python爬取某站磁力链
不同磁力链网站网页内容都不同,需要定制
1,并发爬取
并发爬取后,好像一会就被封了
import requests
from lxml import etree
import re
from concurrent.futures import ThreadPoolExecutor def get_mlink(url, headers):
"""输入某影片磁力链所在的网页,返回该网页中的磁力链"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
try:
magnetlink = select.xpath('//textarea[@id="magnetLink"]//text()')
return magnetlink[0]
except AttributeError:
return None def get_page_mlinks(url, headers):
"""输入某一页搜索结果,返回该网页中所有的元组(url, 影片大小,时间,磁力链)"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
div_rows = select.xpath('//div[@class="row"]') def get_each(se):
size = se.xpath('.//div[@class="col-sm-2 col-lg-1 hidden-xs text-right size"]//text()')
date = se.xpath('.//div[@class="col-sm-2 col-lg-2 hidden-xs text-right date"]//text()')
href = se.xpath('.//a/@href')
try:
return href[0], size[0], date[0], get_mlink(href[0], headers)
except IndexError:
pass with ThreadPoolExecutor() as executor: # 并发执行爬取单个网页中所有的磁力链
res = executor.map(get_each, div_rows) return res def get_urls(baseurl, headers, suffix=None):
"""输入搜索网页,递归获取所有页的搜索结果"""
if suffix:
url = baseurl + suffix
else:
url = baseurl r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
page_suffixes = select.xpath('//ul[@class="pagination pagination-lg"]'
'//li//a[@name="numbar"]/@href') # 有时该站会返回/search/.../search/...search/.../page,需要处理下
p = r'/search/[^/]+/page/\d+(?=\D|$)'
page_suffixes = [re.search(p, i).group() for i in page_suffixes] # 如果还有下一页,需要进一步递归查询获取
r = requests.get(url + page_suffixes[-1], headers=headers)
select = etree.HTML(r.text)
next_page = select.xpath('//ul[@class="pagination pagination-lg"]'
'//li//a[@name="nextpage"]/@href')
if next_page:
page_suffixes = page_suffixes + get_urls(baseurl, headers, next_page[0]) return page_suffixes if __name__ == '__main__':
keyword = "金刚狼3"
baseurl = 'https://btsow.club/search/{}'.format(keyword) # 该站是采用get方式提交搜索关键词
headers = {"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4"} urls = get_urls(baseurl, headers)
new_urls = list(set(urls))
new_urls.sort(key=urls.index)
new_urls = [baseurl + i for i in new_urls] with ThreadPoolExecutor() as executor:
res = executor.map(get_page_mlinks, new_urls, [headers for i in range(7)]) for r in res:
for i in r:
print(i)
2,逐页爬取
手工输入关键词和页数
超过网站已有页数时,返回None
爬取单个搜索页中所有磁力链时,仍然用的是并发
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutor def get_mlink(url, headers):
"""输入某影片磁力链所在的网页,返回该网页中的磁力链"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
try:
magnetlink = select.xpath('//textarea[@id="magnetLink"]//text()')
return magnetlink[0]
except AttributeError:
return None def get_page_mlinks(url, headers):
"""输入某一页搜索结果,返回该网页中所有的元组(url, 影片大小,时间,磁力链)"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
div_rows = select.xpath('//div[@class="row"]') def get_each(se):
size = se.xpath('.//div[@class="col-sm-2 col-lg-1 hidden-xs text-right size"]//text()')
date = se.xpath('.//div[@class="col-sm-2 col-lg-2 hidden-xs text-right date"]//text()')
href = se.xpath('.//a/@href')
try:
return href[0], size[0], date[0], get_mlink(href[0], headers)
except IndexError:
pass with ThreadPoolExecutor() as executor: # 并发执行爬取单个网页中所有的磁力链
res = executor.map(get_each, div_rows) return res if __name__ == '__main__':
keyword = input('请输入查找关键词>> ')
page = input('请输入查找页>> ') url = 'https://btsow.club/search/{}/page/{}'.format(keyword, page)
headers = {"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4"} r = get_page_mlinks(url, headers)
for i in r:
print(i)
3,先输入影片,在选择下载哪个磁力链
import requests
from lxml import etree def get_mlink(url, headers):
"""输入某影片磁力链所在的网页,返回该网页中的磁力链"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
try:
magnetlink = select.xpath('//textarea[@id="magnetLink"]//text()')
return magnetlink[0]
except AttributeError:
return None def get_row(row):
size = row.xpath('.//div[@class="col-sm-2 col-lg-1 hidden-xs text-right size"]//text()')
date = row.xpath('.//div[@class="col-sm-2 col-lg-2 hidden-xs text-right date"]//text()')
href = row.xpath('.//a/@href')
title = row.xpath('.//a/@title')
try:
return href[0], size[0], date[0], title[0]
except IndexError:
pass if __name__ == '__main__':
headers = {"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4"} while True:
keyword = input('请输入查找关键词>> ')
if keyword == 'quit':
break
url = 'https://btsow.club/search/{}'.format(keyword)
r = requests.get(url, headers=headers)
print(r.status_code) select = etree.HTML(r.text)
div_rows = select.xpath('//div[@class="row"]')
div_rows = [get_row(row) for row in div_rows if get_row(row)]
if not div_rows:
continue
for index, row in enumerate(div_rows):
print(index, row[2], row[1], row[3]) # 选择和下载哪部片子
choice = input('请选择下载项>> ')
try: # 如果不是数字,退回到输入关键词
choice = int(choice)
except ValueError:
continue
download_url = div_rows[choice][0]
mlink = get_mlink(download_url, headers)
print(r.status_code)
print(mlink)
print('\n\n')
执行效果:
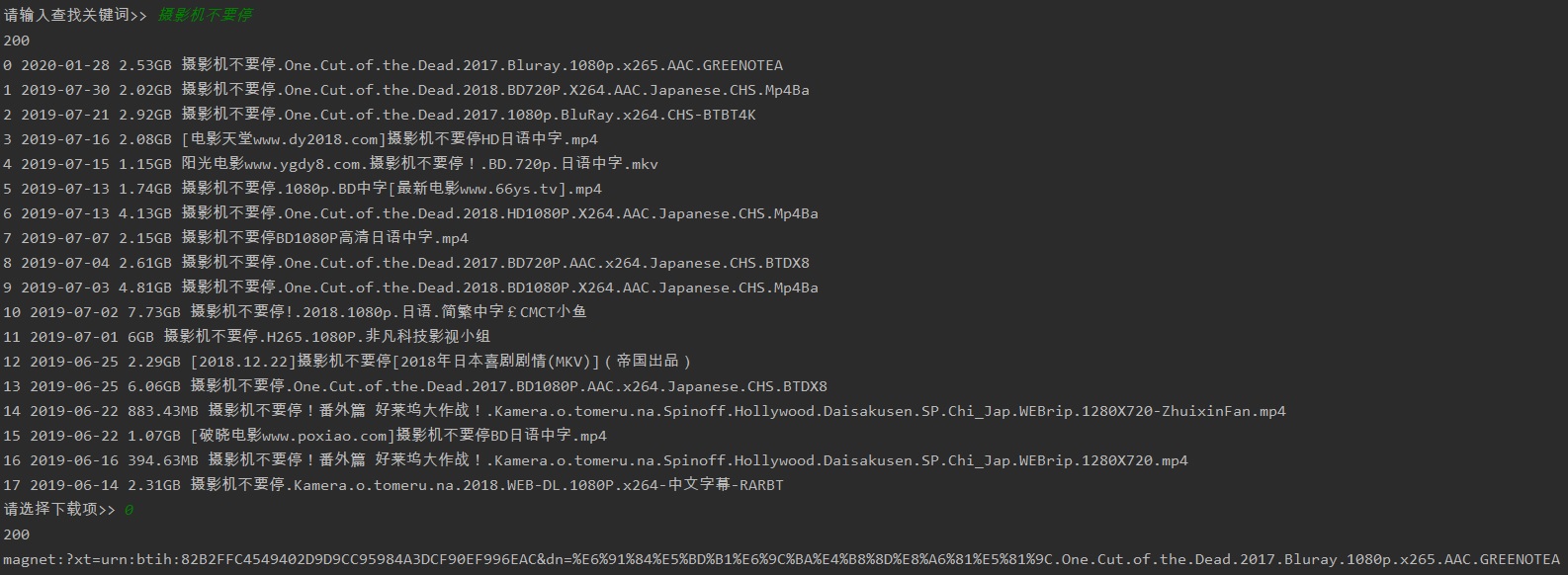
4,补充下lxml的使用
<div class="item" data-houseid="*****">
*************************************************************
</div> <div class="item" data-houseid="107102426781">
<a class="img" href="https://sh.lianjia.com/ershoufang/107102426781.html" target="_blank" data-bl="list" data-log_index="5" data-housecode="107102426781" data-is_focus="" data-el="ershoufang">
<img class="lj-lazy" src="https://s1.ljcdn.com/feroot/pc/asset/img/blank.gif?_v=20200428212347" data-original="https://image1.ljcdn.com/110000-inspection/pc1_JZKtMEOU3_1.jpg.296x216.jpg.437x300.jpg">
<div class="btn-follow follow" data-hid="107102426781"><span class="star"></span><span class="follow-text">关注</span></div>
<div class="leftArrow"><span></span></div>
<div class="rightArrow"><span></span></div><div class="price"><span>375</span>万</div>
</a>
<a class="title" href="https://sh.lianjia.com/ershoufang/107102426781.html" target="_blank" data-bl="list" data-log_index="5" data-housecode="107102426781" data-is_focus="" data-el="ershoufang">临河位置,全明户型带边窗,满五年唯一,拎包入住</a>
<div class="info">
御桥
<span>/</span>
2室1厅
<span>/</span>
50.11平米
<span>/</span>
南
<span>/</span>
精装
</div>
<div class="tag"><span class="subway">近地铁</span><span class="vr">VR房源</span></div>
</div> <div class="tag"><span class="subway">近地铁</span><span class="vr">VR房源</span></div> </div> <div class="item" data-houseid="*****">
*************************************************************
</div>
要获取所有房源tilte,价格,朝向,装修情况等,可以:
elements = select.xpath('//div[@class="item"]') # 所有房源组成的items列表,即所有class='item'的div标签
for element in elements:
title = element.xpath('a[@class="title"]/text()')[0] # class='item'的div标签下,所有class='title'的a标签
price = element.xpath('a[@class="img"]/div[@class="price"]/span/text()')[0]
_, scale, size, orient, deco = element.xpath('div[@class="info"]/text()')
print(title, price, scale, size, orient, deco)
输入某小区的结果:
中间楼层+精装保养好+满两年+双轨交汇+诚意出售 385 2室1厅 62.7平米 南 精装
南北通风,户型方正,楼层佳位置佳,11/18号线双轨 368 2室1厅 52.49平米 南 精装
一手动迁 业主置换 急售 双南采光佳 看房方便 370 2室1厅 62.7平米 南 简装
临河位置,全明户型带边窗,满五年唯一,拎包入住 375 2室1厅 50.11平米 南 精装
一手动迁,税费少,楼层采光好,精装修。 388 2室1厅 62.7平米 南 精装
南北通两房 近地铁 拎包入住 业主诚意出售 508 2室2厅 90.88平米 南 其他
python爬取某站磁力链的更多相关文章
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
- python爬取某站新闻,并分析最近新闻关键词
在爬取某站时并做简单分析时,遇到如下问题和大家分享,避免犯错: 一丶网站的path为 /info/1013/13930.htm ,其中13930为不同新闻的 ID 值,但是这个数虽然为升序,但是没有任 ...
- 用python爬取B站在线用户人数
最近在自学Python爬虫,所以想练一下手,用python来爬取B站在线人数,应该可以拿来小小分析一下 设计思路 首先查看网页源代码,找到相应的html,然后利用各种工具(BeautifulSoup或 ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- python爬取b站排行榜
爬取b站排行榜并存到mysql中 目的 b站是我平时看得最多的一个网站,最近接到了一个爬虫的课设.首先要选择一个网站,并对其进行爬取,最后将该网站的数据存储并使其可视化. 网站的结构 目标网站:bil ...
- Python爬取b站任意up主所有视频弹幕
爬取b站弹幕并不困难.要得到up主所有视频弹幕,我们首先进入up主视频页面,即https://space.bilibili.com/id号/video这个页面.按F12打开开发者菜单,刷新一下,在ne ...
- Python爬取B站耗子尾汁、不讲武德出处的视频弹幕
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 前言 耗子喂汁是什么意思什么梗呢?可能很多人不知道,这个梗是出自马保国,经常上网的人可能听说过这个 ...
- 使用python爬取P站图片
刚开学时有一段时间周末没事,于是经常在P站的特辑里收图,但是P站加载图片的速度比较感人,觉得自己身为计算机专业,怎么可以做一张张图慢慢下这么low的事,而且这样效率的确也太低了,于是就想写个程序来帮我 ...
随机推荐
- Linux进程PRI与NI值
1.PRI -> 进程的优先级,大部分系统(Linux.UCOSII)都是数字越低优先级越高,进程就优先运行 , Linux中的PRI(new) = PRI(old) + nice ,其中 , ...
- 00JAVA语法基础_动手动脑
1.仔细阅读示例: EnumTest.java,运行它,分析运行结果? 枚举类型的使用是借助ENUM这样一个类,这个类是JAVA枚举类型的公共基本类.枚举目的就是要让某个变量的取值只能为若干固定值中的 ...
- 在绘图的时候import matplotlib.pyplot as plt报错:ImportError: No module named '_tkinter', please install the python-tk package
在绘图的时候import matplotlib.pyplot as plt报错:ImportError: No module named '_tkinter', please install the ...
- JSON.parse与JSON.stringify
JSON:JavaScript Object Notation(JavaScript对象表示法):甚至我们就可以大致认为JSON就是Javascript的对象,只不过范围小上一些. JSON的MIME ...
- [ISSUE] [Centos] Centos Start Nginx Show: Failed to start nginx.service:unit not found
CMD Line:systemctl start nginx.serviceFailed to start nginx.service: Unit not found. Solution: 1.vim ...
- IT题库9-线程池的概念和原理
在什么情况下使用线程池? 1.单个任务处理的时间比较短:2.需要处理的任务的数量大: 使用线程池的好处: 1.减少在创建和销毁线程上所花的时间以及系统资源的开销.2.如不使用线程池,有可能造成系统创建 ...
- Lua 哑变量
[1]哑变量 哑变量,又称为虚拟变量.名义变量. 还得理解汉语的博大精深,‘虚拟’.‘名义’.‘哑’等等,都是没有实际意义.所以,哑变量即没有现实意义的变量. 哑变量的应用示例如下: local fi ...
- DataGridView上下键事件获取到的是上次停留行的内容
DataGridView上下键事件 在DataGridView中,通过上下键将选中行的内容返回, 问题: 通过上边的方法总是获取到上次停留行的内容,不是当前选中行的内容. winform的项目,使用C ...
- java中的getStackTrace和printStackTrace的区别
getStackTrace()返回的是通过getOurStackTrace方法获取的StackTraceElement[]数组,而这个StackTraceElement是ERROR的每一个cause ...
- 使用 lsyncd 同步文件
https://unix.stackexchange.com/questions/307046/real-time-file-synchronization https://github.com/ax ...