Cache Aside Pattern
Cache Aside Pattern 即旁路缓存是缓存方案的经验实践,这个实践又分读实践,写实践
对于读请求
先读cache,再读db
如果,cache hit,则直接返回数据
如果,cache miss,则访问db,并将数据set回缓存
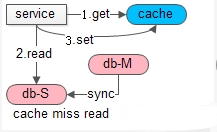
如上图:
(1)先从cache中尝试get数据,结果miss了
(2)再从db中读取数据,从库,读写分离
(3)最后把数据set回cache,方便下次读命中
对于写请求
淘汰缓存,而不是更新缓存
先操作数据库,再淘汰缓存

如上图:
(1)第一步要操作数据库,第二步操作缓存
(2)缓存,采用delete淘汰,而不是set更新
Cache Aside Pattern为什么建议淘汰缓存,而不是更新缓存?如果更新缓存,在并发写时,可能出现数据不一致。
如上图所示,如果采用set缓存。
在1和2两个并发写发生时,由于无法保证时序,此时不管先操作缓存还是先操作数据库,都可能出现:
(1)请求1先操作数据库,请求2后操作数据库
(2)请求2先set了缓存,请求1后set了缓存
导致,数据库与缓存之间的数据不一致。
所以,Cache Aside Pattern建议,delete缓存,而不是set缓存。
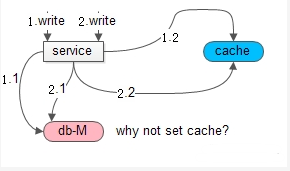
Cache Aside Pattern为什么建议先操作数据库,再操作缓存?
如果先操作缓存,在读写并发时,可能出现数据不一致。

如上图所示,如果先操作缓存。
在1和2并发读写发生时,由于无法保证时序,可能出现:
(1)1.1 写请求淘汰了缓存
(2)1.2 写请求操作了数据库(主从同步没有完成)
(3)2.1 读请求读了缓存(cache miss)
(4)2.2 读请求读了从库(读了一个旧数据)
(5)2.3 读请求set回缓存(set了一个旧数据)
(6)1.3 数据库主从同步完成
导致,数据库与缓存的数据不一致。
所以,Cache Aside Pattern建议,先操作数据库,再操作缓存。
先操作数据库再操作缓存, 在读写并发时,也可能出现数据不一致。

如上图所示,如果先操作数据库。
(1)1.1 读请求读了缓存(cache miss)
(2)1.2 读请求读了从库(读了一个旧数据)
(3)2.1 写请求操作了数据库
(4)2.2 写请求淘汰缓存(cache miss 淘汰跟没淘汰一样)
(5)1.3 读请求set回缓存(set了一个旧数据)
(6)2.3 数据库主从同步完成
导致,数据库与缓存的数据不一致
但是:先淘汰缓存再更新数据库方案中,写请求 淘汰缓存后 被 读请求 set回一个旧数据,这种并发出现的几率很大。 而: 先更新数据库再淘汰缓存方案中,读请求 在写请求之前读了数据且data miss,又要在写请求之后set缓存, 这种几率很小。 所以:Cache Aside Pattern建议,先操作数据库,再操作缓存。
Cache Aside Pattern方案存在什么问题?
答:如果先操作数据库,再淘汰缓存,在原子性被破坏时:
(1)修改数据库成功了
(2)淘汰缓存失败了
导致,数据库与缓存的数据不一致。
参考:58沈剑 架构师之路
Cache Aside Pattern的更多相关文章
- 缓存实践Cache Aside Pattern
Cache Aside Pattern旁路缓存,是对缓存应用的一个总结,包括读数据方案和写数据方案. 读数据方案 先读cache,如果命中则返回 如果miss则读db 将db的数据存入缓存 写数据方案 ...
- 别再犯低级错误,带你了解更新缓存的四种Desigh Pattern
在我们使用分布式缓存Redis或者Memcached编写更新缓存数据代码时,我们总是会犯一个逻辑错误.先删除缓存,然后再更新数据库,而后续的操作会把数据再装载的缓存中.试想,两个并发操作,一个是更新操 ...
- cache and database
This article referenced from http://coolshell.cn/articles/17416.html We all know that high concurren ...
- [Java复习] 缓存Cache part2
7. Redis持久化有哪几种方式?不同的持久化机制都有什么优缺点?持久化机制具体底层是如何实现的? 为什么要持久化? 如果只是存在内存里,如果redis宕机再重启,内存数据就丢失了,所以要用持久化机 ...
- 缓存模式(Cache Aside、Read Through、Write Through、Write Behind)
目录 概览 Cache-Aside 读操作 更新操作 缓存失效 缓存更新 Read-Through Write-Through Write-Behind 总结 参考 概览 缓存是一个有着更快的查询速度 ...
- Tomcat源码分析——SERVER.XML文件的加载与解析
前言 作为Java程序员,对于Tomcat的server.xml想必都不陌生.本文基于Tomcat7.0的Java源码,对server.xml文件是如何加载和解析的进行分析. 加载 server.xm ...
- Memcache(1)
一.缓存套路 原文地址:http://coolshell.cn/articles/17416.html Scaling Memcached at Facebook 好些人在写更新缓存数据代码时,先删除 ...
- 面试前必须要知道的Redis面试题
前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y 回顾前面: 从零单排学Redis[青铜] 从零单排学 ...
- redis缓存雪崩、缓存穿透、数据库和redis数据一致性
一.缓存雪崩 回顾一下我们为什么要用缓存(Redis):减轻数据库压力或尽可能少的访问数据库. 在前面学习我们都知道Redis不可能把所有的数据都缓存起来(内存昂贵且有限),所以Redis需要对数据设 ...
随机推荐
- Visual Studio 2017
美国西雅图时间 3 月 7 日上午 9 点(北京时间 8 日凌晨 1 点),微软将正式发布 Visual Studio 2017. 下载地址:https://www.visualstudio.co ...
- ExtJS5搭建MVVM框架
概述 · ExtJs5能够搭建Js的MVC框架,通过配置路由能够通过左边树形菜单导航到所需的页面,效果如下: 搭建JS框架 新建home.htm页面作为ExtJs加载的主体页面,页面引入ExtJs需要 ...
- tensorflow会话控制-【老鱼学tensorflow】
在tensorflow中,当定义好结构后,就要通过tf.session()来建立运行时的会话. 本例子应该不难理解,我们用tensorflow来计算一下一个1行2列的矩阵和2行1列矩阵的乘积: imp ...
- html_头部<meta>设置
<!DOCTYPE html> : 定义HTML的规则类型:浏览器兼容性最好 <!DOCTYPE html><html> <head> <!--编 ...
- Jarvis OJ 一些简单的re刷题记录和脚本
[61dctf] androideasy 164求解器 50 相反 脚本如下: s='' a=113, 123, 118, 112, 108, 94, 99, 72, 38, 68, 72, 87, ...
- MFC版链表实现稀疏多项式相加减
链表实现多项式运算(加减)MFC可视化版 题目 设计一个一元稀疏多项式简单计算器. 基本要求 (1)输入并建立两个多项式: (2)多项式a与b相加,建立和多项式c: (3)多项式a与b相减,建立差多项 ...
- phantomjs 中文文档
phantomjs 中文文档 转载 入门教程:转载 http://www.cnblogs.com/front-Thinking/p/4321720.html 1.介绍 简介 PhantomJS是一 ...
- springboot集成springsession利用redis来实现session共享
转:https://www.cnblogs.com/mengmeng89012/p/5519698.html 这次带来的是spring boot + redis 实现session共享的教程. 在sp ...
- js 工厂模式、简单模式、抽象模式
简单工厂模式又称为静态工厂方法,由一个工厂对象决定创建某一种产品对象类的实例,主要用来创建同一类的对象.其实,工厂模式的思想主要是将相同/相似的的对象或类进行提取归类,这样的话,就可以避免写太多重复性 ...
- 梦里寻她千百度,Bug却在隔壁老张处
程序员与 Bug 是一对矛盾的存在,程序员既要在解决 Bug 中获得成就感,同时也讨厌 Bug 本身的存在.“程序不息,Bug 不止”,程序员在与 Bug 的斗争中,也有很多有趣的事情发生,我们整理了 ...