Hadoop MapReduce 操作 统计词频
1、 准备文件并设置编码格式为UTF-8并上传Linux
1)设置编码:首先打开文件点击左上角 文件(F) 点击另存为并将编码(E)设置为UTF-8 然后保存(S)替换的原来的文件
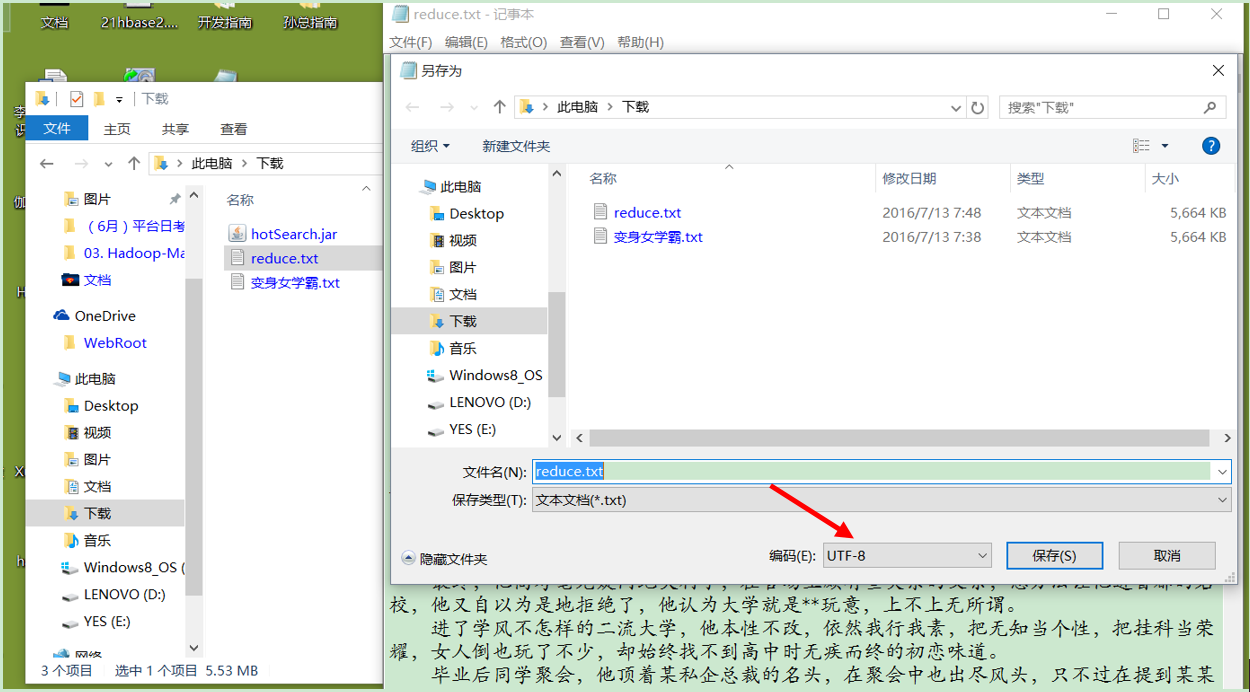
2)用工具将文件上传就Linux
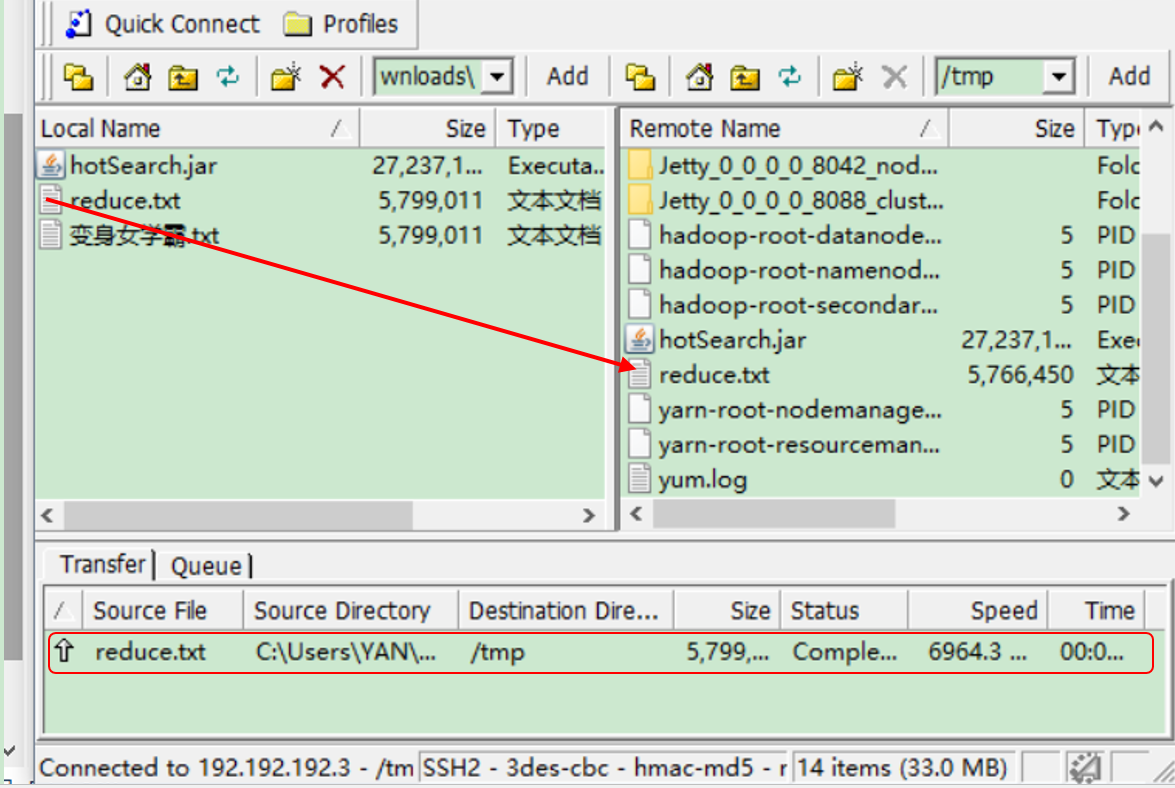
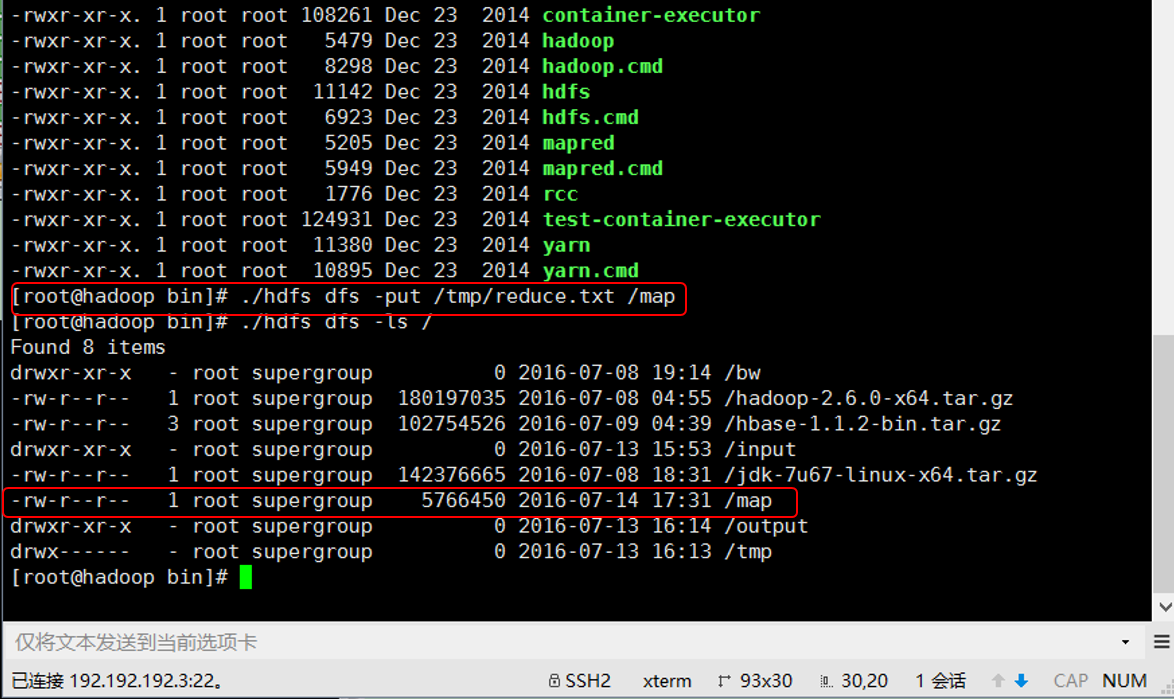
3)将文件上传至HDFS
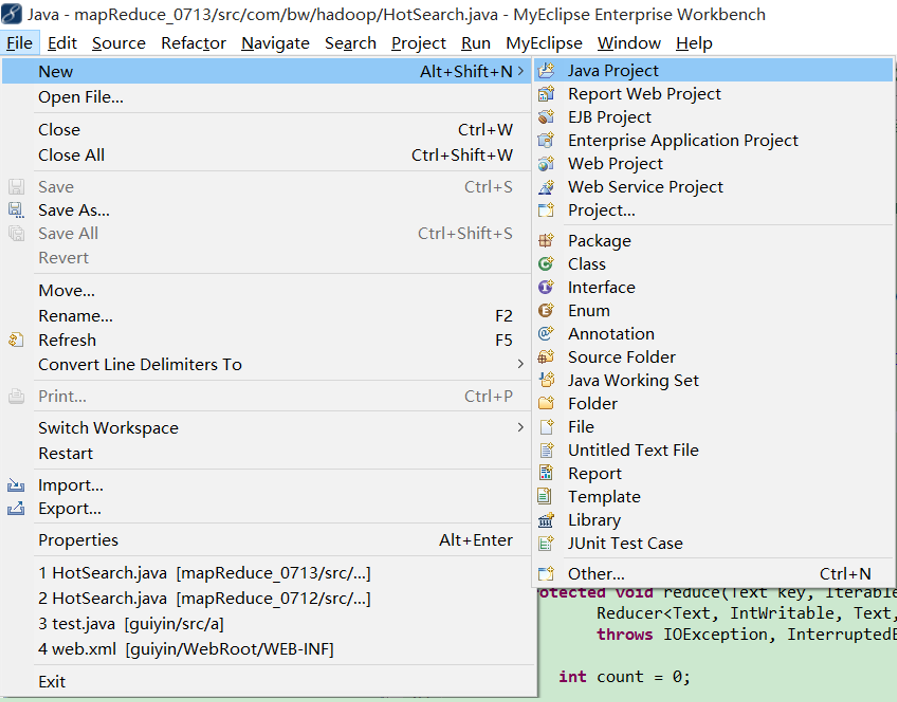
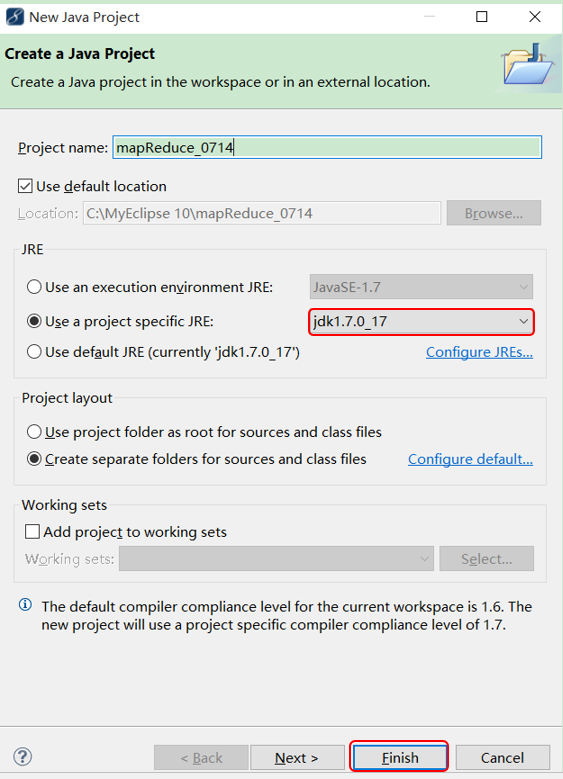
2、 新建一个Java Project
JDK必须是1.7版本以后的否则不支持

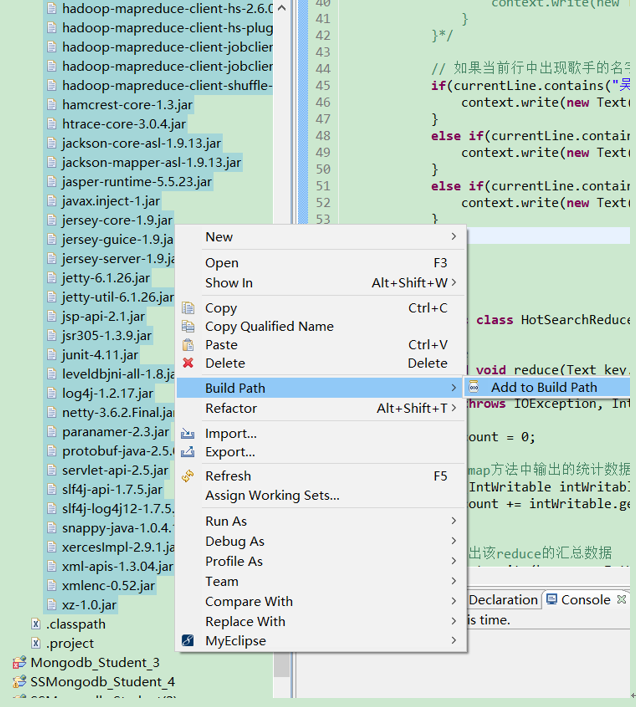
3、 导入jar
导入好多jar包并Add to Build Path

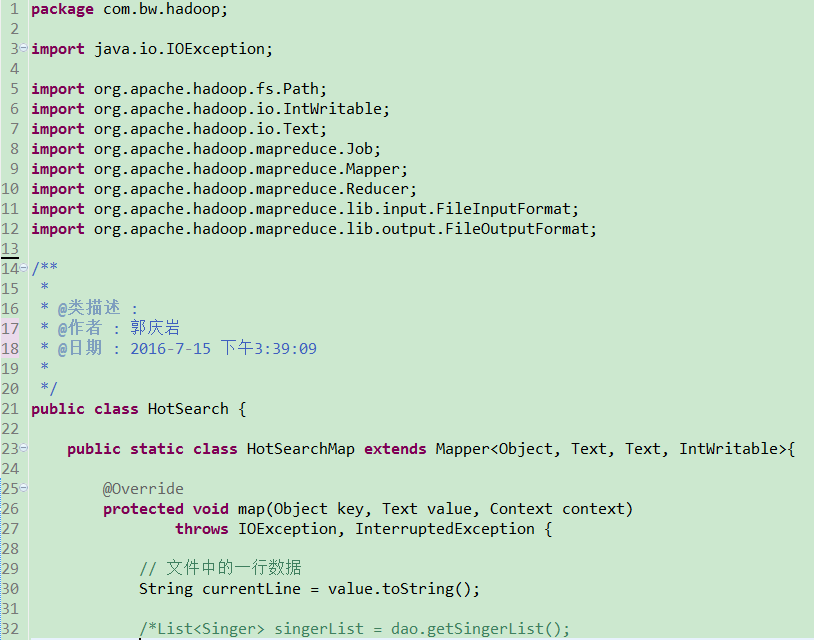
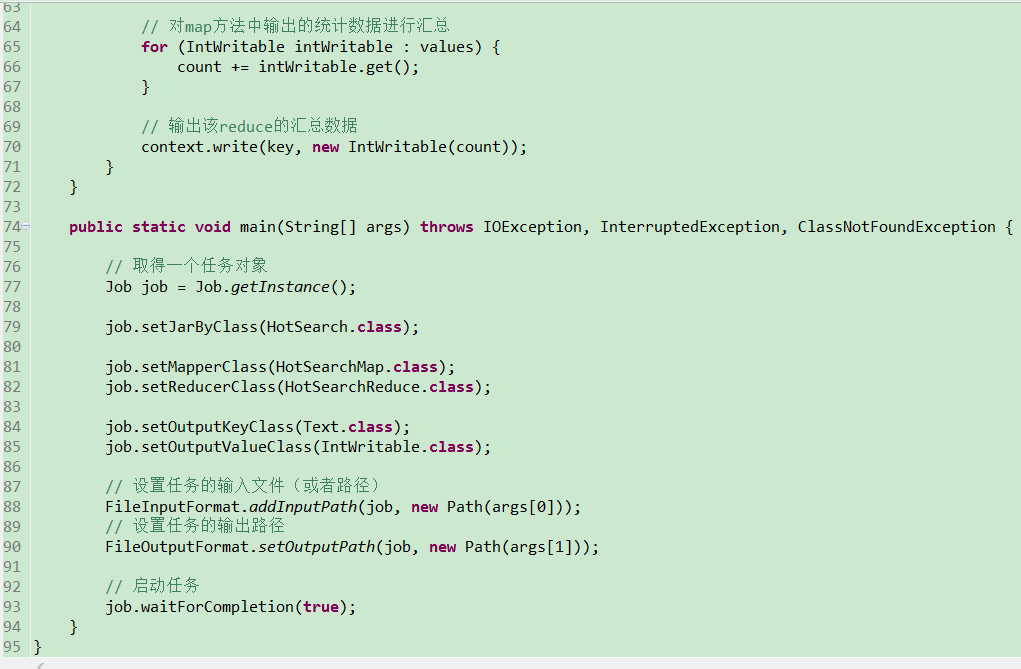
4、 编写Map()和Reduce()

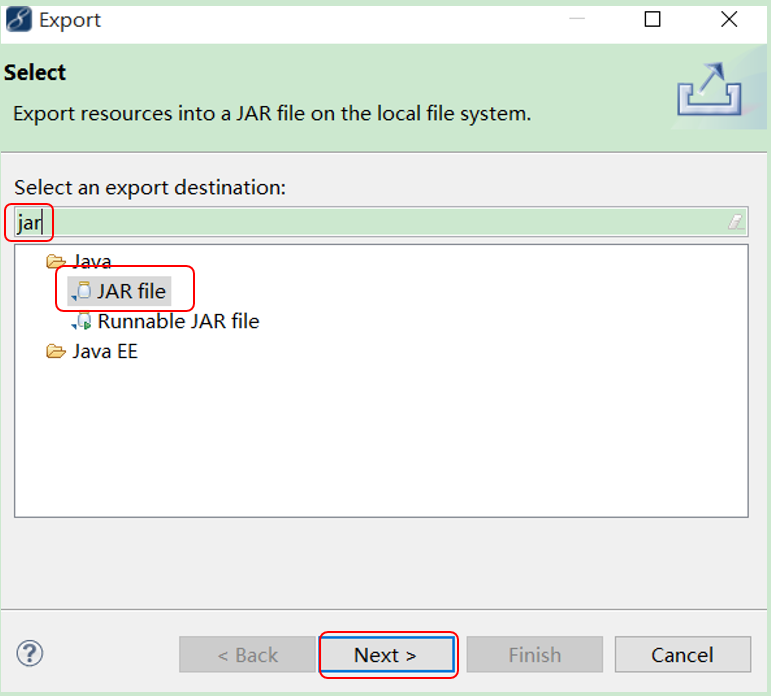
5、将代码输出成jar
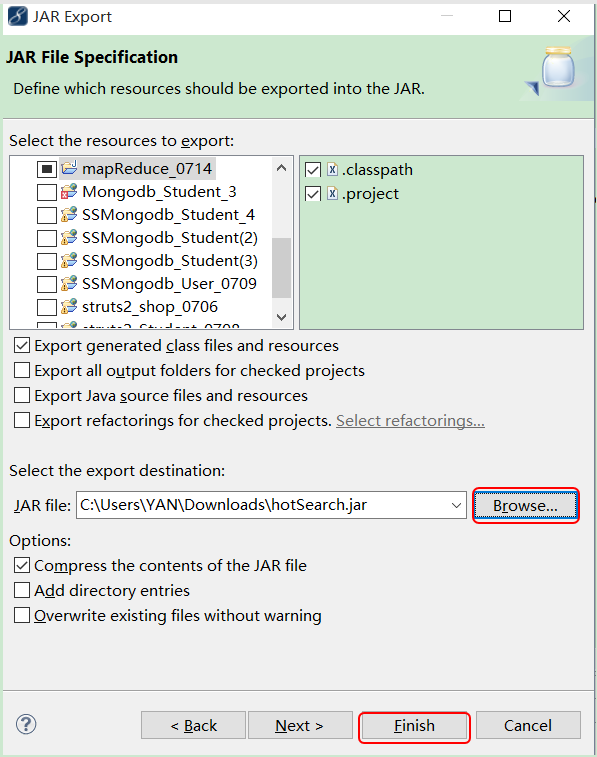
1) 将代码输出成jar

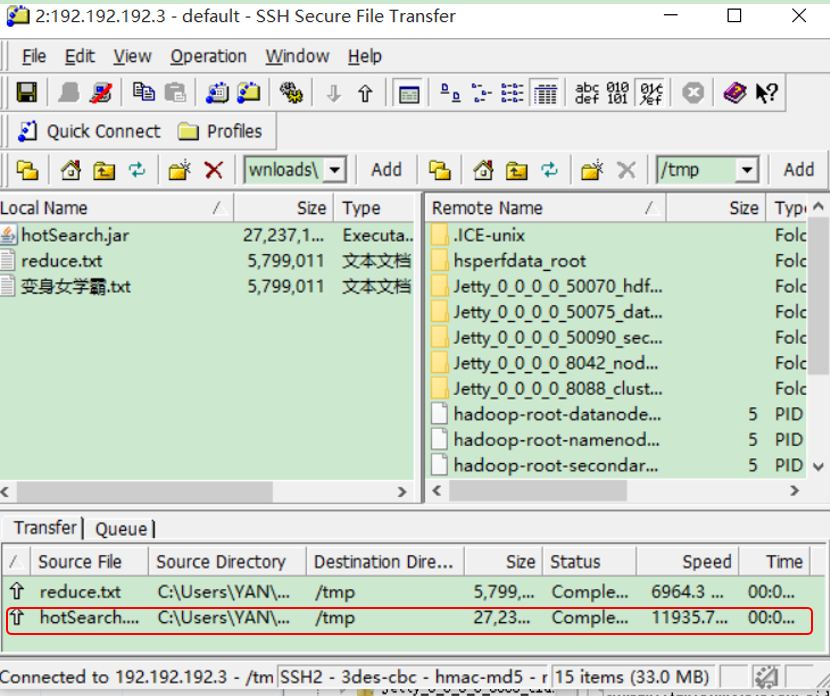
2) 将生成的jar上传至Linux
6、在linux中启动hdfs
1) 启动hdfs

1) 将text文件上传到HDFS

7、修改两个配置文件

在<configuration>配置项中增加以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
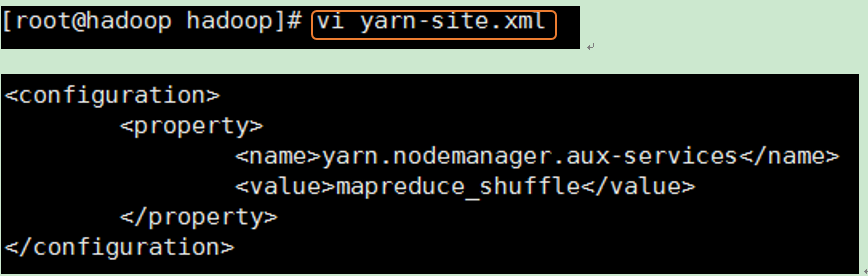
在<configuration>配置项中增加以下内容:
(参数解释:NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运MapReduce程序)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
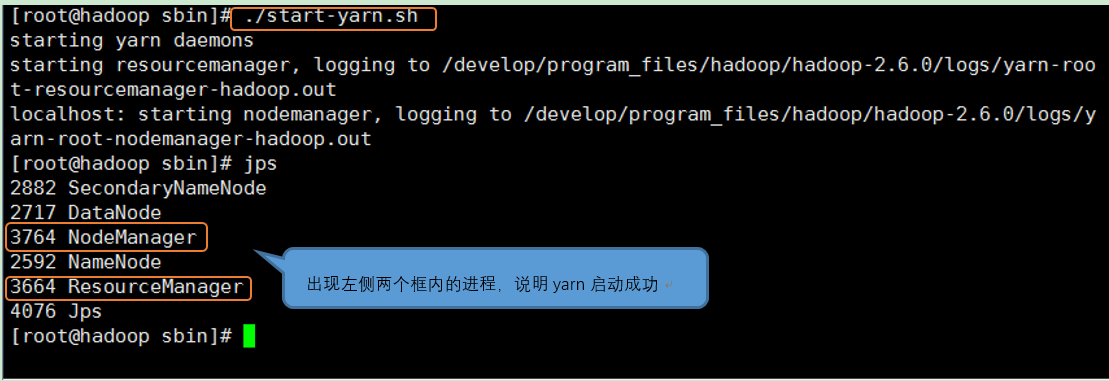
8、在linux中启动yarn
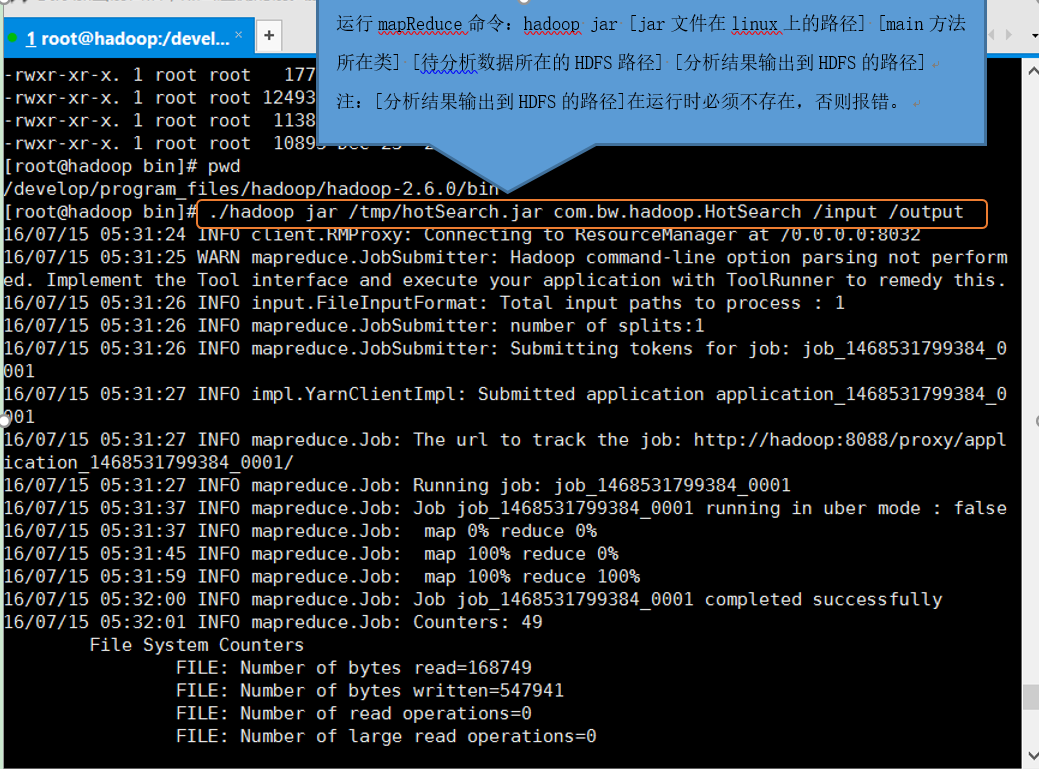
9、运行mapReduce
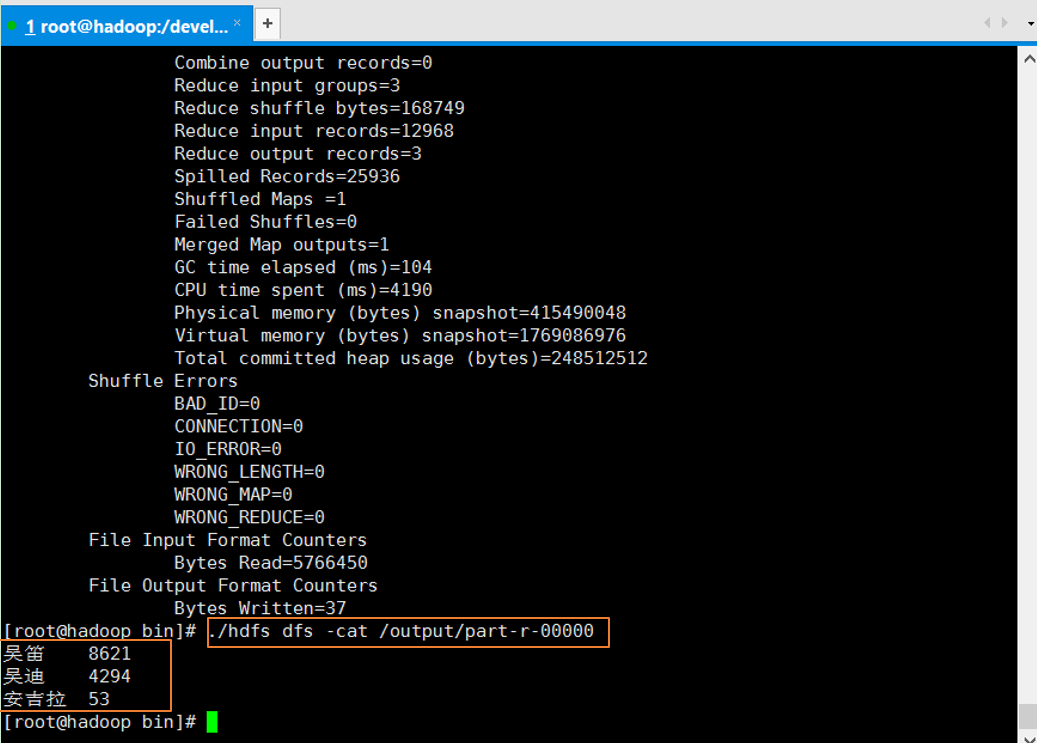
10、查看运行结果
Hadoop MapReduce 操作 统计词频的更多相关文章
- Hadoop,MapReduce操作Mysql
前以前帖子介绍,怎样读取文本数据源和多个数据源的合并:http://www.cnblogs.com/liqizhou/archive/2012/05/15/2501835.html 这一个博客介绍一下 ...
- Hadoop MapReduce编程学习
一直在搞spark,也没时间弄hadoop,不过Hadoop基本的编程我觉得我还是要会吧,看到一篇不错的文章,不过应该应用于hadoop2.0以前,因为代码中有 conf.set("map ...
- Hadoop Mapreduce 案例 wordcount+统计手机流量使用情况
mapreduce设计思想 概念:它是一个分布式并行计算的应用框架它提供相应简单的api模型,我们只需按照这些模型规则编写程序,即可实现"分布式并行计算"的功能. 案例一:word ...
- 【Cloud Computing】Hadoop环境安装、基本命令及MapReduce字数统计程序
[Cloud Computing]Hadoop环境安装.基本命令及MapReduce字数统计程序 1.虚拟机准备 1.1 模板机器配置 1.1.1 主机配置 IP地址:在学校校园网Wifi下连接下 V ...
- Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.SalaryCount; import java.io.IOException; import jav ...
- 023_数量类型练习——Hadoop MapReduce手机流量统计
1) 分析业务需求:用户使用手机上网,存在流量的消耗.流量包括两部分:其一是上行流量(发送消息流量),其二是下行流量(接收消息的流量).每种流量在网络传输过程中,有两种形式说明:包的大小,流量的大小. ...
- Hadoop MapReduce编程 API入门系列之统计学生成绩版本2(十八)
不多说,直接上代码. 统计出每个年龄段的 男.女 学生的最高分 这里,为了空格符的差错,直接,我们有时候,像如下这样的来排数据. 代码 package zhouls.bigdata.myMapRedu ...
- hadoop MapReduce运营商案例关于用户基站停留数据统计
注 如果需要文件和代码的话可评论区留言邮箱,我给你发源代码 本文来自博客园,作者:Arway,转载请注明原文链接:https://www.cnblogs.com/cenjw/p/hadoop-mapR ...
- Hadoop最基本的wordcount(统计词频)
package com.uniclick.dapa.dstest; import java.io.IOException; import java.net.URI; import org.apache ...
随机推荐
- centos 7网速监控脚本
#!/bin/bashif [ $# -ne 1 ];thendev="eth0"elsedev=$1fi while :doRX1=`/sbin/ifconfig $dev |a ...
- SSM配置Socket多线程编程(RFID签到实例)
1.SocketServiceLoader.java package cn.xydata.pharmacy.api.app.test; import javax.servlet.ServletCont ...
- 2-2-sshd服务安装管理及配置文件理解和安全调优
大纲: 1. 培养独自解决问题的能力 2. 学习第二阶段Linux服务管理的方法 3. 安装sshd服务 4. sshd服务的使用 5. sshd服务调优 6. 初步介绍sshd配置文件 ###### ...
- HDU-4705-树形dp/组合数学
Y Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others)Total Submiss ...
- Ubuntu相关命令
此贴包含自己搭建网站以及自学Ubuntu遇到的相关命令,方便以后查看,故相关帖子整理记录在此! 用户切换 当前用户切换到root用户,只需要执行sudo su即可. root用户切回user用户,只需 ...
- RabbitMQ消息队列(九)RPC开始应用吧
一 简单应用 RPC——远程过程调用,通过网络调用运行在另一台计算机上的程序的函数\方法,是构建分布式程序的一种方式.RabbitMQ是一个消息队列系统,可以在程序之间收发消息.利用RabbitMQ可 ...
- 002——vue小结
1.new 一个vue对象的时候你可以设置他的属性,其中最重要的包括三个,分别是:data,methods,watch. 2.其中data代表vue对象的数据,methods代表vue对象的方法,wa ...
- mac下初始化eclipse的安卓开发ndk开发环境
最近电脑由windows换成mac了,很多环境都要重新搭建,顺便纪录下,方便以后查阅. 1.先到eclipse官网下载最新版eclipse,我下载的是neon版,下载后直接解压到即可使用(前提是你安装 ...
- Python中for、while、break、continue、if的使用
1.if - elif - else 的使用 格式:if 条件1: 条件1满足时执行的事件1 条件2满足时执行的事件2 elif 条件2: 条件2满足执行事件3 条件2满足执行事件4 e ...
- Shell 命令行,实现对若干网站状态批量查询是否正常的脚本
Shell 命令行,实现对若干网站状态批量查询是否正常的脚本 如果你有比较多的网站,这些网站的运行状态是否正常则是一件需要关心的事情.但是逐一打开检查那简直是一件太糟心的事情了.所以,我想写一个 sh ...