Paper Read: Convolutional Image Captioning
Convolutional Image Captioning
2018-11-04 20:42:07
Code: https://github.com/aditya12agd5/convcap
Related Papers:
1. Convolutional Sequence to Sequence Learning Paper Code
常规的 image caption 的任务都是基于 CNN-LSTM 框架来实现的。因为其中有关于 language 的东西,一般采用 RNN 网络模型来处理句子。虽然在很多benchmark 上取得了惊人的效果,但是 LSTM 的训练是一个令人头大的问题。因为他的训练速度特别的慢。所以就有人考虑用 cnn 来处理句子编码的问题,首次提出这种思想的是 Facebook 组的工作。

本文将这种思路引入到 image caption 中,利用 卷积的思路来做这个 task,网络结构如下所示:

在次基础之上,提出了如下的 model:
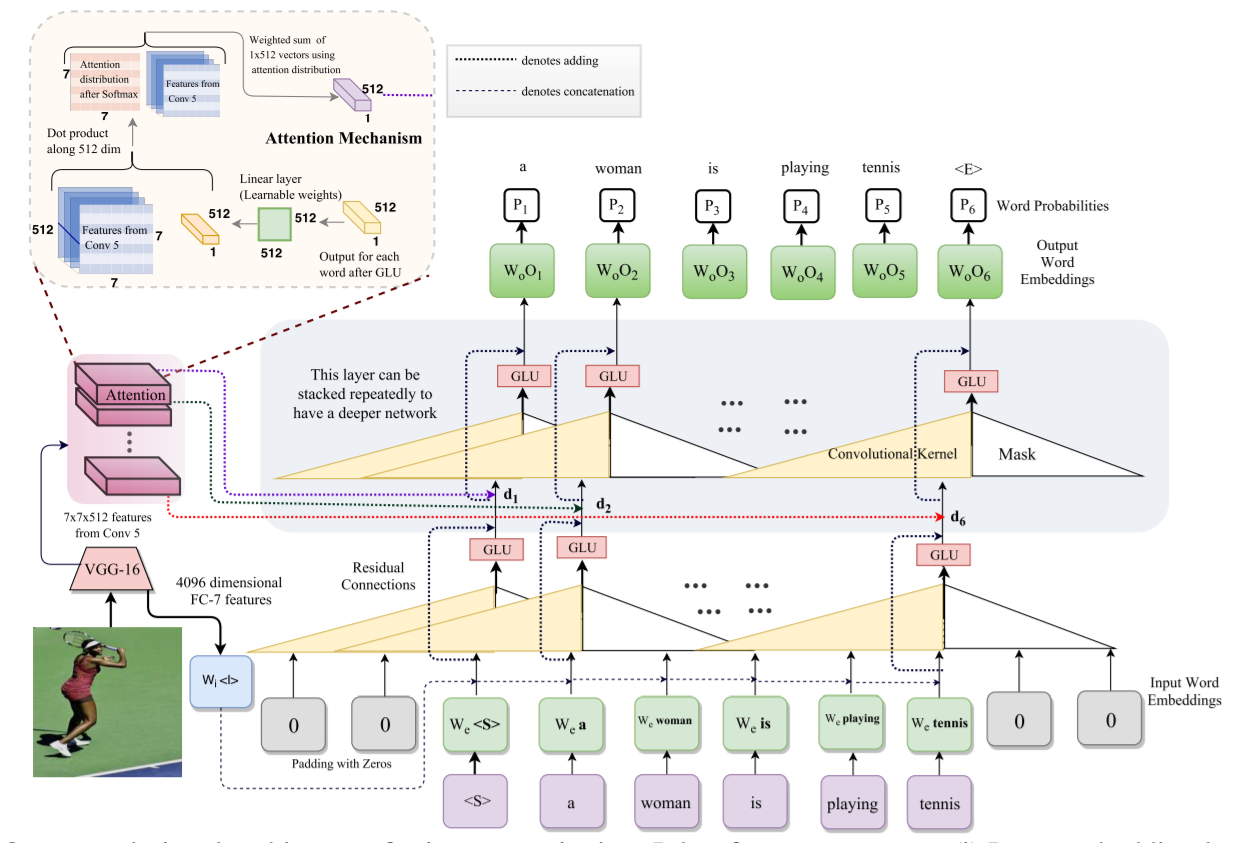
大致思路如下:
1. 首先对给定的句子进行填充(最大句子长度为 15,不足的就补 0),进行 embedding,得到对应的向量表示;
2. 然后用 1-D 的卷积,处理这些一维信号,得到 hidden state,然后输入到 GLU 激活函数当中,然后得到了 embedding 之后的向量;这里的 cnn layer 可以堆叠成多个 layer,以达到 deeper 的效果;
本文模型用了三层该网络;并且用了残差链接,以得到更好的效果;
3. 与此同时,作者用 CNN 提取图像的特征,将图像的特征与文本进行 attention 的计算,得到加权之后的 feature;以得到更好地效果;
4. 然后利用最大化后验概率的方式,给定当前输入,来预测下一个单词是什么。训练采用 Binary Cross-Entropy Loss 来进行。
其中的细节:

1. Attention 的计算(利用 Word embedding 对 visual feature map 进行 attention 计算):
作者提取 VGG 中 Conv-5 的特征,此时 feature map 的大小为:7*7*512,而 language 中 Word 进行 embedding 后,每一个单词的大小为:512-D。
于是,利用 show,attend and tell 那篇 image caption 文章的 soft-attention 思想,作者也将 text 和 visual feature 进行对齐操作,即:
首先将 512*1 的 vector 的转置,与可学习的权重 512*512 的 weight W,进行相乘,得到 512-D 的向量,然后将该向量与 feature map 上每一个位置上的 channel feature (1*512 D feature)进行点乘,得到一个 512-D 的 feature,于是,w*h 那么大的 feature map,就可以得到一个 w*h 的 权重分布图,即本文中的 7*7 的 attention distribution。用这个权重 和 每一个 channel 的 feature 进行点乘,相加,得到 512*1-D 的特征。
==
Paper Read: Convolutional Image Captioning的更多相关文章
- Paper Reading - Convolutional Image Captioning ( CVPR 2018 )
Link of the Paper: https://arxiv.org/abs/1711.09151 Motivation: LSTM units are complex and inherentl ...
- Paper Reading - Convolutional Sequence to Sequence Learning ( CoRR 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1705.03122 Motivation: Compared to recurrent layers, convol ...
- Paper | U-Net: Convolutional Networks for Biomedical Image Segmentation
目录 故事背景 U-Net 具体结构 损失 数据扩充 发表在2015 MICCAI.原本是一篇医学图像分割的论文,但由于U-Net杰出的网络设计,得到了8k+的引用. 摘要 There is larg ...
- 读paper:Deep Convolutional Neural Network using Triplets of Faces, Deep Ensemble, andScore-level Fusion for Face Recognition
今天给大家带来一篇来自CVPR 2017关于人脸识别的文章. 文章题目:Deep Convolutional Neural Network using Triplets of Faces, Deep ...
- Paper | Toward Convolutional Blind Denoising of Real Photographs
目录 故事背景 建模现实噪声 CBDNet 非对称损失 数据库 实验 发表在2019 CVPR. 摘要 While deep convolutional neural networks (CNNs) ...
- Paper | Learning convolutional networks for content-weighted image compression
目录 摘要 故事要点 模型训练 发表在2018年CVPR. 以下对于一些专业术语的翻译可能有些问题. 摘要 有损压缩是一个优化问题,其优化目标是率失真,优化对象是编码器.量化器和解码器(同时优化). ...
- [ Continuously Update ] The Paper List of Image / Video Captioning
Papers Published in 2018 Convolutional Image Captioning - Jyoti Aneja et al., CVPR 2018 - [ Paper Re ...
- Image Captioning 经典论文合辑
Image Caption: Automatically describing the content of an image domain:CV+NLP Category:(by myself, y ...
- ( 转) Awesome Image Captioning
Awesome Image Captioning 2018-12-03 19:19:56 From: https://github.com/zhjohnchan/awesome-image-capti ...
随机推荐
- 我的WafBypass之道(Misc篇)
先知技术社区独家发表本文,如需要转载,请先联系先知技术社区授权:未经授权请勿转载.先知技术社区投稿邮箱:Aliyun_xianzhi#service.alibaba.com: Author:Tr3je ...
- 主流框架的搭建(VUE,React)
vue脚手架:cnpm install vue vue-cli -gvue init webpack/webpack-simple shuaige(新建文件夹的名字)cd shuaigecnpm in ...
- jq 点击按钮显示div,点击页面其他任何地方隐藏div
css .bl_rencai_32{ float: left; height: 35px; line-height: 35px; } .bl_rencai_32 >input{ width: 3 ...
- Python学习之旅(十三)
Python基础知识(12):函数(Ⅲ) 高阶函数 1.map map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterat ...
- WPS生成文章目录
WPS生成文章目录 1.引用–>插入目录...即可!
- jenkins和svn搭建自动代码构建发布
jenkins安装和配置 .安装jenkins .yum install java wget -O /etc/yum.repos.d/jenkins.repo https://pkg.jenkins. ...
- python框架之Django(5)-O/RM
字段&参数 字段与db类型的对应关系 字段 DB Type AutoField integer AUTO_INCREMENT BigAutoField bigint AUTO_INCREMEN ...
- 【LeetCode每天一题】Combinations(组合)
Given two integers n and k, return all possible combinations of k numbers out of 1 ... n. Example: I ...
- [ Build Tools ] Repositories
仓库介绍 http://hao.jobbole.com/central-repository/ https://my.oschina.net/pingjiangyetan/blog/423380 ht ...
- 221. Maximal Square(动态规划)
Given a 2D binary matrix filled with 0's and 1's, find the largest square containing only 1's and re ...