PyCharm搭建Spark开发环境 + 第一个pyspark程序
一, PyCharm搭建Spark开发环境
Windows7, Java 1.8.0_74, Scala 2.12.6, Spark 2.2.1, Hadoop 2.7.6
通常情况下,Spark开发是基于Linux集群的,但这里作为初学者并且囊中羞涩,还是在windows环境下先学习吧。
参照这个配置本地的Spark环境。
之后就是配置PyCharm用来开发Spark。本人在这里浪费了不少时间,因为百度出来的无非就以下两种方式:
1. 在程序中设置环境变量
import os
import sys os.environ['SPARK_HOME'] = 'C:\xxx\spark-2.2.1-bin-hadoop2.7'
sys.path.append('C:\xxx\spark-2.2.1-bin-hadoop2.7\python')
2. 在Edit Configuration中添加环境变量

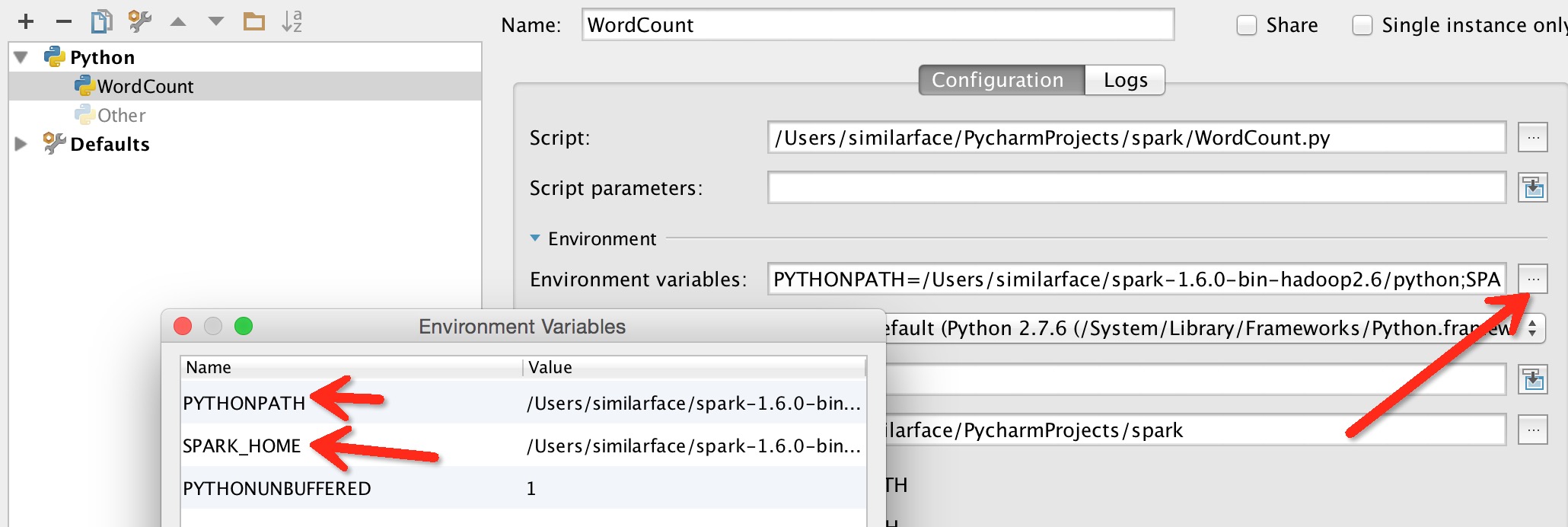
不过还是没有解决程序中代码自动补全。
想了半天,观察到spark提供的pyspark很像单独的安装包,应该可以考虑将pyspark包放到python的安装目录下,这样也就自动添加到之前所设置的python path里了,应该就能实现pyspark的代码补全提示。
将spark下的pyspark包放到python路径下(注意,不是spark下的python!)
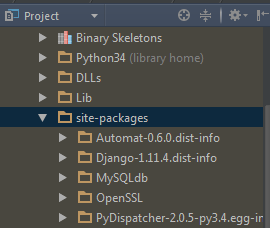
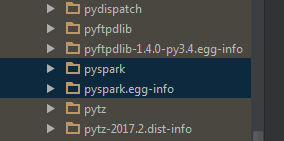
最后,实现了pyspark代码补全功能。
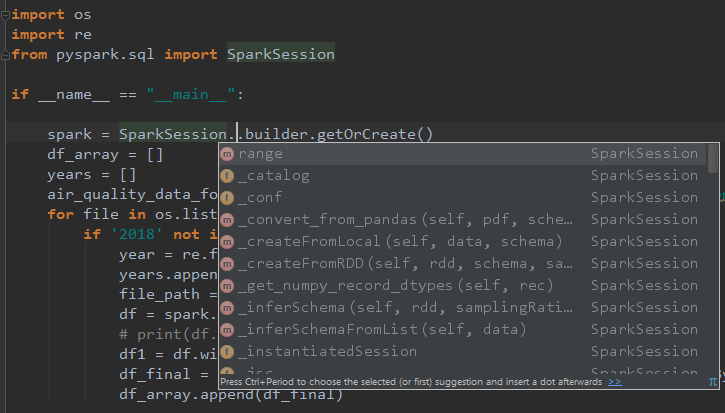
二. 第一个pyspark程序
作为小白,只能先简单用下python+pyspark了。
数据: Air Quality in Madrid (2001-2018)
需求: 根据历史数据统计出每个月平均指标值
import os
import re
from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession.builder.getOrCreate()
df_array = []
years = []
air_quality_data_folder = "C:/xxx/spark/air-quality-madrid/csvs_per_year"
for file in os.listdir(air_quality_data_folder):
if '' not in file:
year = re.findall("\d{4}", file)
years.append(year[0])
file_path = os.path.join(air_quality_data_folder, file)
df = spark.read.csv(file_path, header="true")
# print(df.columns)
df1 = df.withColumn('yyyymm', df['date'].substr(0, 7))
df_final = df1.filter(df1['yyyymm'].substr(0, 4) == year[0]).groupBy(df1['yyyymm']).agg({'PM10': 'avg'})
df_array.append(df_final) pm10_months = [0] * 12
# print(range(12))
for df in df_array:
for i in range(12):
rows = df.filter(df['yyyymm'].contains('-'+str(i+1).zfill(2))).first()
# print(rows[1])
pm10_months[i] += (rows[1]/12) years.sort()
print(years[0] + ' - ' + years[len(years)-1] + '年,每月平均PM10统计')
m_index = 1
for data in pm10_months:
print(str(m_index).zfill(2) + '月份: ' + '||' * round(data))
m_index += 1
运行结果:
2001 - 2017年,每月平均PM10统计
01月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
02月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
03月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
04月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
05月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
06月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
07月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
08月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
09月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
10月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
11月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
12月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
由以上统计结果,可以看出4月份的PM10最低。
Done!
PyCharm搭建Spark开发环境 + 第一个pyspark程序的更多相关文章
- Pycharm搭建Django开发环境
Pycharm搭建Django开发环境 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们大家都知道Django是python都一个web框架,因此大家需要自行安装python环境 ...
- PyCharm搭建pyqt5开发环境
PyCharm搭建PyQt5开发环境 1.安装PyQt5 2.PyCharm环境配置 2.1 添加QtDesigner 2.2 添加PyUIC 2.3 添加Pyrcc 2.4 添加assistant ...
- Intellij IDEA使用Maven搭建spark开发环境(scala)
如何一步一步地在Intellij IDEA使用Maven搭建spark开发环境,并基于scala编写简单的spark中wordcount实例. 1.准备工作 首先需要在你电脑上安装jdk和scala以 ...
- Intellij Idea搭建Spark开发环境
在Spark高速入门指南 – Spark安装与基础使用中介绍了Spark的安装与配置.在那里还介绍了使用spark-submit提交应用.只是不能使用vim来开发Spark应用.放着IDE的方便不用. ...
- 通过搭建一个精简的C语言开发环境了解一个C程序的执行过程
一.如何搭建一个精简的C语言开发环境 准备:下载TC2.0,并解压,比如说“d:\tc2.0\tc”目录 1.在C盘建立一个目录minic c:\ md minic 2.从解压的目录中将以下文件拷贝到 ...
- 服务器上搭建spark开发环境
1.安装相应的软件 (1)安装jdk 下载地址:http://www.Oracle.com/technetwork/java/javase/downloads/index.html (2)安装scal ...
- Spark(八) -- 使用Intellij Idea搭建Spark开发环境
Intellij Idea下载地址: 官方下载 选择右下角的Community Edition版本下载安装即可 本文中使用的是windows系统 环境为: jdk1.6.0_45 scala2.10. ...
- 大数据学习(25)—— 用IDEA搭建Spark开发环境
IDEA是一个优秀的Java IDE工具,它同样支持其他语言.Spark是用Scala语言编写的,用Scala开发Spark是最舒畅的.当然,Spark也提供Java和Python的API. Java ...
- spark学习10(win下利用Intellij IDEA搭建spark开发环境)
第一步:启动IntelliJ IDEA,选择Create New Project,然后选择Scala,点击下一步,输入项目名称wujiadong.spark继续下一步 第二步:导入spark-asse ...
随机推荐
- uva10857(状态压缩DP)
uva10857 题意 兔子希望在平面上 n 个点上放蛋,每个点最多放一个蛋,初始兔子在 (0, 0) 点,这里有无数个蛋,兔子可以回到这个点取蛋,兔子的速度为 \(v * 2^{-i}\)(i 为携 ...
- UVA 11396 Claw Decomposition 染色
原题链接:https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem ...
- [BZOJ4568][SCOI2016]幸运数字(倍增LCA,点分治+线性基)
4568: [Scoi2016]幸运数字 Time Limit: 60 Sec Memory Limit: 256 MBSubmit: 2131 Solved: 865[Submit][Statu ...
- 值得收藏:一份非常完整的MySQL规范
一.数据库命令规范 所有数据库对象名称必须使用小写字母并用下划线分割 所有数据库对象名称禁止使用mysql保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来) 数据库对象的命名要能做到见名 ...
- 【状态压缩DP】【BZOJ1087】【SCOI2005】互不侵犯king
1087: [SCOI2005]互不侵犯King Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 3135 Solved: 1825[Submit][ ...
- 快速创建一个的指定大小的内容全为0xFF的文件
比如需要创建一个大小为2KB,内容为全0xFF的文件 步骤只有两步: 第一步. dd if=/dev/zero of=./test.img bs=1 count=2048 第二步. 使用WinHex文 ...
- 【Linux】CentOS7上rpm命令批量卸载删除模糊rpm包名
例如,我要删除如下文件名匹配上wine的所有文件
- hdu1013(C++)
9的余数定理:一个数各位数字的总和除以9的余数与它本身除以9的余数同等 大数问题:防止大数,用字符串来存入数据,再转化为数字 #include<iostream>#include<s ...
- Ubuntu下eclipse不能新建java项目 java project的解决办法
在ubuntu系统中,装了eclipse,打开过,后来装了JDK,却不能新建java项目.重装了几遍eclipse也没有用. 原因分析: 之所以新建找不到java项目是因为eclipse有残留文件导致 ...
- How to initialize th rasp berry PI
WHAT YOU WILL NEED REQUIRED SD Card We recommend an 8GB class 4 SD card – ideally preinstalled with ...