神经网络_线性神经网络 1 (Nerual Network_Linear Nerual Network 1)
2019-04-08 16:59:23
1 学习规则(Learning Rule)
1.1 赫布学习规则(Hebb Learning Rule)
1949年,Hebb提出了关于神经网络学习机理的“突触修正”的假设:当神经元的前膜电位、后膜电位同时为正时,突触传导加强;电位相反时,突触传导减弱。根据次假设定义权值ω的调整方法,称该方法为Hebb学习规则。
Hebb学习规则中,学习信号等于神经元的输出:
r=f(WTj*X)
权值向量W调整公式:
ΔW=η*f(WTj*X)*X
权值向量W的分向量Δωij调整公式:
Δωj=η*f(WTj*X)*xj,j=0,1,2,…,n
为保证Hebb learning rule 的学习效率,对权值设置饱和值。
for examle:
1 参数设置
输入:X1=[1,-2,1.5]T、X1=[1,-0.5,-2]T、X1=[0,-1,-1]T,学习率 η=1,初始化权值W0=[0 0 0]T,传递函数使用hardlim。
2 计算步骤(即权值调整过程)
权值W1=W0+hardlim(W0T*X1)*X1=[1 -2 1.5];
权值W2=W1+hardlim(W1T*X2)*X2=[1 -2 1.5];
权值W3=W2+hardlim(W2T*X3)*X3=[1 -3 0.5];
1.2 感知器学习规则(Perceptron Leaning Rule)
1 感知器的学习规则
r=dj-oj
式中,dj为期望输出,oj=f(WjT*X)
感知器采用符号函数作为转移函数,则
f(WjT*X)=sgn(WjT*X)={1,WjT*X≥0;0,WjT*X<0}
由上式得权值调整公式
ΔWj=η*[dj-sgn(WjT*X)]*X
Δωj=η*[dj-sgn(WjT*X)]*xj
2 Hebb learning principle 和 Perceptron learning principle的不同之处
Hebb learning principle 采用输出结果作为权值调整的组成部分,Perceptron learning principle 采用误差作为权值调整的组成部分。
1.3 最小均方差学习规则(Least Mean Square Error Leaning Rule)
1.3.1 LMS学习规则特点
感知器学习规则训练的网络,其分类的判决边界往往距离各分类模式靠的比较近,这使得网络对噪声比较敏感;
LMS Learing Rule是均方误差最小,进而使得判决边界尽可能远离分类模式,增强了网络的抗噪声能力。
但LMS算法仅仅适用于单层的网络训练,当需要设计多层网络时,需要寻找新的学习算法,for example,Back Progation Nerual Network Algorithm。
1962年,Bernard Widrow 和 Marcian Hoff 提出Widrow-Hoff Learning Princple,该方法的特点是使实际神经元输出与期望输出之间的平方差最小,因此又称为Least Mean Square Erorr Princple。
LMS调整规则应用较为广泛:
1 信号处理
2 BP算法的引领者
1.3.2 LMS学习规则计算
LMS的学习信号
r=tj-WjT*X
权值调整量
ΔWj=η*(tj-WjT*X)*X
权值分量调整
Δωj=η*(tj-WjT*X)*xj,j=0,1,2,...,n
tj表示期望输出,WjT*X表示实际输出
1.3.2 MSE学习规则
均方差(MSE),是预测数据与原始数据的误差平方的和的均值
MSE=(∑(ti-ai)2)/n,其中i=1,2,...,n
Matlab中存在该函数,可以直接调用,e=[1 2 3],perf=mse(e)=(12+22+32)/n=4.66666667。
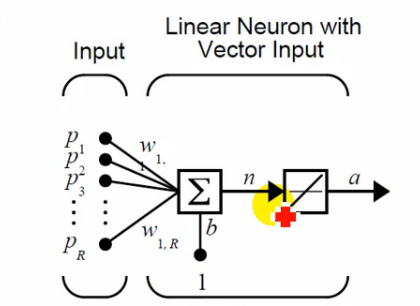
2 线性神经网络
2.1线性神经网路结构
1 参数设置
神经网络结构函数 Purelin


神经网络_线性神经网络 1 (Nerual Network_Linear Nerual Network 1)的更多相关文章
- 神经网络_线性神经网络 2 (Nerual Network_Linear Nerual Network 2)
1 LMS 学习规则 1.1 LMS学习规则定义 MSE=(1/Q)*Σe2k=(1/Q)*Σ(tk-ak)2,k=1,2,...,Q 式中:Q是训练样本:t(k)是神经元的期望输出:a(k)是神经元 ...
- 神经网络_线性神经网络 3 (Nerual Network_Linear Nerual Network 3)
1 LMS 学习规则_解方程组 1.1 LMS学习规则举例 X1=[0 0 1]T,t1=0:X2=[1 0 1]T,t2=0:X3=[0 1 1]T,t3=0:X1=[1 1 1]T,t1=1. 设 ...
- 单层感知机_线性神经网络_BP神经网络
单层感知机 单层感知机基础总结很详细的博客 关于单层感知机的视频 最终y=t,说明经过训练预测值和真实值一致.下面图是sign函数 根据感知机规则实现的上述题目的代码 import numpy as ...
- 使用MindSpore的线性神经网络拟合非线性函数
技术背景 在前面的几篇博客中,我们分别介绍了MindSpore的CPU版本在Docker下的安装与配置方案.MindSpore的线性函数拟合以及MindSpore后来新推出的GPU版本的Docker编 ...
- 『PyTorch』第四弹_通过LeNet初识pytorch神经网络_下
『PyTorch』第四弹_通过LeNet初识pytorch神经网络_上 # Author : Hellcat # Time : 2018/2/11 import torch as t import t ...
- 自适应线性神经网络Adaline
自适应线性神经网络Adaptive linear network, 是神经网络的入门级别网络. 相对于感知器, 采用了f(z)=z的激活函数,属于连续函数. 代价函数为LMS函数,最小均方算法,Lea ...
- RBF神经网络和BP神经网络的关系
作者:李瞬生链接:https://www.zhihu.com/question/44328472/answer/128973724来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注 ...
- 神经网络与BP神经网络
一.神经元 神经元模型是一个包含输入,输出与计算功能的模型.(多个输入对应一个输出) 一个神经网络的训练算法就是让权重(通常用w表示)的值调整到最佳,以使得整个网络的预测效果最好. 事实上,在神经网络 ...
- BZOJ_2460_[BeiJing2011]元素_线性基
BZOJ_2460_[BeiJing2011]元素_线性基 Description 相传,在远古时期,位于西方大陆的 Magic Land 上,人们已经掌握了用魔 法矿石炼制法杖的技术.那时人们就认识 ...
随机推荐
- GitLab实战操作指南
一.Git原理 1.Git是什么? Git是目前世界上最先进的分布式版本控制系统(没有之一). 2.Git有什么特点? 简单来说就是:高端大气上档次! 3.GIt与SVN区别 SVN管理: 属于集中式 ...
- Unity iOS Appstore 上架的问题
之前一直是一个人的名义上架的应用.现在变成:公司的账号就会出现一些莫名的问题: 首先是账号需要新的boulder名字,新建之后下载验证key. 注意:真机测试不发布,选择自动签名就行了:需要发布就取消 ...
- MySQL-mysql 8.0.11安装教程
网上的教程有很多,基本上大同小异.但是安装软件有时就可能因为一个细节安装失败.我也是综合了很多个教程才安装好的,所以本教程可能也不是普遍适合的. 安装环境:win7 1.下载zip安装包: MySQL ...
- unity中加载场景不销毁以及切换场景重复实例化
问题描述 游戏开发中会有多个场景,有时会有这样的需求,我们需要保证场景跳转但是需要保持某个游戏对象不被销毁,比如:音乐 实现思路 unity中提供了DontDestroyOnLoad(),这个API ...
- javascript中的浅拷贝ShallowCopy与深拷贝DeepCopy
拷贝,在js中,分为浅拷贝和深拷贝.这两者是如何区分的呢?又是如何实现的呢? 深浅拷贝的区分 首先说下,在js中,分为基础数据类型和复杂数据类型, 基础数据类型:Undefined.Null.Bool ...
- 《ServerSuperIO Designer IDE使用教程》-2.与硬件网关数据交互,并进行数据级联转发,直到云端。发布:v4.2.1版本
v4.2.1 更新内容:1.重新定义数据转发文本协议,使网关与ServerSuperIO以及之间能够相关交互数据.2.扩展ServerSuperIO动态数据类的方法,更灵活.3.修复Designer增 ...
- Linux内核优化
相信做运维的同仁,进行运维环境初建时,必须要考虑到操作系统内核参数的优化问题,本人经历数次的运维环境重建后,决定要自行收集一份比较完善的系统内核参数优化说明文件出来,于是就有了下文,本文当前值是官方 ...
- java-数组排序--计数排序、桶排序、基数排序
计数排序引入 不难发现不论是冒泡排序还是插入排序,其排序方法都是通过对每一个数进行两两比较进行排序的,这种方法称为比较排序,实际上对每个数的两两比较严重影响了其效率,理论上比较排序时间复杂度的最低下限 ...
- mapreduce项目中加入combiner
combiner相当于是一个本地的reduce,它的存在是为了减少网络的负担,在本地先进行一次计算再叫计算结果提交给reduce进行二次处理. 现在的流程为: 对于combiner我们有这些理解: M ...
- FlaskWeb开发:基于Python的Web应用开发实战
所属网站分类: 资源下载 > python电子书 作者:熊猫烧香 链接:http://www.pythonheidong.com/blog/article/63/ 来源:python黑洞网,专注 ...