python编码及转换

第一种:ASCII码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。如下图所示:

由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母 A的编码是65,小写字母 a的编码是97。后128个称为扩展ASCII码。
每一位0或者1所占的空间单位为bit(比特),这是计算机中最小的表示单位,每8个bit组成一个字符,这是计算机中最小的存储单位。
常见换算单位:
bit 位,计算机中最小的表示单位
8bit = 1bytes 字节,最小的存储单位,1bytes缩写为1B
1KB=1024B
1MB=1024KB
1GB=1024MB
1TB=1024GB
第二种:GBK 和 GB2312
对于我们来说能在计算机中显示中文字符是至关重要的,然而ASCII表里连一个偏旁部首也没有。所以我们还需要一张关于中文和数字对应的关系表。一个字节只能最多表示256个字符,要处理中文显然一个字节是不够的,所以我们需要采用两个字节来表示,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
第三种:Unicode
但如以来,就会出现一个问题,各个国家都一套自己的编码,就不可避免会有冲突,这是该怎么办呢?
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,分析一下ASCII编码和Unicode编码的区别:
ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000;
汉字“中”已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
但如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
第四种:UTF-8
基于节约的原则,出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间了。如下所示:

从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
我们总结一下现在计算机系统通用的字符编码工作方式:
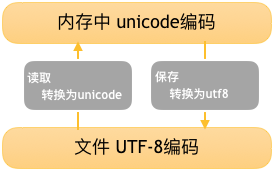
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。如下图:
三 编 码
ascii:字母,数字,特殊字符。没有中文。一个字节一个字符。 2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
万国码:
unicode :
A: 0000 0010 0000 0010 两个字节,表示一个字符。
中: 0000 0010 0000 0010 两个字节,表示一个字符。 升级:
A: 0000 0010 0000 0010 0000 0010 0000 0010 四个字节,表示一个字符。
中: 0000 0010 0000 0010 0000 0010 0000 0010 四个字节,表示一个字符。
缺点: 占空间,浪费资源。 utf-8:最少用一个字节,表示一个字符.
A: 0000 0010
欧洲:0000 00100000 0010
中文:0000 0010 0000 0010 0000 0010 gbk国标:
A: 0000 0010
中: 0000 0010 0000 0010
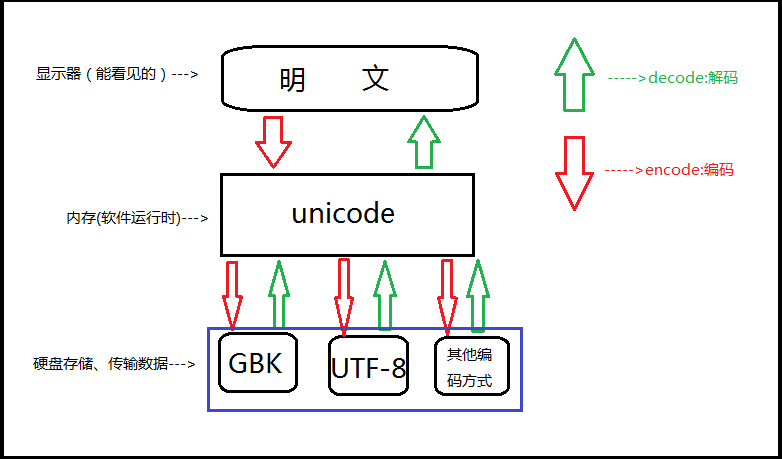
四 编码转换
UTF-8 --> decode 解码 --> UnicodeUnicode--> encode 编码 --> GBK / UTF-8/bytes GBK与utf-8 不能直接转换 例如:

#!/usr/bin/env python3
#-*- coding:utf-8 -*-
# write by congcong s = '匆匆'
print(s)
s1 = s.decode("utf-8") # utf-8 转成 Unicode,decode(解码)需要注明当前编码格式
print(s1,type(s1)) s2 = s1.encode("gbk") # unicode 转成 gbk,encode(编码)需要注明生成的编码格式
print(s2,type(s2)) s3 = s1.encode("utf-8") # unicode 转成 utf-8,encode(编码)注明生成的编码格式
print(s3,type(s3))
规则如下:
python3 文件默认编码是utf-8 , 字符串编码是 unicode
以utf-8 或者 gbk等编码的代码,加载到内存,会自动转为unicode正常显示。 python2 文件默认编码是ascii , 字符串编码也是 ascii , 如果文件头声明了是gbk,那字符串编码就是gbk。
以utf-8 或者 gbk等编码的代码,加载到内存,并不会转为unicode,编码仍然是utf-8或者gbk等编码。
python编码及转换的更多相关文章
- python 编码转换(转)
主要介绍了python的编码机制,unicode, utf-8, utf-16, GBK, GB2312,ISO-8859-1 等编码之间的转换. 常见的编码转换分为以下几种情况: 自动识别 字符串编 ...
- Python判断字符串编码以及编码的转换
转自:http://www.cnblogs.com/zhanhg/p/4392089.html Python判断字符串编码以及编码的转换 判断字符串编码: 使用 chardet 可以很方便的实现字符串 ...
- Python基础之 一 字符编码及转换
python2 / python3编码转换 先上图一张: 说明:python编码转换的流程是 先进行decode解码,然后进行encode编码 解释: u'你好' -->带u表示为unicod ...
- python 编码转换 专题
主要介绍了python的编码机制,unicode, utf-8, utf-16, GBK, GB2312,ISO-8859-1 等编码之间的转换. 常见的编码转换分为以下几种情况: 自动识别 字符串编 ...
- Python 编码转换与中文处理
python 中的 unicode是让人很困惑.比较难以理解的问题. 这篇文章 写的比较好,utf-8是 unicode的一种实现方式,unicode.gbk.gb2312是编码字符集. py文件中的 ...
- python编码转换
Pyton内部的字符串一般都是unicode编码或字节字符串编码:代码中字符串的默认编码与代码文件本身的编码是一致的:编码转换通常需要以unicode编码作为中间编码进行转换,即先将其他编码的字符串解 ...
- (转载) 浅谈python编码处理
最近业务中需要用 Python 写一些脚本.尽管脚本的交互只是命令行 + 日志输出,但是为了让界面友好些,我还是决定用中文输出日志信息. 很快,我就遇到了异常: UnicodeEncodeError: ...
- Python 编码简单说
先说说什么是编码. 编码(encoding)就是把一个字符映射到计算机底层使用的二进制码.编码方案(encoding scheme)规定了字符串是如何编码的. python编码,其实就是对python ...
- Python之路3【知识点】白话Python编码和文件操作
Python文件头部模板 先说个小知识点:如何在创建文件的时候自动添加文件的头部信息! 通过:file--settings 每次都通过file--setings打开设置页面太麻烦了!可以通过:View ...
随机推荐
- Java的反射机制的详细应用
package com.at221; import java.io.Serializable; import java.lang.reflect.*; import org.junit.Test; p ...
- codeforces 982B Bus of Characters
题意: 有n排座位,每排有两个座位,每排座位的宽度都不一样. 有2 * n个人要上车,如果是内向的人,那么它会选择一排两个都是空位并且宽度最小的一排去坐: 如果是外向的人,会选择一排座位已经有人坐的, ...
- xml 和 json 序列化忽略字段
xml 和 json 序列化忽略字段: @JsonIgnore @XmlTransient
- 解决mysql中文乱码问题?
mysql是我们项目中非常常用的数据型数据库.但是因为我们需要在数据库保存中文字符,所以经常遇到数据库乱码情况.下面就来介绍一下如何彻底解决数据库中文乱码情况. 1.中文乱码 1.1.中文乱码 cre ...
- Beaglebone板子修改usb连接时的默认IP192.168.0.2
首先除了有个USB线外,你还需要一个USB转串口的线(目的是防止修改错误,无法使用原来的usb的IP地址登陆,心大的可以跳过这步直接进入重点),串口线连接方法如下图: 将USB以及串口和PC机相连 ...
- Vue基础进阶 之 常用的实例属性
Vue实例属性: vue实例直接调用的属性: 常用的实例属性: vm.$data:获取属性: vm.$el:获取实例挂载的元素: vm.$options:获取自定义选项/属性: vm.$refs:获取 ...
- kernel: INFO: task sadc:14833 blocked for more than 120 seconds.
早上一到,发现oracle连不上. 到主机上,发现只有oracleora11g一个进程,其他进程全没了. Nov 14 23:33:30 hs-test-10-20-30-15 kernel: INF ...
- ogg跳过某个RBA
1.从库复制进程报如下错误 ************************************************************************* ...
- C#使用NPOI导出Excel
当记录数超出65536时,有两种方式处理: 一是调用WriteToDownLoad65536方法建立多个Excel. 二是调用WriteToDownLoad方法在同一个Excel中建多个Sheet. ...
- bzoj2091: [Poi2010]The Minima Game DP
2091: [Poi2010]The Minima Game DP 链接 https://www.lydsy.com/JudgeOnline/problem.php?id=2091 思路 这类问题好迷 ...