leveldb 学习记录(一) skiplist
leveldb
LevelDb是一个持久化存储的KV系统,并非完全将数据放置于内存中,部分数据也会存储到磁盘上。
想了解这个由谷歌大神编写的经典项目.
可以从数据结构以及数据结构的处理下手,也可以从示例的某一点深入跟进系统,查看处理流程.
windows下编译leveldb 地址 leveldb 源码编译 vs版本
目前手头资料中,源码中的文档以及网络的代码分析心得如下,本文也做了参考,感谢作者.
流程类
结构入手类
1 arena内存池略过。 nginx内存池 stl内存池均可参考实现原理(《stl源码分析》)
2 bloomfilter相当于多重哈希,比对哈希值判断是否有相同元素插入 略过。
3 数据结构skiplist 多数操作log(n)
参考 https://segmentfault.com/a/1190000003051117
跳表的关键点在于定义和查找方法
定义如下:
SkipList的定义:
1. 一个跳表应该有几个层(level)组成;
2. 跳表的第一层包含所有的元素;
3. 每一层都是一个有序的链表;
4. 如果元素x出现在第i层,则所有比i小的层都包含x;
5. 第i层的元素通过一个down指针指向下一层拥有相同值的元素;
6. 在每一层中,-1和1两个元素都出现(分别表示INT_MIN和INT_MAX);
7. Top指针指向最高层的第一个元素。
图示:
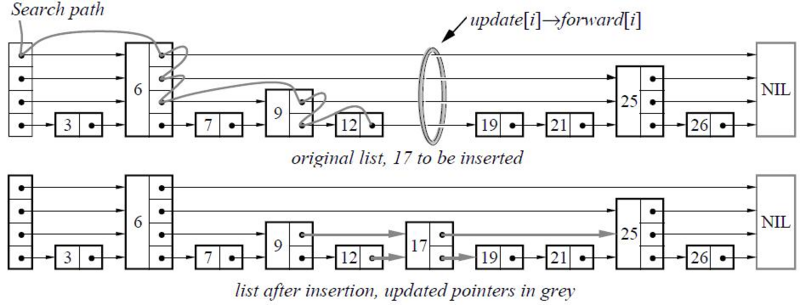
find
查找方法为
1 起点为最高层第一个元素 若元素小于查找值 则查找该元素的后继值
2 若元素大于查找值 则降低层级再次查找
3 若该元素的后继值 为NULL或者大于该值 ,则降低层数再次查找
4 直到查找成功或者达到表的最底层且无元素可查找
图示中查找 17
起点为最高层第一个元素 6 6<17 6的下一个元素为null 则在元素6中降低层级
再次查找6的下一个元素 是25 降低层级
再次查找6的下一个元素 是9
再次查找9的下一个元素 是25 降低层级
再次查找9的下一个元素 是12
再次查找12的下一个元素 是19 此处为最低层级 则未查找到(进行插入)
insert
查找也可用于insert 注意insert 元素时候层级是随机的
leveldb 中skiplist 结构如下(内存池与原子指针等结构暂时不予理会)
template<typename Key, class Comparator>
struct SkipList<Key,Comparator>::Node {
explicit Node(const Key& k) : key(k) { } Key const key; // Accessors/mutators for links. Wrapped in methods so we can
// add the appropriate barriers as necessary.
Node* Next(int n) {
assert(n >= );
// Use an 'acquire load' so that we observe a fully initialized
// version of the returned Node.
return reinterpret_cast<Node*>(next_[n].Acquire_Load());
}
void SetNext(int n, Node* x) {
assert(n >= );
// Use a 'release store' so that anybody who reads through this
// pointer observes a fully initialized version of the inserted node.
next_[n].Release_Store(x);
} // No-barrier variants that can be safely used in a few locations.
Node* NoBarrier_Next(int n) {
assert(n >= );
return reinterpret_cast<Node*>(next_[n].NoBarrier_Load());
}
void NoBarrier_SetNext(int n, Node* x) {
assert(n >= );
next_[n].NoBarrier_Store(x);
} private:
// Array of length equal to the node height. next_[0] is lowest level link.
port::AtomicPointer next_[];
}; template<typename Key, class Comparator>
typename SkipList<Key,Comparator>::Node*
SkipList<Key,Comparator>::NewNode(const Key& key, int height) {
char* mem = arena_->AllocateAligned(
sizeof(Node) + sizeof(port::AtomicPointer) * (height - ));
return new (mem) Node(key);
}
抛开内存池和多线程情况下的原子操作 定义很简单
分配 获取下一个元素 设置下一个元素
template<typename Key, class Comparator>中的 key是元素类型 Comparator是元素比较大小的策略
元素插入操作如下
template<typename Key, class Comparator>
void SkipList<Key,Comparator>::Insert(const Key& key) {
// TODO(opt): We can use a barrier-free variant of FindGreaterOrEqual()
// here since Insert() is externally synchronized.
Node* prev[kMaxHeight];
Node* x = FindGreaterOrEqual(key, prev); assert(x == NULL || !Equal(key, x->key)); int height = RandomHeight();
if (height > GetMaxHeight()) {
for (int i = GetMaxHeight(); i < height; i++) {
prev[i] = head_;
}
//fprintf(stderr, "Change height from %d to %d\n", max_height_, height); // It is ok to mutate max_height_ without any synchronization
// with concurrent readers. A concurrent reader that observes
// the new value of max_height_ will see either the old value of
// new level pointers from head_ (NULL), or a new value set in
// the loop below. In the former case the reader will
// immediately drop to the next level since NULL sorts after all
// keys. In the latter case the reader will use the new node.
max_height_.NoBarrier_Store(reinterpret_cast<void*>(height));
} x = NewNode(key, height);
for (int i = ; i < height; i++) {
// NoBarrier_SetNext() suffices since we will add a barrier when
// we publish a pointer to "x" in prev[i].
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i));
prev[i]->SetNext(i, x);
}
}
插入元素的层级是随机的 并且获取当前最大层级数并未使用原子操作 因为根据逻辑并无影响 不使用原子操作也是性能上的一种考虑
元素读取操作如下
template<typename Key, class Comparator>
typename SkipList<Key,Comparator>::Node* SkipList<Key,Comparator>::FindGreaterOrEqual(const Key& key, Node** prev)
const {
Node* x = head_;
int level = GetMaxHeight() - ;
while (true) {
Node* next = x->Next(level);
if (KeyIsAfterNode(key, next)) {
// Keep searching in this list
x = next;
} else {
if (prev != NULL) prev[level] = x;
if (level == ) {
return next;
} else {
// Switch to next list
level--;
}
}
}
}
find
查找方法为
1 起点为最高层第一个元素 若元素小于查找值 则查找该元素的后继值
2 若元素大于查找值 则降低层级再次查找
3 若该元素的后继值 为NULL或者大于该值 ,则降低层数再次查找
4 直到查找成功或者达到表的最底层且无元素可查找
图示中查找 17
起点为最高层第一个元素 6 6<17 6的下一个元素为null 则在元素6中降低层级
再次查找6的下一个元素 是25 降低层级
再次查找6的下一个元素 是9
再次查找9的下一个元素 是25 降低层级
再次查找9的下一个元素 是12
再次查找12的下一个元素 是19 此处为最低层级 则未查找到(进行插入)
leveldb 学习记录(一) skiplist的更多相关文章
- leveldb 学习记录(四) skiplist补与变长数字
在leveldb 学习记录(一) skiplist 已经将skiplist的插入 查找等操作流程用图示说明 这里在介绍 下skiplist的代码 里面有几个模块 template<typenam ...
- leveldb 学习记录(三) MemTable 与 Immutable Memtable
前文: leveldb 学习记录(一) skiplist leveldb 学习记录(二) Slice 存储格式: leveldb数据在内存中以 Memtable存储(核心结构是skiplist 已介绍 ...
- leveldb 学习记录(四)Log文件
前文记录 leveldb 学习记录(一) skiplistleveldb 学习记录(二) Sliceleveldb 学习记录(三) MemTable 与 Immutable Memtablelevel ...
- leveldb 学习记录(五)SSTable格式介绍
本节主要记录SSTable的结构 为下一步代码阅读打好基础,考虑到已经有大量优秀博客解析透彻 就不再编写了 这里推荐 https://blog.csdn.net/tankles/article/det ...
- leveldb 学习记录(七) SSTable构造
使用TableBuilder构造一个Table struct TableBuilder::Rep { // TableBuilder内部使用的结构,记录当前的一些状态等 Options options ...
- leveldb 学习记录(八) compact
随着运行时间的增加,memtable会慢慢 转化成 sstable. sstable会越来越多 我们就需要进行整合 compact 代码会在写入查询key值 db写入时等多出位置调用MaybeSche ...
- leveldb 学习记录(二) Slice
基本每个KV库都有一个简洁的字符串管理类 比如redis的sds 比如leveldb的slice 管理一个字符串指针和数据长度 通过对字符串指针 长度的管理实现一般的创建 判断是否为空 获取第N个位 ...
- leveldb 学习记录(六)SSTable:Block操作
block结构示意图 sstable中Block 头文件如下: class Block { public: // Initialize the block with the specified con ...
- LevelDB学习笔记 (3): 长文解析memtable、跳表和内存池Arena
LevelDB学习笔记 (3): 长文解析memtable.跳表和内存池Arena 1. MemTable的基本信息 我们前面说过leveldb的所有数据都会先写入memtable中,在leveldb ...
随机推荐
- Maven项目构建过程练习
转载于:http://www.cnblogs.com/xdp-gacl/p/4051690.html 上一篇只是简单介绍了一下maven入门的一些相关知识,这一篇主要是体验一下Maven高度自动化构建 ...
- Vista的MBR磁盘签名(Disk Signature) (转帖)
原帖:Vista的MBR磁盘签名(Disk Signature)_存梦_新浪博客 http://blog.sina.com.cn/s/blog_6fed14220100qq71.html 存梦发表于( ...
- Bootstrap 插件收集
Bootstrap-Mutilselect 将下拉选项扩展支持多选以及多种选择方式 http://davidstutz.de/bootstrap-multiselect/ Bootstrap Sel ...
- 导出Excel(Ext 前台部分)
开发思路: - 序列化当前GridPanel 数据, 表头结构(用于对应关系), 通过控制器Aspose写到Excel中, 然后返回临时文件地址, 弹出窗口下载. function btnExport ...
- atop 分析小记
atop分析小记 atop这个工具相当NB 项目中需要用到它的磁盘使用率统计值,为了一探究竟,挖了下它的代码 atopsar atopsar实际就是atop的一个链接指向. 从atop.c的main源 ...
- json null
{ "ResourceId": 0, "JsonKey": "Account", "GroupId": 21, &quo ...
- 团队第三次 # scrum meeting
github 本此会议项目由PM召开,召开时间为4-7日晚上9点 召开时长15分钟 任务表格 袁勤 继续学习SpringBoot https://github.com/buaa-2016/phyweb ...
- mysql相关碎碎念
取得当天: SELECT curdate(); mysql> SELECT curdate();+------------+| curdate() |+------------+| 2013- ...
- python——元组和字典类型简明理解
元组类型: 元祖创建: 不需要括号可以但是一个元素就当成了字符串类型了 >>> tup1="a"; >>> type(tup1) <cla ...
- nginx的一次工作记录
upstream fazhi_ui{ server ; } upstream fazhi_api{ server ; } server { listen ; server_name localhost ...