【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接
【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接
问题描述
通过模拟网页,实现百度搜索关键词,然后获得网页中链接的文本,与准备的文本进行比较,如果有相似之处则代表相关链接。
mechanicalsoup模块
MechanicalSoup无需图形界面环境下的浏览器开源项目,是一个基于极其流行而异常多能的 HTML 解析库 Beautiful Soup 建立的爬虫库。如果你的爬虫需要相当的简单,但是又要求检查一些选择框或者输入一些文字,而你又不想为这个任务单独写一个爬虫,那么这会是一个值得考虑的选择。
安装
pip install MechanicalSoup
需要BeautifulSoup和requests库的依赖。
解析百度网页源码
分析百度网页源代码,找到用来接收搜索关键字的表单和输入框。
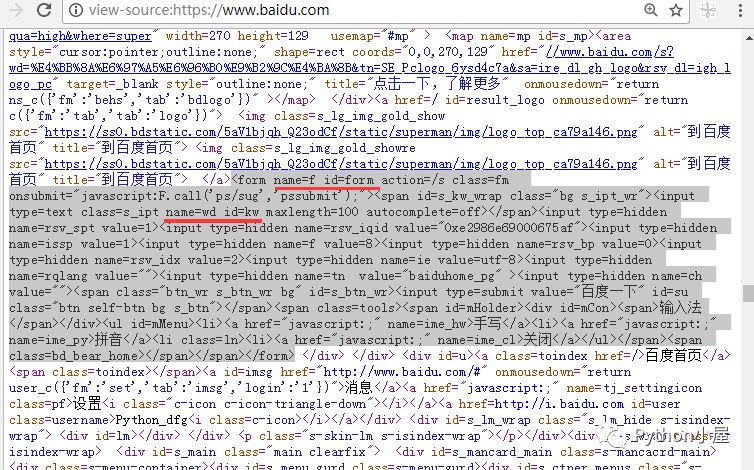
程序实现
map函数
map函数第一个参数为函数,但不需要'()',第二个参数是迭代器对象,作用是对迭代器对象遍历使用第一个函数。
- #!/usr/bin/env python
- #-*- coding:utf-8 -*-
- """
- @author:BanShaohuan
- @file: Python 3.6模拟输入并爬取百度前10页密切相关链接
- @time: 2018/06/09
- @contact: banshaohuan@163.com
- @software: PyCharm
- """
- import mechanicalsoup
- # python小屋文章清单
- with open('list.txt', encoding="utf8") as fp:
- articles = fp.readlines()
- #=> 使用map函数,去掉从文本当中读取时的字符,并放入元组中
- articles = tuple(map(str.strip, articles))
- # 模拟打开指定网址,模拟输入并提交输入的关键字
- browser = mechanicalsoup.StatefulBrowser() #=> 新建一个对象
- browser.open(r'http://www.baidu.com')#=> 模拟打开百度
- browser.select_form("#form")#=> 根据class指定一个表单
- browser['wd'] = 'Python小屋'#=> 根据表单的id指定表单中输入的内容
- browser.submit_selected()#=> 提交,模拟搜索
- # 获取百度前十页
- top10Urls = []
- #=> get_current_page得到本页网页,得到a标签对象
- for link in browser.get_current_page().select('a'):
- if link.text in tuple(map(str, range(2, 11))):
- #=> link.attrs['href] a标签中的属性得到值
- top10Urls.append(r'http://www.baidu.com'+ link.attrs['href'])
- # 与微信公众号里的文章标题进行比对,如果非常相似就返回True
- def check(text):
- for article in articles:
- # 使用切片,防止网站转发公众号文章时标题不完整
- if article[2:-2].lower() in text.lower():
- return True
- return False
- # 只输出密切相关的链接
- def getLinks():
- for link in browser.get_current_page().select('a'):
- text = link.text
- if 'Python小屋' in text or '董付国' in text or check(text):
- print(link.text, '-->', link.attrs['href'])
- # 输出第一页
- getLinks()
- # 处理后面的9页
- for url in top10Urls:
- browser.open(url)
- getLinks()
参考内容:Python 3.6模拟输入并爬取百度前10页密切相关链接

【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接的更多相关文章
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- Python 基础语法+简单地爬取百度贴吧内容
Python笔记 1.Python3和Pycharm2018的安装 2.Python3基础语法 2.1.1.数据类型 2.1.1.1.数据类型:数字(整数和浮点数) 整数:int类型 浮点数:floa ...
- Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一.搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界 ...
- 【python爬虫和正则表达式】爬取表格中的的二级链接
开始进公司实习的一个任务是整理一个网页页面上二级链接的内容整理到EXCEL中,这项工作把我头都搞大了,整理了好几天,实习生就是端茶送水的.前段时间学了爬虫,于是我想能不能用python写一个爬虫一个个 ...
- python简单爬虫 用beautifulsoup爬取百度百科词条
目标:爬取“湖南大学”百科词条并处理数据 需要获取的数据: 源代码: <div class="basic-info cmn-clearfix"> <dl clas ...
- Python爬虫之简单的爬取百度贴吧数据
首先要使用的第类库有 urllib下的request 以及urllib下的parse 以及 time包 random包 之后我们定义一个名叫BaiduSpider类用来爬取信息 属性有 url: ...
- python制作的翻译器基于爬取百度翻译【笔记思路】
#!/usr/bin/python # -*- coding: cp936 -*- ################################################### #基于百度翻 ...
- Python每日一练(3):爬取百度贴吧图片
import requests,re #先把要访问URL和头部准备好 url = 'http://tieba.baidu.com/p/2166231880' head = { 'Accept': '* ...
随机推荐
- DAY10-MYSQL库操作
一 系统数据库 information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息.列信息.权限信息.字符信息等performance_schema: MyS ...
- struts2学习笔记(5)拦截器
继承AbstractInterceptor类,在类中完成拦截器的功能,只需实现intercept方法即可,提供了init()和destroy()的空实现 示例:显示执行action所用的时间 ①在sr ...
- 百度地图SDK v2.1.2使用方法
1.开发工具 Android开发工具有很多,开发者可根据自己的喜好进行选择.在此,我们推荐开发者使用Eclipse作为自己的开发工具,本套开发指南也是针对Eclipse开发环境下进行编写的. 2.工程 ...
- 探索Web Office Apps服务
老样子,先放几个官链: WOA部署规划:http://technet.microsoft.com/zh-cn/library/jj219435(v=office.15).aspx 拓扑规划:http: ...
- HDU 4921 Map(状态压缩)
题意看这篇博客. 思路参考的这篇博客. 补充:面对这种问题有一个常见的套路.比如计算若干个区间对答案的贡献这种问题,直接暴力可能复杂度到O(n ^ 2), 而我们可以计算出每个元素在多少个合法区间中, ...
- webfrom 母版页
ASP.NET中母版页作用 一是提高代码的复用(把相同的代码抽出来) 二是使整个网站保持一致的风格和样式. 母版页存在就一定要有内容页的存在,否则母版页的存在就没有了意义. .master 一.添加母 ...
- 【转】phpize学习
为什么使用phpize? 比如刚开始安装的时候使用 ./configure --prefix=/usr/local/php7 --exec-prefix=/usr/local/php7 --bindi ...
- vray学习笔记(2)vray工作流程
在bilibili上面搜索到了一个vray的教程,虽然是英语的,细节方面可能听不太懂,但可以了解整个工作流程,工作流程太重要了,先看下视频的目录: 第1节到第9节都是建模的内容. 第10节和第13节是 ...
- unix 下 shell 遍历指定范围内的日期
UNIX下遍历日期,date 没有 -d 的参数,所以需要自己处理. 下面使用时差的方法进行计算,遍历的日期是降序的 #!/usr/bin/ksh . $HOME/.profile timelag= ...
- Linux问题FAQ1
1.使用vi编辑器时候,按方向键会产生A,B,C之类的 解决办法:ubuntu server 8.04, vim版本为 7.1.138,客户端使用pietty.vim 在插入模式下, 方向键被转为A ...