Ubuntu16.04安装编译caffe以及一些问题记录
前期准备:
最好是python虚拟环境
- 【anaconda的创建虚拟环境】
创建
conda create -n caffeEnv(虚拟环境名字) python=3.6
激活环境
source activate caffeEnv
关闭
deactivate
- 【python virtualenv创建虚拟环境】
创建
pip install virtualenv
sudo apt-get virtualenv
virtualenv caffeEnv(虚拟环境名字) -p /usr/bin/python3(版本)
激活
cd caffeEnv && source ./bin/activate
关闭
deactivate
环境条件
深度学习加速模块和opencv
- cuda8.0+cudnn5.1+opencv3.4.0
- cuda9.1+cudnn7.0+opencv3.4.0
(我试过8.0+5.1和9.1+7.0都可以)
安装教程另外两片博客记录了
caffe依赖库
sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
sudo apt-get install libboost-all-dev
sudo apt-get install libopenblas-dev liblapack-dev libatlas-base-dev
sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev
开始安装caffe
- 首先在你要安装的路径下 clone :
git clone https://github.com/BVLC/caffe.git
- 进入 caffe ,将 Makefile.config.example 文件复制一份并命名为 Makefile.config
cd caffe
cp Makefile.config.example Makefile.config
复制一份的原因是编译 caffe 时需要的是 Makefile.config 文件,Makefile.config.example 只是caffe 给出的配置文件例子
- 修改 Makefile.config 文件
gedit Makefile.config
开启cudnn
将
#USE_CUDNN := 1
修改成:
USE_CUDNN := 1
应用 opencv 版本
将
#OPENCV_VERSION := 3
修改为:
OPENCV_VERSION := 3
使用 python 接口
将
#WITH_PYTHON_LAYER := 1
修改为
WITH_PYTHON_LAYER := 1
修改库路径
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib
修改为:
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib /usr/lib/x86_64-linux-gnu /usr/lib/x86_64-linux-gnu/hdf5/serial
修改cuda路径(可选),一般不用改,由于我服务器上的cuda的版本太多,路径不一样
CUDA_DIR := /usr/local/cuda
修改为:
CUDA_DIR := /usr/local/nvidia/cuda/8.0
OK ,可以开始编译了,在 caffe 目录下执行 :
make all -j8
(-j8表示自己的cpu核数,如果不知道就直接make all)
如果出错,则检查前面步骤,或者利用搜索引擎解决问题
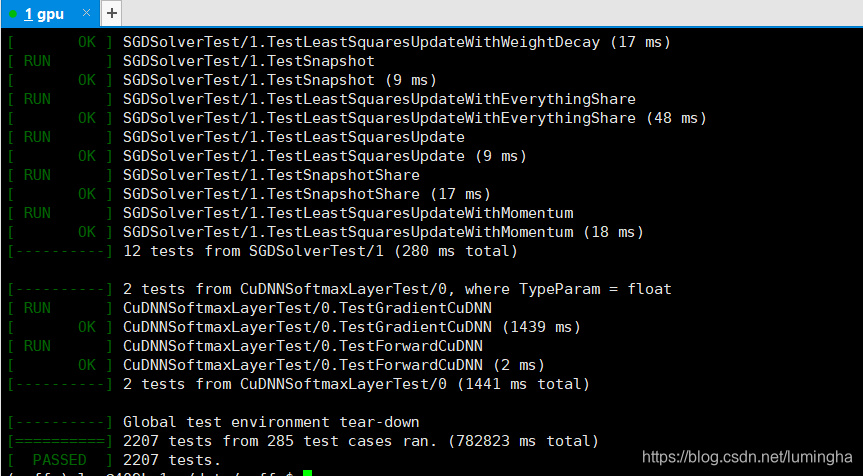
- 编译成功后可运行测试(出现以下图片类似即成功):
make runtest -j8
编译caffe的python接口
1、 编译
make pycaffe -j8
2、配置到环境变量
gedit ~/.bahsrc
把以下内容加到最下方
export PYTHONPATH=/(caffe所在目录)/caffe/python:$PYTHONPATH
若有多个环境需要添加则像如下添加方法,环境之后需要加“ : ”
export PYTHONPATH=/(caffe所在目录)/caffe/python:/home/xxx/python/:$PYTHONPATH
让环境变量生效
source ~/.bahsrc
have a try!看看能不能用
>>> import caffe
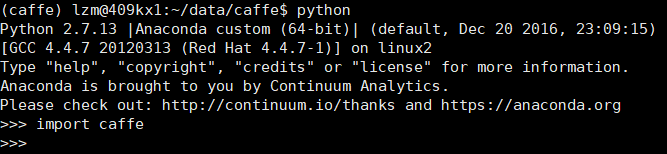
bingo!It's OK
临时配置法(记录一下给自己看)
import sys
sys.path.append("/(caff所在目录)/caffe/python")
sys.path.append("/(caffe所在目录)/caffe/python/caffe")
最后贴一些可能会出现的安装问题:
可能出现的问题
(1)

问题:
Unsupported gpu architecture 'compute_20'
解决方案:
https://askubuntu.com/questions/960238/nvcc-fatal-unsupported-gpu-architecture-compute-20
即去掉Makefile.config 中两行:
CUDA_ARCH := -gencode arch=compute_20,code=sm_20 \
-gencode arch=compute_20,code=sm_21 \
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_50,code=compute_50
改为:
CUDA_ARCH := -gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_52,code=sm_52 \
-gencode arch=compute_60,code=sm_60 \
-gencode arch=compute_62,code=sm_62 \
-gencode arch=compute_61,code=compute_61
(2)

问题:
awk: symbol lookup error: /home/lzm/.conda/envs/lzm2/lib/libreadline.so.6: undefined symbol: PC
解决方案:
https://github.com/conda-forge/rpy2-feedstock/issues/1
https://github.com/bioconda/bioconda-recipes/issues/5350
即 run
conda install -c conda-forge readline = 6.2
(3)

问题:
./include/caffe/util/hdf5.hpp:6:18: fatal error: hdf5.h: no such file or directory
解决方案:
https://github.com/BVLC/caffe/issues/2690
https://github.com/NVIDIA/DIGITS/issues/156
即Makefile.config 拿两行改掉:
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib
改为
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial/
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib /usr/lib/x86_64-linux-gnu/hdf5/serial/
(4)(这个应该很少人出现)

问题:
./include/caffe/util/nccl.hpp:5:18: fatal error: nccl.h: No such file or directory
解决方案:
新建文件为env
将服务器已经安装的nccl路径配置到env:
export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/home/lzm/data/caffe/caffe1.0_nccl/nccl/install/include
export C_INCLUDE_PATH=$C_INCLUDE_PATH:/home/lzm/data/caffe/caffe1.0_nccl/nccl/install/include
export LIBRARY_PATH=$LIBRARY_PATH:/home/lzm/data/caffe/caffe1.0_nccl/nccl/install/lib
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/lzm/data/caffe/caffe1.0_nccl/nccl/install/lib
每次要用的时候都激活环境:
source ./env
(5)

问题:
.build_release/lib/libcaffe.so: undefined reference to `cv::imdecode
解决方案:https://github.com/BVLC/caffe/issues/4621
把Makefile.config 中 OPENCV_VERSION = 3的注释去掉即可
(6)

问题:
/caffe/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.21' not found (required by caffe-ssh/python/caffe/_caffe.so)
解决方案:https://github.com/BVLC/caffe/issues/4953
conda install libgcc
Ubuntu16.04安装编译caffe以及一些问题记录的更多相关文章
- Ubuntu16.04安装配置Caffe教程(GPU版)
推荐博客:https://www.linuxidc.com/Linux/2017-11/148629.htmhttps://blog.csdn.net/yggaoeecs/article/detail ...
- Ubuntu16.04 安装配置Caffe
Caffe已经是第三次安装配置了,为什么是第三次呢?因为我实在是低估了深度学习对于硬件的要求.第一次我在自己笔记本上配置的单核,CPU only ... 结果是,样例数据跑了4小时,这还怎么玩?第二 ...
- Ubuntu16.04安装K8s步骤和踩坑记录【不错】
文章目录环境信息安装步骤系统配置修改安装docker安装kubectl,kubelet,kubeadm配置Master配置Node部署结果检查K8S部署mysql学习新建mysql-rc.yaml创建 ...
- Ubuntu16.04下编译安装OpenCV3.4.0(C++ & python)
Ubuntu16.04下编译安装OpenCV3.4.0(C++ & python) 前提是已经安装了python2,python3 1)安装各种依赖库 sudo apt-get update ...
- Ubuntu16.04安装opencv for python/c++
Ubuntu16.04安装opencv for python/c++ 网上关于opencv的安装已经有了不少资料,但是没有一篇资料能让我一次性安装成功,因此花费了大量时间去解决各种意外,希望这篇能给一 ...
- Ubuntu16.04安装cuda9.0+cudnn7.0
Ubuntu16.04安装cuda9.0+cudnn7.0 这篇记录拖了好久,估计是去年6月份就已经安装过几遍,然后一方面因为俺比较懒,一方面后面没有经常在自己电脑上跑算法,比较少装cuda和cudn ...
- Ubuntu16.04安装配置和使用ctags
Ubuntu16.04安装配置和使用ctags by ChrisZZ ctags可以用于在vim中的函数定义跳转.在ubuntu16.04下默认提供的ctags是很老很旧的ctags,快要发霉的版本( ...
- Ubuntu16.04安装vim8
Ubuntu16.04安装vim8 在Ubuntu16.04下编译安装vim8,并配置vim-plug插件管理器,以及安装YouCompleteMe等插件. 安装依赖 sudo apt-get ins ...
- ubuntu16.04安装nvidia ,cuda(待完善)
ubuntu16.04安装nvidia 1.首先查看自己的pc显卡的型号 ubuntu16.04 查看方法: 查看GPU型号 :lspci | grep -i nvidia 查看NVIDIA驱动版本: ...
随机推荐
- x86汇编语言实践(3)
0 写在前面 为了更深入的了解程序的实现原理,近期我学习了IBM-PC相关原理,并手工编写了一些x86汇编程序. 在2017年的计算机组成原理中,曾对MIPS体系结构及其汇编语言有过一定的了解,考虑到 ...
- posgreSQL安装失败解决方案
选择适合自己电脑版本的postgreSQL进行安装,显示安装失败,错误信息:problem running post-install step.installation may not complet ...
- C++回顾day03---<string字符串操作>
一:string优点 相比于char*的字符串,C++标准程序库中的string类不必担心内存是否足够.字符串长度等等 而且作为一个类出现,他集成的操作函数足以完成我们大多数情况下的需要. 二:str ...
- hive 时间函数
使用时发现:1.datediff可以传入timestamp类型参数 官网文档: Date Functions The following built-in date functions are ...
- CentOS7设置ssh服务以及端口修改
很多时候我们都是通过SSH 服务 来对 Linux 进行操作,而不是直接来操作Linux机器,包括对Linux服务器的操作,因此,设置SSH服务对于学习Linux来说属于必备技能(尤其是运维人员),关 ...
- H5_0004:JS设置循环debugger的方法
在HTML页面加上如下代码,则PC打开控制台后,就会循环debugger,防止调试代码. <script>eval(function (p, a, c, k, e, r) { e = fu ...
- django——个人博客之分页/筛选功能
在完成了注册.登录后就应该显示主页,在主页中有各种功能的按钮,用户点击后进入后台管理,不同角色的用户根据权限不同显示的页面是不相同的,在个人博客页面会显示自己发布的文章,以及自己的保障记录,在进入后台 ...
- table自适应大小,以及内容换行
在table的样式中加入以下两个样式: table-layout: fixed; word-wrap:break-word;
- Tree POJ - 1741【树分治】【一句话说清思路】
因为该博客的两位作者瞎几把乱吹(" ̄︶ ̄)人( ̄︶ ̄")用彼此的智慧总结出了两条全新的定理(高度复杂度定理.特异根特异树定理),转载请务必说明出处.(逃 Pass:anuonei, ...
- xin
测试文件 行内公式 y = x 独立公式 limx → 0x = 0