初探Lambda表达式/Java多核编程【2】并行与组合行为
今天又翻了一下书的目录,第一章在这之后就结束了。也就是说,这本书所涉及到的新的知识已经全部点到了。
书的其余部分就是对这几个概念做一些基础知识的补充以及更深层次的实践。
最后两个小节的内容较少,所以合成一篇文章来总结。
上一篇:初探Lambda表达式/Java多核编程【1】从集合到流
从串行到并行
串行指一个步骤一个步骤地处理,也就是通常情况下,代码一行一行地执行。
如果将我们常用的迭代器式的循环展开的话,就是串行执行了循环体内所定义的操作:
sum += arr.get(0);
sum += arr.get(1);
sum += arr.get(2);
//...在书的一开始,就提到Java需要支持集合的并行计算(而Lambda为这个需求提供了可能)。
这些功能将全部被实现于库代码中,对于我们使用者,实现并行的复杂性被大大降低(最低程度上只需要调用相关方法)。
另外,关于并发与并行这两个概念,其实是不同的,如果不明白的话请自行了解,在此只引用一句非常流行的话:
一个是关于代码结构,一个是关于代码执行。
如果我们想将一个计算任务均匀地分配给CPU的四个内核,我们会给每个核分配一个用于计算的线程,每个线程上进行整个任务的子任务。
书上有一段非常形象的伪代码:
if the task list contains more than N/4 elements {
leftTask = task.getLeftHalf()
rightTask = task.getRightHalf()
doInparallel {
leftResult = leftTask.solve()
rightResult = rightTask.solve()
}
result = combine(leftResult, rightResult)
} else {
result = task.solveSequentially()
}代码中,将每四个任务元素分为一组,用四个内核对其进行并行处理,然后每两组进行一次结果的合并,最终得到整个任务队列的最终结果。
从整体处理流程上看,先将任务队列递归地进行分组,并行处理每一组,然后将结果递归地进行合并(合并通过管道终止操作实现)。
Java8之前,开发者们使用一种针对集合的fork/join框架来实现该模式。
然而现在,想对代码进行性能优化,就是一件非常容易的事了。
还记得我们上一节中所得出的最终代码:
long validContactCounter = contactList.stream()
.map(s -> new Contact().setName(s))
.filter(Contact::call)
.count();稍加改动:
long validContactCounter = contactList.parallelStream()
.map(s -> new Contact().setName(s))
.filter(Contact::call)
.count();注意stream()变为parallelStream()
同时下图将展示如何根据四个核对上述任务进行分解处理,最终合并结果并终止管道。
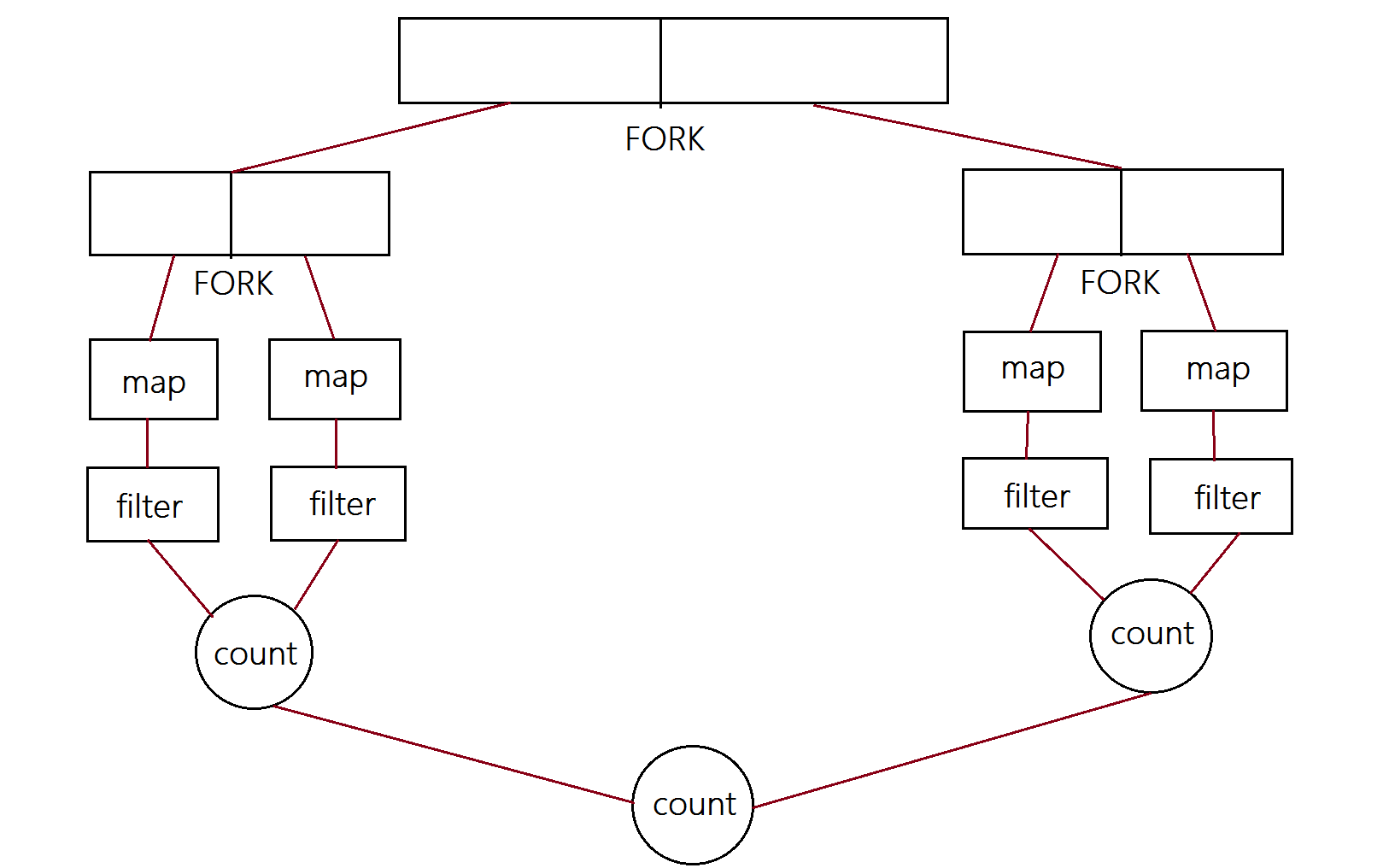
注意递归分解的目的是使子任务们足够小来串行执行。
组合行为
Java写手应该知道,Java中并不存在纯粹的“函数”,只存在“方法”。也就是说,Java中的函数必须依赖于某一个类,或者作为类的某种行为存在。
而在其他语言中,存在纯函数,以CoffeeScript的语法,声明一个函数:
eat = (x) ->
alert("#{x} has been eatten!")这种写法与Lambda表达式的语法非常相近,也就是说,相比于匿名内部类,Lambda表达式看上去更像是一种函数表达式。
对于函数,一个核心操作便是组合。如果要求一元二次函数的其中一个解sqrt(sqr(b) - 4 * a * c),便是对多个子函数进行了组合。
对于面向对象,我们通过解耦的方式来分解它,同样,我们也希望以此种方式分解一个函数行为。
首先,沿用上两节中使用的例子,对Contact类稍作修改,将name属性分拆为名和姓:
private String firstName;
private String lastName;假设我们现在想要对联系人们进行排序,创建自定义排序的Java标准方式是创建一个Comparator:
public interface Comparator<T> {
int compare(T o1, T o2);
//...
}我们想通过比较名的首字母来为联系人排序:
Comparator<Contact> byFirstName = new Comparator<Contact>() {
@Override
public int compare(Contact o1, Contact o2) {
return Character.compare(o1.getFirstName().charAt(0), o2.getFirstName().charAt(0));
}
};Lambda写法:
Comparator<Contact> byFirstNameLambdaForm = (o1, o2) ->
Character.compare(o1.getFirstName().charAt(0), o2.getFirstName().charAt(0));写完这段代码后,IDEA立即提醒我代码可以替换为Comparator.comparingInt(...),不过这是后话,暂且不表。
在上面的代码中,我们发现了组合行为,即Comparator<Contact>的compare(...)方法里面还套用了o.getFirstName()与Character.compare(...)这两个方法(为了简洁,这里暂不考虑charAt(...)),在java.util.function中,我们找到了这种函数的原型:
public interface Function<T, R> {
R apply(T t);
//...
}接收一个T类型的参数,返回一个R类型的结果。
现在我们将“比较名的首字母”这个比较键的提取行为抽成一个函数:
Function<Contact, Character> keyExtractor = o -> o.getFirstName().charAt(0);再将“比较首字母”这个具体的比较行为抽出来:
Comparator<Character> keyComparator = (c1, c2) -> Character.compare(c1, c2);有了keyExtractor和keyComparator,我们再来重新装配一下Comparator
Comparator<Contact> byFirstNameAdvanced = (o1, o2) ->
keyComparator.compare(keyExtractor.apply(o1), keyExtractor.apply(o2));到了这一步,我们牺牲了简洁性,但获得了相应的灵活性,也就是说,如果我们改变比较键为姓而非名,只需改动keyExtractor为:
Function<Contact, Character> keyExtractor = o -> o.getLastName().charAt(0);值得庆幸的是,库的设计者考虑到了这一自然比较的需求的普遍性,因此为Comparator接口提供了静态方法comparing(...),只需传入比较键的提取规则,就能针对该键生成相应的Comparator,是不是非常神奇:
Comparator<Contact> compareByFirstName = Comparator.comparing(keyExtractor);即使我们想改变比较的规则,比如比较联系人姓与名的长度,也只需做些许改动:
Comparator<Contact> compareByNameLength = Comparator.comparing(p -> (p.getFirstName() + p.getLastName()).length());这是一个重大的改进,它将我们所关注的焦点真正集中在了比较的规则上面,而不是大量地构建所必须的胶水代码。
comparing(...)通过接收一个简单的行为,进而基于这个行为构造出更加复杂的行为。
赞!
然而更赞的是,对于流和管道,我们所需要的改动甚至更少:
contacts.stream()
.sorted(compareByNameLength)
.forEach(c -> System.out.println(c.getFirstName() + " " + c.getLastName()));小结
本章的代码:
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.function.Function;
public class Bar {
public static void main(String[] args) {
// long validContactCounter = contactList.parallelStream()
// .map(s -> new Contact().setFirstName(s))
// .filter(Contact::call)
// .count();
List<Contact> contacts = new ArrayList<Contact>() {{
add(new Contact().setFirstName("Foo").setLastName("Jack"));
add(new Contact().setFirstName("Bar").setLastName("Ma"));
add(new Contact().setFirstName("Olala").setLastName("Awesome"));
}};
Comparator<Contact> byFirstName = new Comparator<Contact>() {
@Override
public int compare(Contact o1, Contact o2) {
return Character.compare(o1.getFirstName().charAt(0), o2.getFirstName().charAt(0));
}
};
//--- Using Lambda form ---//
Comparator<Contact> byFirstNameLambdaForm = (o1, o2) ->
Character.compare(o1.getFirstName().charAt(0), o2.getFirstName().charAt(0));
Function<Contact, Character> keyExtractor = o -> o.getFirstName().charAt(0);
Comparator<Character> keyComparator = (c1, c2) ->
Character.compare(c1, c2);
Comparator<Contact> byFirstNameAdvanced = (o1, o2) ->
keyComparator.compare(keyExtractor.apply(o1), keyExtractor.apply(o2));
Comparator<Contact> compareByFirstName = Comparator.comparing(keyExtractor);
Comparator<Contact> compareByNameLength = Comparator.comparing(p -> (p.getFirstName() + p.getLastName()).length());
contacts.stream()
.sorted(compareByNameLength)
.forEach(c -> System.out.println(c.getFirstName() + " " + c.getLastName()));
}
}以及运行结果:
Bar Ma
Foo Jack
Olala Awesome初探Lambda表达式/Java多核编程【2】并行与组合行为的更多相关文章
- 初探Lambda表达式/Java多核编程【1】从集合到流
从集合到流 接上一小节初探Lambda表达式/Java多核编程[0]从外部迭代到内部迭代,本小节将着手使用"流"这一概念进行"迭代"操作. 首先何为" ...
- 初探Lambda表达式/Java多核编程【3】Lambda语法与作用域
接上一篇:初探Lambda表达式/Java多核编程[2]并行与组合行为 本节是第二章开篇,前一章已经浅显地将所有新概念点到,书中剩下的部分将对这些概念做一个基础知识的补充与深入探讨实践. 本章将介绍L ...
- 初探Lambda表达式/Java多核编程【4】Lambda变量捕获
这周开学,上了两天感觉课好多,学校现在还停水,宿舍网络也还没通,简直爆炸,感觉能静下心看书的时间越来越少了...寒假还有些看过书之后的存货,现在写一点发出来.加上假期两个月左右都过去了书才看了1/7都 ...
- 初探Lambda表达式/Java多核编程【0】从外部迭代到内部迭代
开篇 放假前从学校图书馆中借来一本书,Oracle官方的<精通Lambda表达式:Java多核编程>. 假期已过大半才想起来还没翻上几页,在此先推荐给大家. 此书内容及其简洁干练,如果你对 ...
- Lambda&Java多核编程-5-函数式接口与function包
从前面的总结中我们知道Lambda的使用场景是实现一个函数式接口,那么本篇就将阐述一下何为函数式接口以及Java的function包中提供的几种函数原型. 函数式接口 早期也叫作SAM(Single ...
- Lambda&Java多核编程-6-方法与构造器引用
在Lambda&Java多核编程-2-并行与组合行为一文中,我们对Stream<Contact>里的每一位联系人调用call()方法,并根据能否打通的返回结果过滤掉已经失效的项. ...
- Lambda表达式和函数式编程
Lambda表达式和函数式编程 https://www.cnblogs.com/bigbigbigo/p/8422579.html https://www.runoob.com/java/java8- ...
- Lambda&Java多核编程-7-类型检查
本篇主要介绍Lambda的类型检查机制以及周边的一些知识. 类型检查 在前面的实践中,我们发现表达式的类型能够被上下文所推断.即使同一个表达式,在不同的语境下也能够被推断成不同类型. 这几天在码一个安 ...
- Lambda 表达式(C# 编程指南) 微软microsoft官方说明
Visual Studio 2013 其他版本 Lambda 表达式是一种可用于创建委托或表达式目录树类型的匿名函数. 通过使用 lambda 表达式,可以写入可作为参数传递或作为函数调用值返回的本地 ...
随机推荐
- webservice-概念性学习(一)
以下是本人原创,如若转载和使用请注明转载地址.本博客信息切勿用于商业,可以个人使用,若喜欢我的博客,请关注我,谢谢!博客地址 学习webservice之前呢,我想说我们先学习以下的知识,对你以后的学习 ...
- 一次性能优化,tps从400+到4k+
项目介绍 路由网关项目watchman ,接收前端http请求转发到后端业务系统,功能安全验证,限流,转发. 使用技术:spring boot+ nreflix zuul,最开始日志使用slf4j+l ...
- 【python】matplotlib在windows下安装
昨晚装了好久的这玩意,终于在凌晨成功搞定,然后跑起了一个人人网抓取好友关系的脚本~开心. 以下是我参考的最给力的文档,全部安装一遍,就可以啦~ 但是!在安装前一定要先确认自己的python版本!本人自 ...
- 用OpenSSL生成自签名证书在IIS上搭建Https站点(用于iOS的https访问)
前提: 先安装openssl,安装有两种方式,第一种直接下载安装包,装上就可运行:第二种可以自己下载源码,自己编译.这里推荐第一种. 安装包:http://slproweb.com/products/ ...
- MySQL常用命令总结3
id SMALLINT UNSIGNED [AUTO_INCREMENT] PRIMARY KEY, //把id定义为主键且自动排号,每张数据表只有一个主键,不能为NULL,确保记录唯一性 //省略a ...
- 【 bzoj4537】HNOI2016 最小公倍数
首先将边按a的值分组,每$\sqrt{m}$一组. 对于每一组,将符合一组a的询问选出来,将这些询问和这一块之前的边(a一定小于这些询问)按b排序,然后交替插入,询问,对于一个询问,在当前块也有可能有 ...
- onethink部署时后台登陆的问题
情况:本地开发后,上传到服务器时,无法登陆后台. 原因:用户的读取数据库的配置与应用的配置 分别在2个地方.而一般我们只记得修改一处配置. 解决:找到application/user/conf/con ...
- Object类可以接受引用类型
Object类是一切类的父类,所以Object类可以接受一切引用类型.连数组和接口对象也都可以接受. 1.接受数组 public class ObjectTest{ public static voi ...
- GitHub优秀的Android 开源项目
GitHub上优秀Android开源项目 转载自 : http://my.eoe.cn/sisuer/archive/3348.html http://my.eoe.cn/sisuer/archive ...
- iOS 之 手势
手势操作,有一个总的抽象类UIGestureRecognizer,用于检测设备的所有手势.其下有多个子类: 拍击UITapGestureRecognizer (任意次数的拍击) 向里或向外捏UIPin ...