Spark进阶之路-日志服务器的配置
Spark进阶之路-日志服务器的配置
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
如果你还在纠结如果配置Spark独立模式(Standalone)集群,可以参考我之前分享的笔记:https://www.cnblogs.com/yinzhengjie/p/9379045.html 。然而本篇博客的重点是如何配置日志服务器,并将日志落地在hdfs上。
一.准备实验环境
1>.集群管理脚本
[yinzhengjie@s101 ~]$ more `which xcall.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -lt ];then
echo "请输入参数"
exit
fi #获取用户输入的命令
cmd=$@ for (( i=;i<=;i++ ))
do
#使终端变绿色
tput setaf
echo ============= s$i $cmd ============
#使终端变回原来的颜色,即白灰色
tput setaf
#远程执行命令
ssh s$i $cmd
#判断命令是否执行成功
if [ $? == ];then
echo "命令执行成功"
fi
done
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ more `which xcall.sh`
[yinzhengjie@s101 ~]$ more `which xrsync.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -lt ];then
echo "请输入参数";
exit
fi #获取文件路径
file=$@ #获取子路径
filename=`basename $file` #获取父路径
dirpath=`dirname $file` #获取完整路径
cd $dirpath
fullpath=`pwd -P` #同步文件到DataNode
for (( i=;i<=;i++ ))
do
#使终端变绿色
tput setaf
echo =========== s$i %file ===========
#使终端变回原来的颜色,即白灰色
tput setaf
#远程执行命令
rsync -lr $filename `whoami`@s$i:$fullpath
#判断命令是否执行成功
if [ $? == ];then
echo "命令执行成功"
fi
done
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ more `which xrsync.sh`
2>.开启hdfs分布式文件系统
[yinzhengjie@s101 ~]$ xcall.sh jps
============= s101 jps ============
DFSZKFailoverController
NameNode
Jps
命令执行成功
============= s102 jps ============
QuorumPeerMain
DataNode
Jps
JournalNode
命令执行成功
============= s103 jps ============
Jps
JournalNode
QuorumPeerMain
DataNode
命令执行成功
============= s104 jps ============
QuorumPeerMain
DataNode
Jps
JournalNode
命令执行成功
============= s105 jps ============
Jps
DFSZKFailoverController
NameNode
命令执行成功
[yinzhengjie@s101 ~]$
3>.检查服务是否开启成功
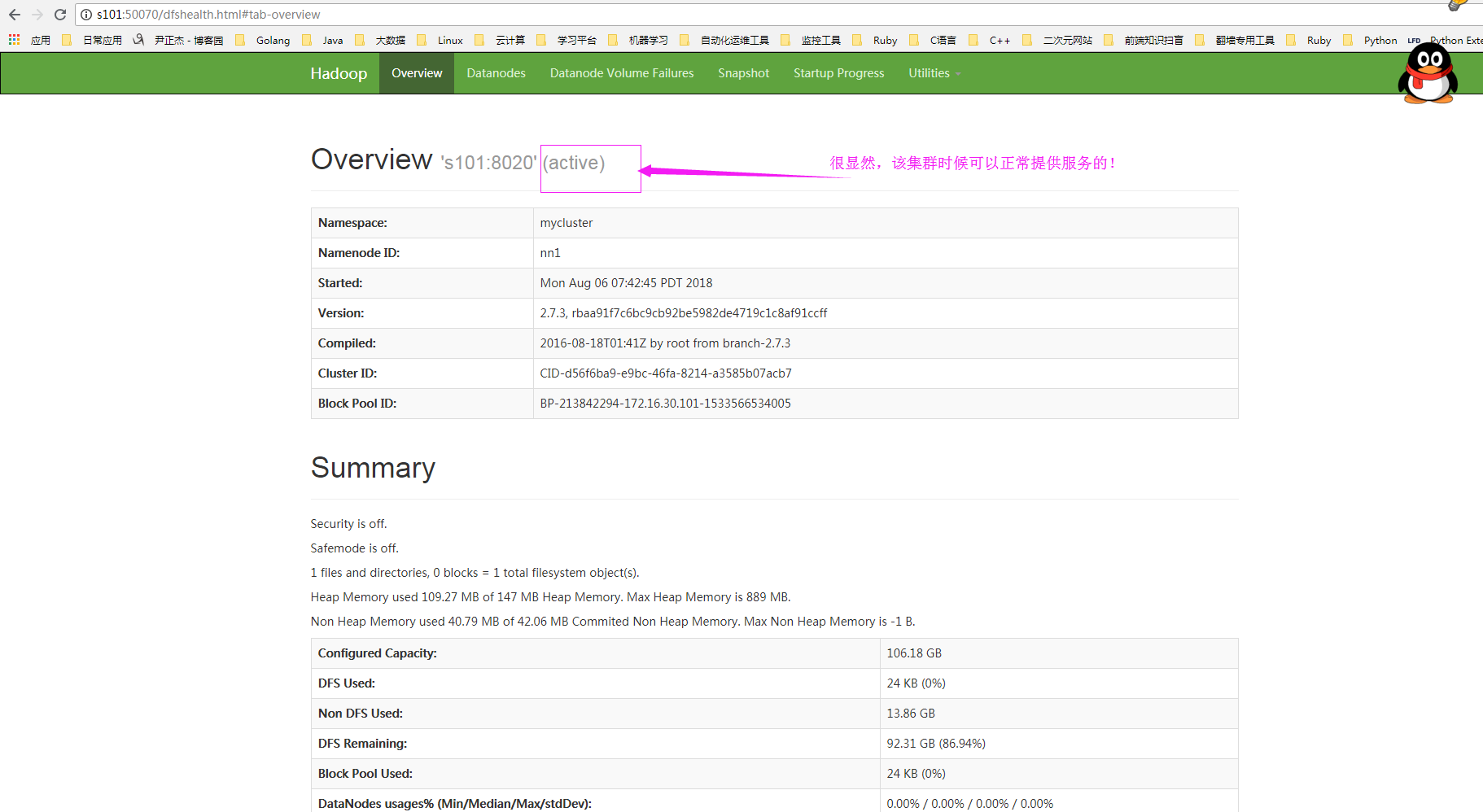
4>.在hdfs中创建指定目录用于存放日志文件
[yinzhengjie@s101 ~]$ hdfs dfs -mkdir -p /yinzhengjie/logs
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ hdfs dfs -ls -R /
drwxr-xr-x - yinzhengjie supergroup -- : /yinzhengjie
drwxr-xr-x - yinzhengjie supergroup -- : /yinzhengjie/logs
[yinzhengjie@s101 ~]$
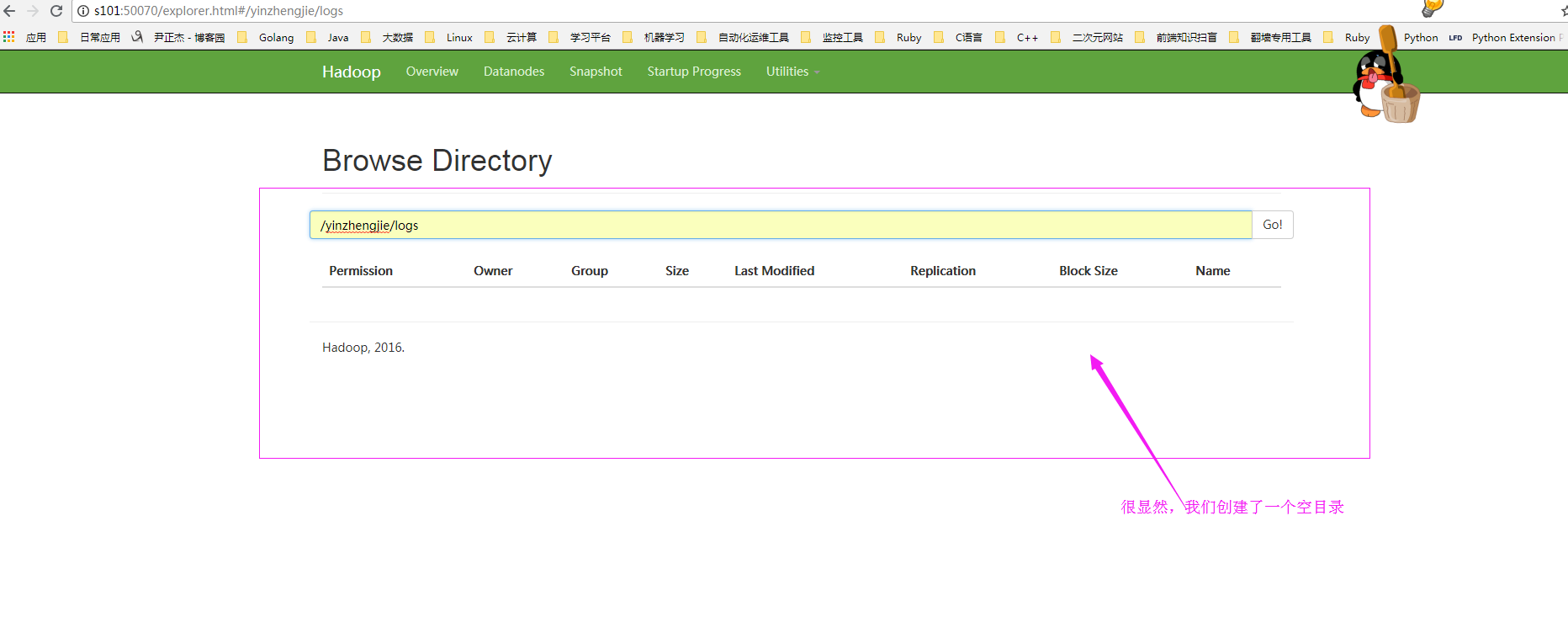
二.修改配置文件
1>.查看可用的hdfs的NameNode节点
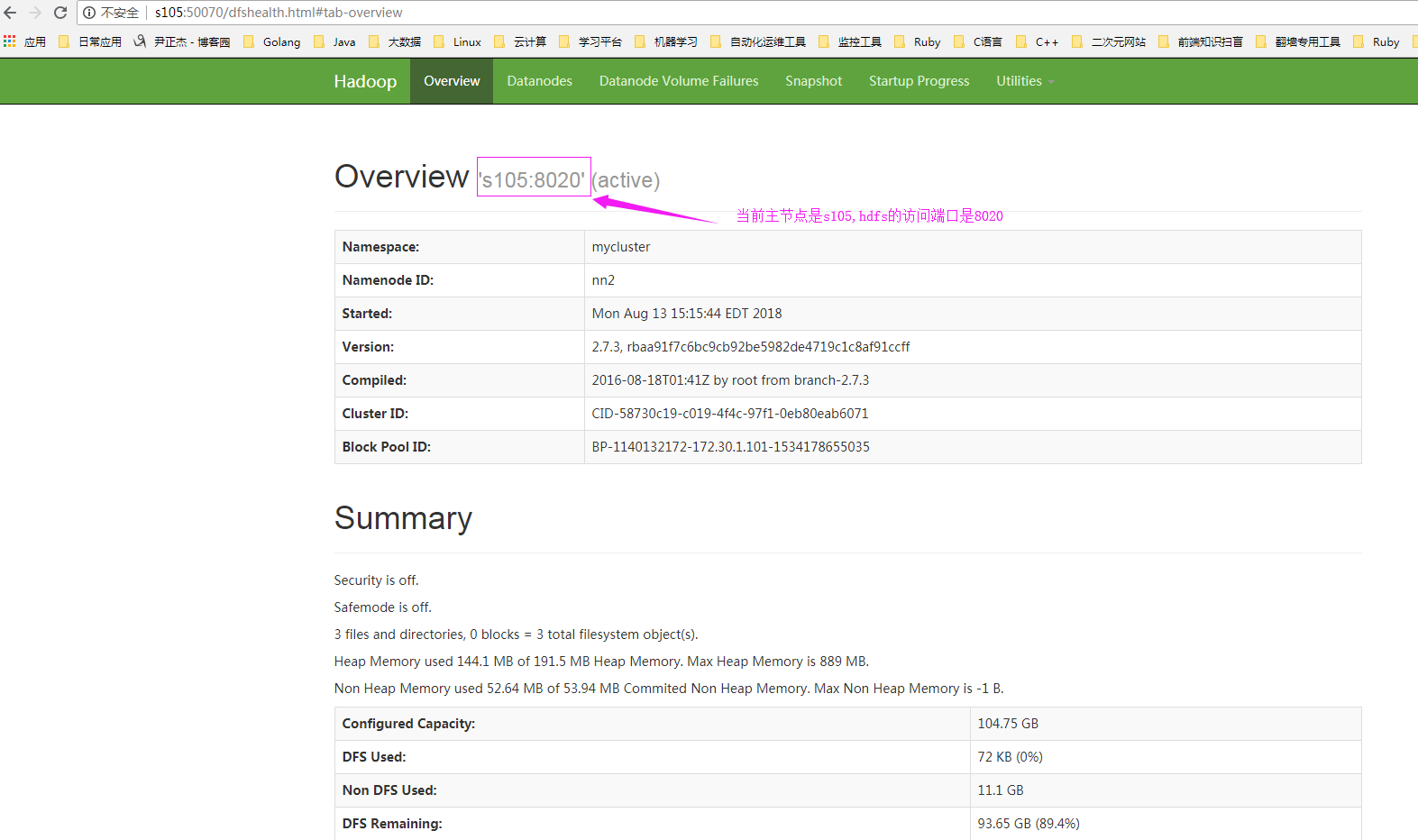
2>.开启log日志[温馨提示:HDFS上的目录需要提前存在
[yinzhengjie@s101 ~]$ cp /soft/spark/conf/spark-defaults.conf.template /soft/spark/conf/spark-defaults.conf
[yinzhengjie@s101 ~]$ echo "spark.eventLog.enabled true" >> /soft/spark/conf/spark-defaults.conf
[yinzhengjie@s101 ~]$ echo "spark.eventLog.dir hdfs://s105:8020/yinzhengjie/logs" >> /soft/spark/conf/spark-defaults.conf
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ cat /soft/spark/conf/spark-defaults.conf | grep -v ^# | grep -v ^$
spark.eventLog.enabled true #表示开启log功能
spark.eventLog.dir hdfs://s105:8020/yinzhengjie/logs #指定log存放的位置
[yinzhengjie@s101 ~]$
2>.修改spark-env.sh文件
[yinzhengjie@s101 ~]$ cat /soft/spark/conf/spark-env.sh | grep -v ^# | grep -v ^$
export JAVA_HOME=/soft/jdk
SPARK_MASTER_HOST=s101
SPARK_MASTER_PORT=
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://s105:8020/yinzhengjie/logs"
[yinzhengjie@s101 ~]$ 参数描述:
spark.eventLog.dir: #Application在运行过程中所有的信息均记录在该属性指定的路径下;
spark.history.ui.port= #调整WEBUI访问的端口号为4000
spark.history.fs.logDirectory= hdfs://s105:8020/yinzhengjie/logs #配置了该属性后,在start-history-server.sh时就无需再显式的指定路径,Spark History Server页面只展示该指定路径下的信息
spark.history.retainedApplications= #指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
3>.分发修改的spark-env.sh配置文件
[yinzhengjie@s101 ~]$ xrsync.sh /soft/spark-2.1.-bin-hadoop2./conf
=========== s102 %file ===========
命令执行成功
=========== s103 %file ===========
命令执行成功
=========== s104 %file ===========
命令执行成功
[yinzhengjie@s101 ~]$
三.启动日志服务器
1>.启动Spark集群
[yinzhengjie@s101 ~]$ /soft/spark/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.master.Master--s101.out
s104: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker--s104.out
s102: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker--s102.out
s103: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker--s103.out
[yinzhengjie@s101 ~]$ xcall.sh jps
============= s101 jps ============
Jps
NameNode
Master
DFSZKFailoverController
命令执行成功
============= s102 jps ============
QuorumPeerMain
DataNode
Worker
JournalNode
Jps
命令执行成功
============= s103 jps ============
QuorumPeerMain
Jps
DataNode
JournalNode
Worker
命令执行成功
============= s104 jps ============
Worker
JournalNode
Jps
QuorumPeerMain
DataNode
命令执行成功
============= s105 jps ============
NameNode
Jps
DFSZKFailoverController
命令执行成功
[yinzhengjie@s101 ~]$
2>.启动日志服务器
[yinzhengjie@s101 conf]$ start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.history.HistoryServer--s101.out
[yinzhengjie@s101 conf]$
3>.通过webUI访问日志服务器
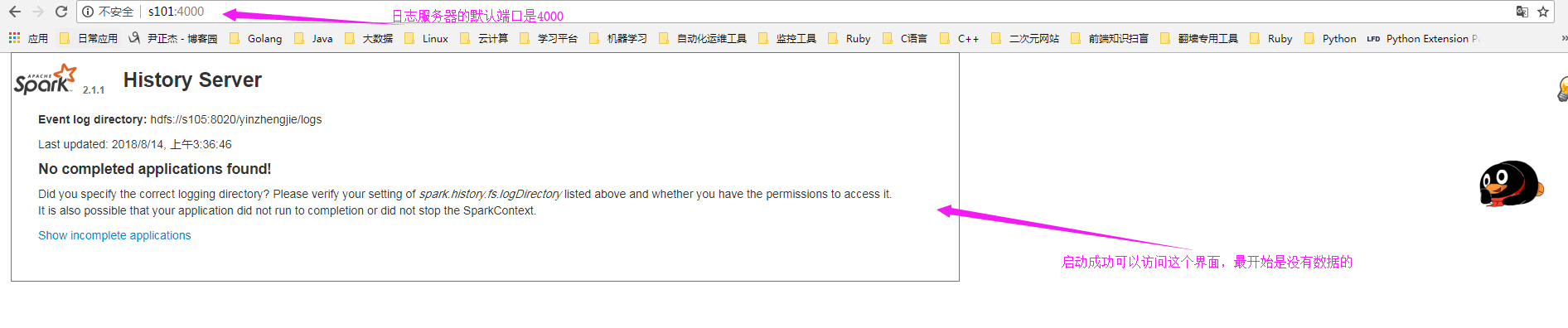
4>.运行Wordcount并退出程序([yinzhengjie@s101 ~]$ spark-shell --master spark://s101:7077)
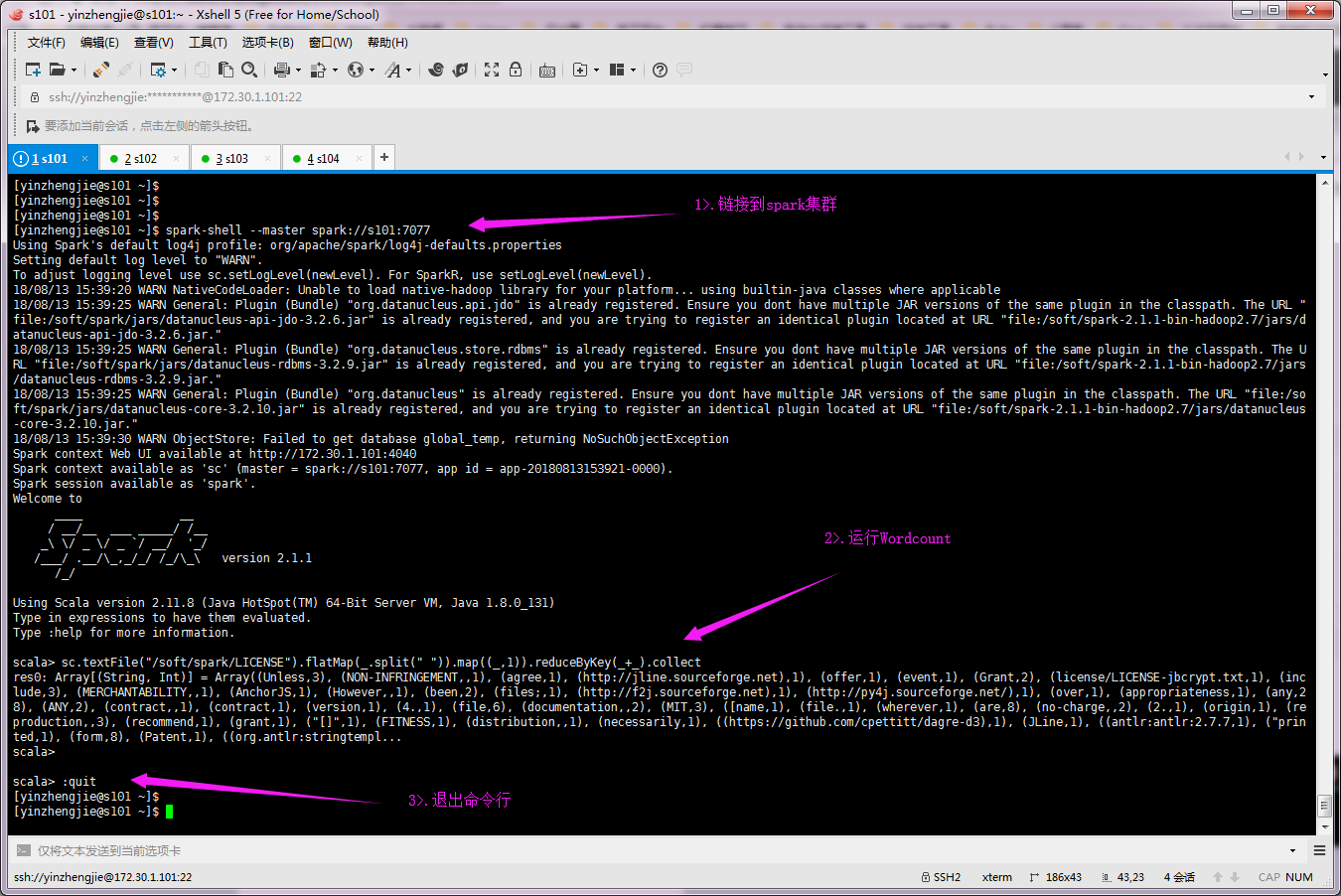
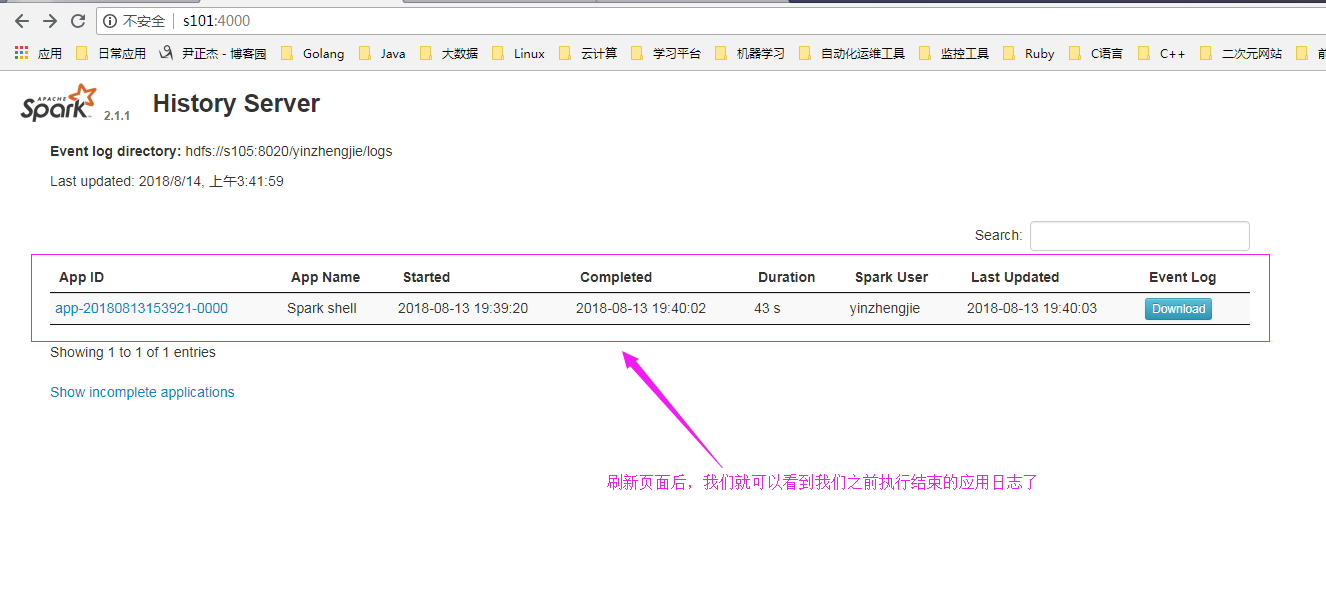
5>.再次查看日志服务器页面
Spark进阶之路-日志服务器的配置的更多相关文章
- Spark进阶之路-Spark HA配置
Spark进阶之路-Spark HA配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 集群部署完了,但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借 ...
- Spark进阶之路-Standalone模式搭建
Spark进阶之路-Standalone模式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark的集群的准备环境 1>.master节点信息(s101) 2&g ...
- 010 Spark中的监控----日志聚合的配置,以及REST Api
一:History日志聚合的配置 1.介绍 Spark的日志聚合功能不是standalone模式独享的,是所有运行模式下都会存在的情况 默认情况下历史日志是保存到tmp文件夹中的 2.参考官网的知识点 ...
- 树莓派进阶之路 (010) - 树莓派raspi-config配置(转)
经过前面两步我们的树莓派已经正常的工作起来了,但是在真正用它开发之前还需要进行一些列的配置以及软件的安装,这样开发起来才会得心应手,下面我们介绍一下常用的软件和服务 1.配置选项: 树莓派第一次使用的 ...
- Spark进阶之路-Spark提交Jar包执行
Spark进阶之路-Spark提交Jar包执行 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在实际开发中,使用spark-submit提交jar包是很常见的方式,因为用spark ...
- Linux配置日志服务器
title: Linux配置日志服务器 tags: linux, 日志服务器 --- Linux配置日志服务器 日志服务器配置文件:/etc/rsyslog.conf 服务器端: 服务器IP如下: 编 ...
- CentOS7.3下部署Rsyslog+LogAnalyzer+MySQL中央日志服务器
一.简介 1.LogAnalyzer 是一款syslog日志和其他网络事件数据的Web前端.它提供了对日志的简单浏览.搜索.基本分析和一些图表报告的功能.数据可以从数据库或一般的syslog文本文件中 ...
- 搭建rsyslog日志服务器
环境配置 centos7系统 client1:192.168.91.17 centos7系统 master:192.168.91.18 rsyslog客户端配置 1.rsyslog安装 yum ins ...
- Scala进阶之路-Spark独立模式(Standalone)集群部署
Scala进阶之路-Spark独立模式(Standalone)集群部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道Hadoop解决了大数据的存储和计算,存储使用HDFS ...
随机推荐
- 使用代理创建连接池 proxyPool
配置文件properties url=jdbc:mysql://127.0.0.1:3306/mine?characterEncoding=UTF-8 user=root password=1234 ...
- 关于五子棋游戏java版
一 题目简介:关于五子棋游戏 二 源码的github链接 https://github.com/marry1234/test/blob/master/五子棋游戏 三.所设计的模块测试用例.测试结果 ...
- 第三个sprint冲刺第一阶段
- ios开发之--CAKeyframeAnimation的详细用法
简单的创建一个带路径的动画效果,比较粗糙,不过事先原理都是一样的, 代码如下: 1,创建动画所需的view -(void)creatView { moveView = [UIView new]; mo ...
- [日常工作] SUSE设置上网ip地址
1. 同事搜到的命令 ifconfig eth0 10.24.25.8 netmask 255.255.0.0 up route add default gw 10.24.255.254 2. 修改 ...
- [工作相关] GS产品使用LInux下Oracle数据库以及ASM存储时的数据文件路径写法.
1. 自从公司的GS5版本就已经支持Linux下的oracle数据库通过安装工具自动安装注册了, 只不过路径需要使用linux的命名规则, 如图: /home/oracle/ 注意 最后是有一个 斜线 ...
- ADODataSet与ADOQuery的区别
ADODataSet组件 此组件功能是非常强大的,通过ADODataset,可以直接与一个表进行联接,也可以执行SQL语句,还可以执行存储过程,可以说集ADOTable. ADOQuery. A ...
- js對象構造
創建對象的3種方式: 1. var a=new Object() a.attributes=“1”: 2. var a={attributes:"1",aa:"2&quo ...
- 洛谷P2698 [USACO12MAR]花盆Flowerpot
P2698 [USACO12MAR]花盆Flowerpot 题目描述 Farmer John has been having trouble making his plants grow, and n ...
- day31 作业试题讲解
#__author__: Administrator #__date__: 2018/8/8 # 基础知识 # 1.文件操作有哪些模式?简述作用 # r w a 至少你要说出这三个 # rb wb a ...