《机器学习实战》学习笔记第十二章 —— FP-growth算法
主要内容:
一. FP-growth算法简介
二.构建FP树
三.从一颗FP树中挖掘频繁项集
一. FP-growth算法简介
1.上次提到可以用Apriori算法来提取频繁项集,但是Apriori算法有个致命的缺点,那就是它对每个潜在的频繁项集都需要扫描数据集判定其是否频繁,因而在时间消耗上是巨大的。据说在实际应用上一般都不用Apriori算法,那用什么呢?FP-growth算法。
2.FP算法的核心就是将数据集存储在一个特定的称作FP树的结构当中,FP树与Trie树(字典树)十分相似,一样是共用“前缀”。构建完FP树之后,就可以递归地在FP树上挖掘频繁项集。FP-growth算法只需要对数据集进行两次扫描(第一次扫描在建树时,第二次扫描在哪里?惭愧,真看不出在哪里。),且利用到了类似Trie树这种节省“空间”的结构,运行起来比Apriori算法快了不少。
二.构建FP树
1.算法描述:
1)假设有六条数据,如下

2)为了将这些数据插进类似Trie树的结构中,且为了树的规模尽可能小(这样树的表示效率才高),可以想到:将集合型的数据通过按照字母出现频率降序排序,形成列表型的数据。因为将经常出现的字母都放在了每条数据的前面,在插入FP树中,公共前缀就更多了,即公共节点多了,树的规模就小了,所以树的表示效率就是高效的。

3)将每条数据重新调整后,就将数据插入到FP树中,其过程与Trie树无异。在建树的同时,还需要维护一个字母表,字母表需要记录字母的出现次数以及在FP树中出现的位置(位置通过链表维护)。
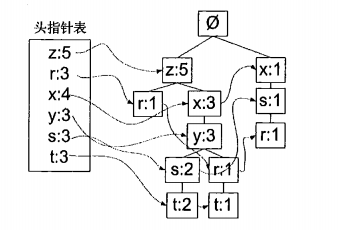
2.代码注释:
class treeNode: #树结点
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue #这个结点所存的字母
self.count = numOccur #结点计数器
self.nodeLink = None #指向下一个同字母的结点的指针
self.parent = parentNode # 指向父节点的指针,用于上溯
self.children = {} #儿子结点的指针集 def inc(self, numOccur): #更新结点计数器
self.count += numOccur def createTree(dataSet, minSup=1): #根据数据创建FP树,minSup为出现次数的阈值
headerTable = {} #字母表,需要存储两个信息:1.该字母的出现次数,2.指向该字母出现在FP树上的头指针
# 统计每个字母出现的次数
for trans in dataSet: #枚举每一条数据
for item in trans: #枚举该条数据的每一个字母
headerTable[item] = headerTable.get(item, 0) + dataSet[trans] #累加
for k in headerTable.keys(): # 枚举每一个字母,去除掉那些出现次数低于阈值的字母
if headerTable[k] < minSup:
del (headerTable[k])
freqItemSet = set(headerTable.keys()) #将符合条件的字母放到一个set中,即freqItemSet
if len(freqItemSet) == 0: return None, None # if no items meet min support -->get out
for k in headerTable: #为headerTable开辟多一个位置,存放头指针
headerTable[k] = [headerTable[k], None] # reformat headerTable to use Node link retTree = treeNode('Null Set', 1, None) # 创建根节点
for tranSet, count in dataSet.items(): # 将每一条数据插进FP树中,期间需要去除掉数据中出现次数低于阈值的字母,且数据中字母需要按出现次数进行降序排序
localD = {} #用于存放该数据中符合条件的字母
for item in tranSet: # 枚举这条数据的每个字母
if item in freqItemSet: #如果该字母符合条件,则放进localD中
localD[item] = headerTable[item][0]
if len(localD) > 0:
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)] #将符合条件的字母按出现次数进行降序排序
updateTree(orderedItems, retTree, headerTable, count) # 然后将其插入FP树中
return retTree, headerTable # 返回FP树和字母表 def updateTree(items, inTree, headerTable, count): #将一条数据插进FP树中,类似于将一条字符串插进Trie树中
if items[0] in inTree.children: # 若首字母的结点存在,则直接更细该节点的计数器
inTree.children[items[0]].inc(count) # incrament count
else: # 否则
inTree.children[items[0]] = treeNode(items[0], count, inTree) #创建新结点,之后需要将该结点放进字母表的链表中
if headerTable[items[0]][1] == None: # 如果该字母首次出现,则直接将字母表的头指针指向该结点
headerTable[items[0]][1] = inTree.children[items[0]]
else: #否则,需要将其插入到合适的位置,书本的做法是尾插法
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
if len(items) > 1: # call updateTree() with remaining ordered items
updateTree(items[1::], inTree.children[items[0]], headerTable, count) def updateHeader(nodeToTest, targetNode): # 将新建的字母结点加入到字母表链的链尾,但个人认为头插法更优
while (nodeToTest.nodeLink != None): # Do not use recursion to traverse a linked list!
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
三.从一颗FP树中挖掘频繁项集
1.算法步骤
初始化:将“当前频繁项集合的前缀”设为空。
枚举生成FP树时附带生成的字母表:
1)将枚举到的字母添加到“当前频繁项集合的前缀”的末尾,这时我们就挖掘到了一个频繁项集,把它存起来。
2)在FP树中寻找该字母所有的前缀被称为“条件模式基”(管他叫什么呢),接着利用这些前缀构建一棵FP树,同时也得到了字母表。
3)如果树不为空,则对这棵新的FP树进行挖掘(此时更新的参数有:FP树、字母表、“当前频繁项集合的前缀”),这是一个递归的形式。
2.算法详解:
1)关于递归地创建FP树:
假如在递归的第一层,当前枚举到的字母为A,A在树中出现了几次,且都在树的内部。这是我们实质上是挖掘到了一个频繁项集的,那就是{}+A,而这个{}就是“当前频繁项集合的前缀”。之后在FP树中将字母A的所有前缀都取出来,对于其中一条被取出来的前缀,它的实际就是“某条数据的子集”,之后将他们组成另一棵FP树。在构建FP树的过程中,需要重新“统计”、“剔除”、“排序”,因为原本在旧FP树中某些字母的出现频率符合要求,但在新的FP树由于只是选出了部分路径而漏了其他,所以可能导致字母的频率低于阈值,或者字母的排位发生了变化。对于新构建的FP树,我们可知其是在“共有频繁项集A”的情况下的FP树,即这个FP树是有“前提条件”或者说是有“状态”的。在这棵新的FP树,我们继续枚举字母表的字母,假设枚举到字母B,那么我们又挖掘到了一个频繁项集,那就是{A}+B。以此递归地枚举下去,就可以挖掘出所有的频繁项集了。
2)关于挖掘到的频繁项集是否有重复的问题:
由于形成FP树的“数据条”里面的字母是排序过的,所在FP树中,祖先与子孙的关系是严格确定了的。出现频率高的为祖先,低的为子孙,所以在一条从根节点到叶子结点的路径中,如果A出现在B的前面,那么在B的后面,A是绝对不会出现的。简而言之:假如A的频率高于B的频率,那么所有的A必定出现在B的上面。这一点就保证了频繁项集不会有重复。
3.代码注释:
def updateHeader(nodeToTest, targetNode): # 将新建的字母结点加入到字母表链的链尾,但个人认为头插法更优
while (nodeToTest.nodeLink != None): # Do not use recursion to traverse a linked list!
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode def ascendTree(leafNode, prefixPath): #在FP树,从一个结点开始,上溯至根节点,并记录路径。这样就找到了频繁项的一个前缀路径
if leafNode.parent != None:
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath) def findPrefixPath(treeNode): # 在FP树,找出某个字母所有的前缀路径,即找到对应的条件模式基
condPats = {} #存储前缀路径,为何要用字典的形式?因为还要记录每条前缀路径的出现次数,然后又用来创建FP树
while treeNode != None:
prefixPath = [] #保存当前的前缀路径
ascendTree(treeNode, prefixPath)
if len(prefixPath) > 1: #因为该节点也被加进了路径当中,所以需要路径的长度大于1
condPats[frozenset(prefixPath[1:])] = treeNode.count #将前缀路径并其出现次数存起来
treeNode = treeNode.nodeLink #沿着字母表链,走向下一个结点,继续寻找前缀路径
return condPats '''递归地从FP树中挖掘频繁项集,headerTable为字母表,preFix为当前频繁项集合的前缀, freqItemList用于存储频繁项集'''
def mineTree(inTree, headerTable, minSup, preFix, freqItemList):
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: p[1])] # 对字母表进行排序(根据出现次数),但为什么 要排序呢?
for basePat in bigL: # 枚举字母表中的每一个字母
newFreqSet = preFix.copy()
newFreqSet.add(basePat) #将该字母加入到“当前频繁项集合的前缀”中,形成新的频繁项集
freqItemList.append(newFreqSet) #保存新的频繁项集
condPattBases = findPrefixPath(headerTable[basePat][1]) #在当前FP树中找到该字母的条件模式基
myCondTree, myHead = createTree(condPattBases, minSup) # 然后利用条件模式基创建新的FP树
if myHead != None: # 如果裁剪过后的FP树仍不为空,则将新的频繁项集作为“当前频繁项集合的前缀”,然后在新的FP树上继续挖掘频繁项集
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)
《机器学习实战》学习笔记第十二章 —— FP-growth算法的更多相关文章
- o'Reill的SVG精髓(第二版)学习笔记——第十二章
第十二章 SVG动画 12.1动画基础 SVG的动画特性基于万维网联盟的“同步多媒体集成语言”(SMIL)规范(http://www.w3.org/TR/SMIL3). 在这个动画系统中,我们可以指定 ...
- 学习笔记 第十二章 CSS3+HTML5网页排版
第12章 CSS3+HTML5网页排版 [学习重点] 正确使用HTML5结构标签 正确使用HTML5语义元素 能够设计符合标准的网页结构 12.1 使用结构标签 在制作网页时,不仅需要使用< ...
- [HeadFirst-HTMLCSS学习笔记][第十二章HTML5标记]
考虑HTML结构 HTML5即是把原来<div>换成一些更特定的元素.能够更明确指示包含什么内容. (页眉,导航,页脚,文章) article nav 导航 header footer t ...
- Linux学习笔记(第十二章)
grep进阶 grep:以整行为单位进行截取 截取的特殊符号 正规表示法特殊字符 注意: sed用法 格式化打印 awk 用法 diff档案对比: path旧文档升级为新文档
- 汇编入门学习笔记 (十二)—— int指令、port
疯狂的暑假学习之 汇编入门学习笔记 (十二)-- int指令.port 參考: <汇编语言> 王爽 第13.14章 一.int指令 1. int指令引发的中断 int n指令,相当于引 ...
- VSTO 学习笔记(十二)自定义公式与Ribbon
原文:VSTO 学习笔记(十二)自定义公式与Ribbon 这几天工作中在开发一个Excel插件,包含自定义公式,根据条件从数据库中查询结果.这次我们来做一个简单的测试,达到类似的目的. 即在Excel ...
- Android群英传笔记——第十二章:Android5.X 新特性详解,Material Design UI的新体验
Android群英传笔记--第十二章:Android5.X 新特性详解,Material Design UI的新体验 第十一章为什么不写,因为我很早之前就已经写过了,有需要的可以去看 Android高 ...
- [CSAPP笔记][第十二章并发编程]
第十二章 并发编程 如果逻辑控制流在时间上是重叠,那么它们就是并发的(concurrent).这种常见的现象称为并发(concurrency). 硬件异常处理程序,进程和Unix信号处理程序都是大家熟 ...
- Binder学习笔记(十二)—— binder_transaction(...)都干了什么?
binder_open(...)都干了什么? 在回答binder_transaction(...)之前,还有一些基础设施要去探究,比如binder_open(...),binder_mmap(...) ...
随机推荐
- 如何突破PHP程序员的技术瓶颈分析
来自:http://www.jb51.net/article/27740.htm 身边有几个做PHP开发的朋友,也接触到不少的PHP工程师,他们常疑虑自己将来在技术上的成长与发展,我常给他们一些建议, ...
- oracle查看用户有哪些权限和角色
select * from dba_sys_privs t where t.grantee='HR';select * from dba_role_privs t where t.grantee='H ...
- window 添加环境变量
右击我的电脑 选择属性 点选高级选项卡 点击环境变量 在系统变量中选中path变量 点击编辑 在变量值得最后插入 ;C:\Python27\ (改为Python的实际的安装地址) 记住后面要有最后面 ...
- .Net 开发Windows Service
1.首先创建一个Windows Service 2.创建完成后切换到代码视图,代码中默认有OnStart和OnStop方法执行服务开启和服务停止执行的操作,下面代码是详细解释: using Syste ...
- unity视频教程
英雄联盟教程 http://pan.baidu.com/s/1i3rkMS9 密码:bv6r https://pan.baidu.com/share/link?shareid=258985 ...
- python 基础 9.9 查询数据
#/usr/bin/python #-*- coding:utf-8 -*- #@Time :2017/11/24 4:21 #@Auther :liuzhenchuan #@File : ...
- [原创]aaencode等类似js加密方案破解方法
受http://tieba.baidu.com/p/4104806767 2L启发,不过他说的方法,我没有尝试成功,自己摸索出了一个新方法,在这里分享下. 首先拿aaencode官网的加密字符串作为例 ...
- 新升级!EasyNVR3.0功能概述--直播与录像
背景介绍: 对于摄像机直播已经是我们司空见惯的需求,但是,许多用户在现有的直播的基础上更有录像的需求,并且有关于录像的删除定时等录像计划的需求,更有客户不仅需要这些功能,还需要将这些功能集成到自身的业 ...
- java 基于tomcat的数据源案例
1.在context中定义数据源 <?xml version="1.0" encoding="UTF-8"?> <Context path=& ...
- 【HTML5开发系列】HTML元素总结
HTML元素汇总,包含HTML4元素和HTML5新增元素.Y表示有变化,N则表示没有变化,N/A表示未知 文档和元数据元素 包括说明HTML文档的结构,向浏览器说明文档的情况,定义脚本程序和css样式 ...