大数据Hadoop——HDFS Shell操作
一.查询目录下的文件
1.查询根目录下的文件
Hadoop fs -ls /

2.查询文件夹下的文件
Hadoop fs -ls /input

二.创建文件夹
hadoop fs -mkdir /文件名称

三. 上传本地文件到HDFS中
hadoop fs -put 文件名称 文件名称 /上传位置/

四.删除文件
hadoop fs -rm /文件名称

五.删除文件夹
hadoop fs -rm -r 文件夹名称

六.从HDFS中复制文件到本地
hadoop fs -get 文件名称

七.查询文件内容
hadoop fs -cat 文件名称

八.移动HDFS中的文件
hadoop fs -mv 文件位置以及要要移动的文件 移动后的位置

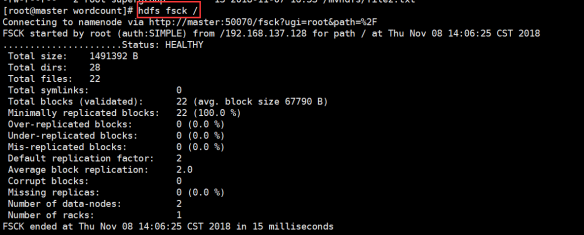
九.检查文件系统健康情况
hdfs fsck /

十.复制HDFS中的文件
hadoop fs -cp 要复制的文件位置以及文件 复制后的位置

十一.显示目录文件大小
hadoop fs -du 文件名称

如果是目录,则显示总大小

十二.清空回收站 (看不到结果)
hadoop fs -expunge

其他的命令:
hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
大数据Hadoop——HDFS Shell操作的更多相关文章
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...
- 我要进大厂之大数据Hadoop HDFS知识点(2)
01 我们一起学大数据 老刘继续分享出Hadoop中的HDFS模块的一些高级知识点,也算是对今天复习的HDFS内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点! ...
- 大数据 - hadoop - HDFS+Zookeeper实现高可用
高可用(Hign Availability,HA) 一.概念 作用:用于解决负载均衡和故障转移(Failover)问题. 问题描述:一个NameNode挂掉,如何启动另一个NameNode.怎样让两个 ...
- 大数据学习——hdfs客户端操作
package cn.itcast.hdfs; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configur ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
随机推荐
- Python从入坑到放弃!
Python基础 python基础 python基础之 while 逻辑运算符 格式化输出等 python基础之 基本数据类型,str方法和for循环 python基础之 列表,元组,字典 pyth ...
- 3.1.4 Spring的事务管理
四.Spring的事务管理 事务原本是数据库中的概念, 在Dao层. 但一般情况下, 需要将事务提升到 业务层, 即Service层. 这样做是为了 能够使用事务的特性来管理具体的业务. 1. Spr ...
- python 查找日志关键字
1.抓取出含有关键字”xiaoming”的行 2.在上一个问题的基础上,假设所在行的格式为location=xiaoming, value=xxx,请筛选出value值 #!/usr/bin/pyth ...
- http类中的download方法 下载汉字文件名 汉字消失的问题
将文件名用urlencode转码即可 $http = new \Org\Net\Http; $http->download($fileName, urlencode($showName));
- 表情的战争(App名称)技术服务支持
1.进入游戏走过场动画,可以点击退出跳过此过场动画: 2.进入主界面后直接点击开始游戏进入场景跑图,进入npc对话面板,对话结束进入战斗面板: 3.战斗操作方法为玩家拖动表情牌,进行攻击或者防守,直至 ...
- centos7 vmd-1.9.3安装
1. 下载安装包 安装包下载地址是http://www.ks.uiuc.edu/Research/vmd/,选择自己合适的版本,我下载1.9.3版本 2. 安装必要库 yum install free ...
- Leetcode: The Maze(Unsolved locked problem)
There is a ball in a maze with empty spaces and walls. The ball can go through empty spaces by rolli ...
- 551.学生出勤记录I
/* * @lc app=leetcode.cn id=551 lang=java * * [551] 学生出勤记录 I * * https://leetcode-cn.com/problems/st ...
- 【转】OJ提交时G++与C++的区别
关于G++ 首先更正一个概念,C++是一门计算机编程语言,G++不是语言,是一款编译器中编译C++程序的命令而已.那么他们之间的区别是什么? 在提交题目中的语言选项里,G++和C++都代表编译的方式. ...
- 记录心得-IntelliJ iDea 创建一个maven管理的的javaweb项目
熟能生巧,还是记录一下吧~ 开始! 第一步:File--New--Project--Maven--Create from archetype--maven-archetype-webapp 第二步:解 ...