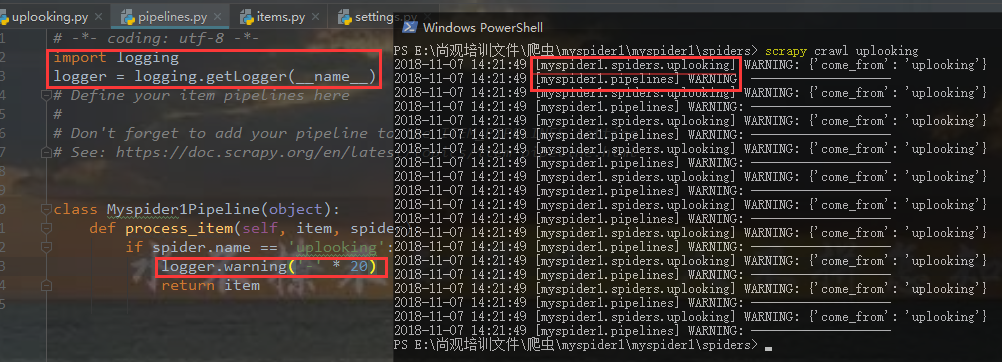
如何保存日志信息
发现运行后没有任何输出

项目中多了log.log日志文件
打开log.log日志文件即日志信息

items类型对象
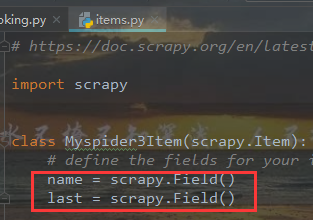
在items文件中声明了name、last的键在爬虫文件中声明即可用

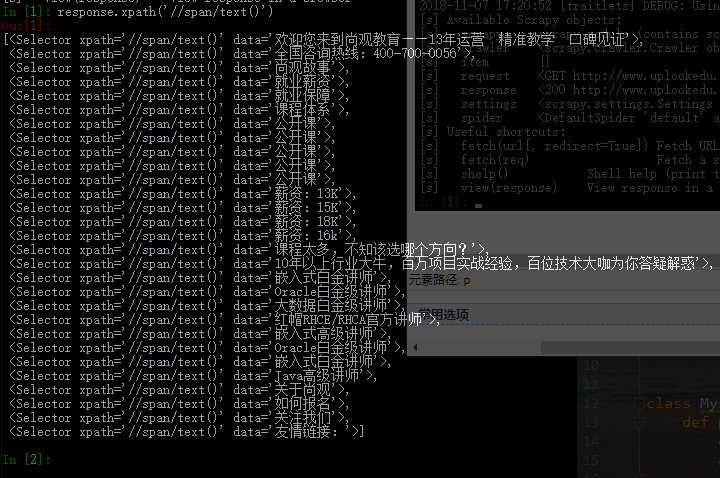
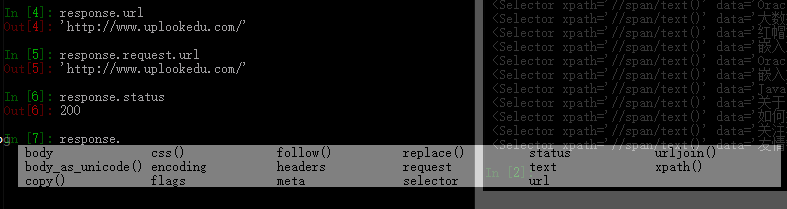
scrapy shell 用法
scrapy shell + 网址 会进入一个ipython可以测试response 如:

模仿浏览器
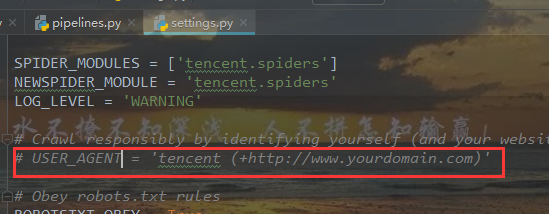
改为自己浏览器的user_agent信息

更改遵守robots规则
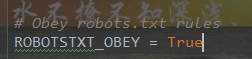
将True改为False
提取下一页url: scrapy.Request(url, callback)用来获取网页里的地址
callback:指定由那个函数去处理
分布式爬虫:
1.多台机器爬到的数据不能重复
2.多台机器爬到的数据不能丢失
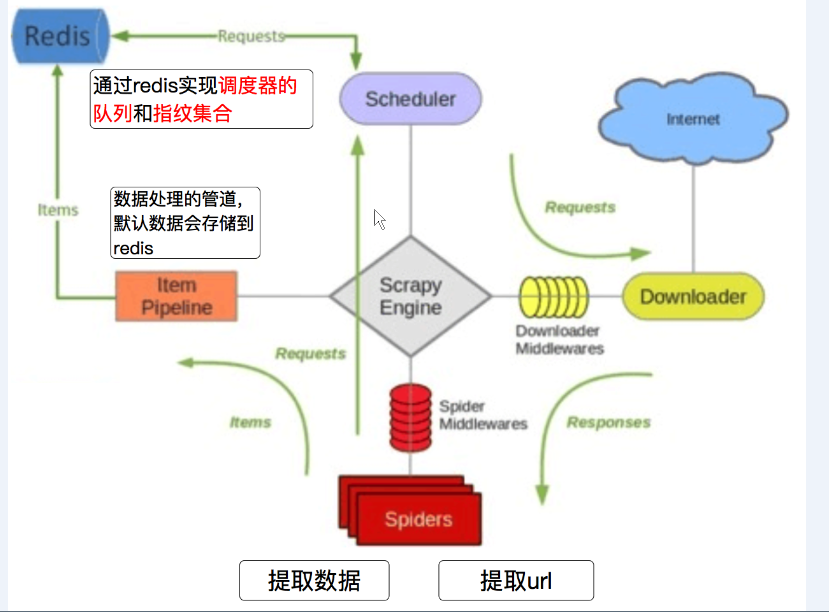
1.redis是什么?
Redis是一个开源的、内存数据库,他可以用作数据库、缓存、消息中间件。它支持多种数据类型的数据结构,如字符串、哈希、列表、集合、有序集合(可能存在数据丢失)
redis安装 Ubuntu: sudo apt-get install redis-server Centos:sudo yum install redis-server
检测redis状态
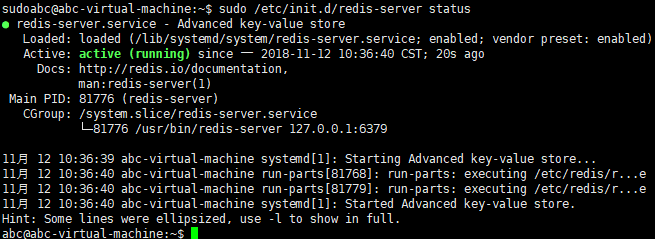
redis服务的开启:sudo /etc/init.d/redis-server start
重启:sudo /etc/init.d/redis-server restart
关闭:sudo /etc/init.d/redis-server stop
redis连接客户端:redis-cli
redis远程连接客户端:redis-cli -h<hostname> -p <port>(默认6379)
redis常用命令:
选择数据库:select 1 (第一个数据库为0 ,默认16个数据库,可修改配置文件修改数据库个数且个数没有上限)

查看数据库里的内容:keys *
向数据库加列表:lpush mylist a b c d (数据可重复)
查看列表数据:lrange mylist 0 -1

查看列表元素个数:llen mylist
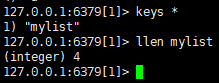
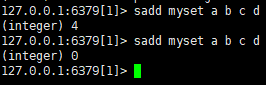
向set中加数据:sadd myset a b c d(不能重复,无序)
查看set中的数据:smembers myset

查看set中的元素个数:scard myset

向有序zset中添加数据:zadd myzset 1 a 2 b 3 c 4 d

查看zset编号和数据:zrange myzset 0 -1 withscores
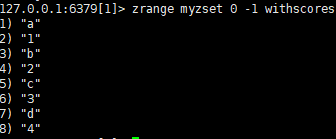
查看zset数据
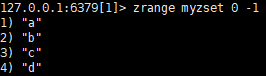
改变编号 如改变a的编号:

统计zset元素的个数zcard myzset

删除当前数据库:flushdb
清楚所有数据库:flushall
安装scrapy-redis
sudo pip install scrapy_redis
下载scrapy-redis例子:git clone https://github.com/rolando/scrapy-redis.git
setting.py中:
# 去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 调度器内容持久化
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
# 负责把数据存储到redis数据库里
'scrapy_redis.pipelines.RedisPipeline': 400,
}
最后需把redis加上

序列化:把一个类的对象变成字符串最后保存到文件
反序列化:保存到文件的对象是字符串格式 --> 读取字符串 --> 对象
注:后台打印的数据较杂乱,我只想要自己爬到的东西怎么办?
第一步:
setting.py中加 LOG_LEVEL = 'WARNING'
这句代码会将不必要的数据屏蔽,屏蔽的数据如下:
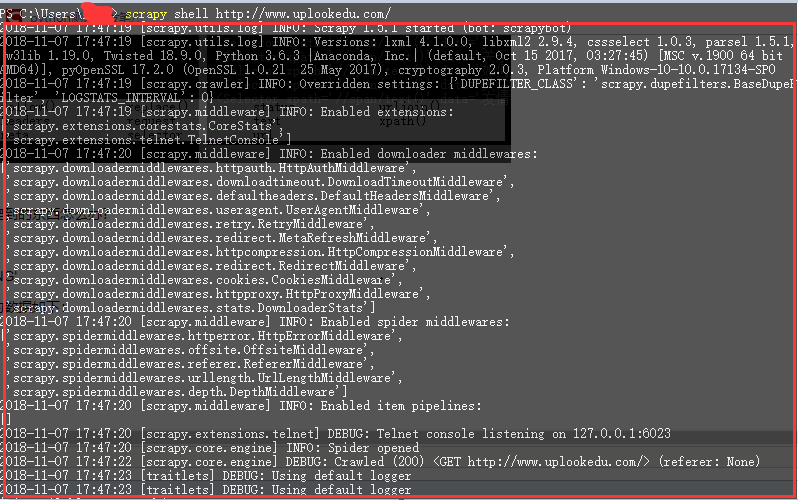
第二步:
然而现在还不是最简洁的,还有杂项。这样做,将response.xpath('*********')变成response.xpath('*********').extract()
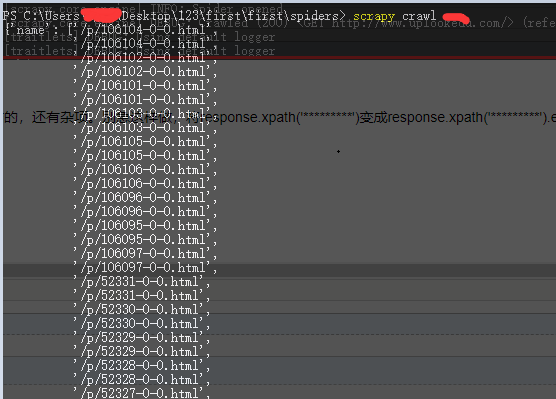
怎么样是不是你想要的。
Scrapy详解的更多相关文章
- 爬虫之Scrapy详解
性能相关 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢. import requests def fetch_async(url): ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- 【图文详解】scrapy安装与真的快速上手——爬取豆瓣9分榜单
写在开头 现在scrapy的安装教程都明显过时了,随便一搜都是要你安装一大堆的依赖,什么装python(如果别人连python都没装,为什么要学scrapy….)wisted, zope interf ...
- 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装爬虫框架Scrapy(离线方式和在线方式)(图文详解)
不多说,直接上干货! 参考博客 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装OpenCV(离线方式和在线方式)(图文详解) 第一步:首先,提示升级下pip 第二步 ...
- scrapy (三)各部分意义及框架示意图详解
一.框架示意图 Scrapy由 Python 编写,是一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- 第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解
第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解 信号一般使用信号分发器dispatcher.connect(),来设置信号,和信号触发函数,当捕获到信号时执行 ...
- 网络爬虫之scrapy框架详解
twisted介绍 Twisted是用Python实现的基于事件驱动的网络引擎框架,scrapy正是依赖于twisted, 它是基于事件循环的异步非阻塞网络框架,可以实现爬虫的并发. twisted是 ...
- 转 Scrapy笔记(5)- Item详解
Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便. Item提供了类字典的API,并且可以很方便的声明字段,很多Scra ...
- Scrapy框架的命令行详解【转】
Scrapy框架的命令行详解 请给作者点赞 --> 原文链接 这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: loca ...
随机推荐
- 圆周率pi π 与 角度的对应关系
圆周率pi π 与 角度的对应关系 π 180° π/2 90° π/4 45° π/6 30°
- JavaEE 之 SpringBoot
1.Springboot a.定义:Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程 b.约定目录结构:(Maven的资源文件目 ...
- aspnet core运行后台任务
之前在公司的一个项目中需要用到定时程序,当时使用的是aspnet core提供的IHostedService接口来实现后台定时程序,具体的示例可去官网查看.现在的dotnet core中默认封装了实现 ...
- Android Studio 常用快捷键及常用设置
Android Studio 常用快捷键及常用设置 一.常用快捷键 快捷键 描述 Ctrl + Alt + L 格式化代码 Ctrl + ( +/- ) 展开/折叠 代码块 Ctrl + Shift ...
- Kali Linux常用服务配置教程获取IP地址
Kali Linux常用服务配置教程获取IP地址 下面以Kali Linux为例,演示获取IP地址的方法 (1)设置网络接口为自动获取IP地址.在Kali Linux的收藏夹中单击图标,将显示所有的程 ...
- (二)文档请求不同源之window.name跨域
一.基本原理 window.name不是一个普通的全局变量,而是当前窗口的名字.这里要注意的是每个iframe都有包裹它的window,而这个window 是top window的子窗口,而它自然也有 ...
- 【AtCoder】【思维】【置换】Rabbit Exercise
题意: 有n只兔子,i号兔子开始的时候在a[i]号位置.每一轮操作都将若干只兔子依次进行操作: 加入操作的是b[i]号兔子,就将b[i]号兔子移动到关于b[i]-1号兔子现在所在的位置对称的地方,或者 ...
- javase 基本运算符和三大流程
范围:-(2 ^ 字节 X 8 - 1)~(2 ^ 字节 X 8 - 1)- 1 主要区别是数据大小范围: 1. byte 一个字节 -128 ~ 127 2. short 两个 ...
- __x__(34)0908第五天__ 定位 position
position 定位 指将原始摆放到页面的任意位置. 继承性:no 默认值:static 没有定位,原始出现在正常的文档流中 可选值: static : 默认值,元素没有开启定位 ...
- ValidateCode源码
ValidataCode.java: package com.itcast; /** * @author 大汉 */ import java.awt.Color; import java.awt.Fo ...