Spark笔记之数据本地性(data locality)
一、什么是数据本地性(data locality)
大数据中有一个很有名的概念就是“移动数据不如移动计算”,之所以有数据本地性就是因为数据在网络中传输会有不小的I/O消耗,如果能够想办法尽量减少这个I/O消耗就能够提升效率。那么如何减少I/O消耗呢,当然是尽量不让数据在网络上传输,即使无法避免数据在网络上传输,也要尽量缩短传输距离,这个数据需要传输多远的距离(实际意味着数据传输的代价)就是数据本地性,数据本地性根据传输距离分为几个级别,不在网络上传输肯定是最好的级别,其它级别划分依据传输距离越远级别越低,Spark在分配任务的时候会考虑到数据本地性,优先将任务分配给数据本地性最好的Executor执行。
在执行任务时查看Task的执行情况,经常能够看到Task的状态中有这么一列: 
这一列就是在说这个Task任务读取数据的本地性是哪个级别,数据本地性共分为五个级别:
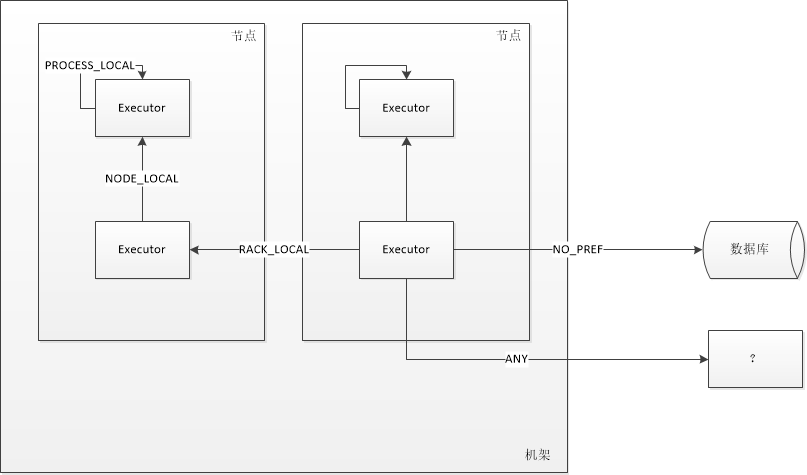
PROCESS_LOCAL:顾名思义,要处理的数据就在同一个本地进程中,即数据和Task在同一个Executor JVM中,这种情况就是RDD的数据在之前就已经被缓存过了,因为BlockManager是以Executor为单位的,所以只要Task所需要的Block在所属的Executor的BlockManager上已经被缓存,这个数据本地性就是PROCESS_LOCAL,这种是最好的locality,这种情况下数据不需要在网络中传输。
NODE_LOCAL:数据在同一台节点上,但是并不不在同一个jvm中,比如数据在同一台节点上的另外一个Executor上,速度要比PROCESS_LOCAL略慢。还有一种情况是读取HDFS的块就在当前节点上,数据本地性也是NODE_LOCAL。
NO_PREF:数据从哪里访问都一样,表示数据本地性无意义,看起来很奇怪,其实指的是从MySQL、MongoDB之类的数据源读取数据。
RACK_LOCAL:数据在同一机架上的其它节点,需要经过网络传输,速度要比NODE_LOCAL慢。
ANY:数据在其它更远的网络上,甚至都不在同一个机架上,比RACK_LOCAL更慢,一般情况下不会出现这种级别,万一出现了可能是有什么异常需要排查下原因。
使用一张图来表示五个传输级别:
二、延迟调度策略(Delay Scheduler)
Spark在调度程序的时候并不一定总是能按照计算出的数据本地性执行,因为即使计算出在某个Executor上执行时数据本地性最好,但是Executor的core也是有限的,有可能计算出TaskFoo在ExecutorBar上执行数据本地性最好,但是发现ExecutorBar的所有core都一直被用着腾不出资源来执行新来的TaskFoo,所以当TaskFoo等待一段时间之后发现仍然等不到资源的话就尝试降低数据本地性级别让其它的Executor去执行。
比如当前有一个RDD,有四个分区,称为A、B、C、D,当前Stage中这个RDD的每个分区对应的Task分别称为TaskA、TaskB、TaskC、TaskD,在之前的Stage中将这个RDD cache在了一台机器上的两个Executor上,称为ExecutorA、ExecutorB,每个Executor的core是2,ExecutorA上缓存了RDD的A、B、C分区,ExecutorB上缓存了RDD的D分区,然后分配Task的时候会把TaskA、TaskB、TaskC分配给ExecutorA,TaskD分配给ExecutorB,但是因为每个Executor只有两个core,只能同时执行两个Task,所以ExecutorA能够执行TaskA和TaskB,但是TaskC就只能等着,尽管它在ExecutorA上执行的数据本地性是PROCESS_LOCAL,但是人家没有资源啊,于是TaskC就等啊等,但是等了一会儿它发现不太对劲,搞这个数据本地性不就是为了加快Task的执行速度以提高Stage的整体执行速度吗,我搁这里干等着可不能加快Stage的整体速度,我要看下边上有没有其它的Executor是闲着的,假设我在ExecutorA需要再排队10秒才能拿到core资源执行,拿到资源之后我需要执行30秒,那么我只需要找到一个其它的Executor,即使因为数据本地性不好但是如果我能够在40秒内执行完的话还是要比在这边继续傻等要快的,所以TaskC就给自己设定了一个时间,当超过n毫秒之后还等不到就放弃PROCESS_LOCAL级别,转而尝试NODE_LOCAL级别的Executor,然后它看到了ExecutorB,ExecutorB和ExecutorA在同一台机器上,只是两个不同的jvm,所以在ExecutorB上执行需要从ExecutorA上拉取数据,通过BlockManager的getRemote,底层通过BlockTransferService去把数据拉取过来,因为是在同一台机器上的两个进程之间使用socket数据传输,走的应该是回环地址,速度会非常快,所以对于这种数据存储在同一台机器上的不同Executor上因为降级导致的NODE_LOCAL的情况,理论上并不会比PROCESS_LOCAL慢多少,TaskC在ExecutorB上执行并不会比ExecutorA上执行慢多少。但是对于比如HDFS块存储在此节点所以将Task分配到此节点的情况导致的NODE_LOCAL,因为要跟HDFS交互,还要读取磁盘文件,涉及到了一些I/O操作,这种情况就会耗费较长时间,相比较于PROCESS_LOCAL级别就慢上不少了。
上面举的例子中提到了TaskC会等待一段时间,根据数据本地性不同,等待的时间间隔也不一致,不同数据本地性的等待时间设置参数:
spark.locality.wait:设置所有级别的数据本地性,默认是3000毫秒
spark.locality.wait.process:多长时间等不到PROCESS_LOCAL就降级,默认为${spark.locality.wait}
spark.locality.wait.node:多长时间等不到NODE_LOCAL就降级,默认为${spark.locality.wait}
spark.locality.wait.rack:多长时间等不到RACK_LOCAL就降级,默认为${spark.locality.wait}
总结一下数据延迟调度策略:当使用当前的数据本地性级别等待一段时间之后仍然没有资源执行时,尝试降低数据本地性级别使用更低的数据本地性对应的Executor执行,这个就是Task的延迟调度策略。
最后探讨一下什么样的Task可以针对数据本地性延迟调度的等待时间做优化?
如果Task的输入数据比较大,那么耗费在数据读取上的时间会比较长,一个好的数据本地性能够节省很长时间,所以这种情况下最好还是将延迟调度的降级等待时间调长一些。而对于输入数据比较小的,即使数据本地性不好也只是多花一点点时间,那么便不必在延迟调度上耗费太长时间。总结一下就是如果数据本地性对任务的执行时间影响较大的话就稍稍调高延迟调度的降级等待时间。
相关资料:
1. spark on yarn 中的延迟调度(delay scheduler)
.
Spark笔记之数据本地性(data locality)的更多相关文章
- spark读取hdfs数据本地性异常
在分布式计算中,为了提高计算速度,数据本地性是其中重要的一环. 不过有时候它同样也会带来一些问题. 一.问题描述 在分布式计算中,大多数情况下要做到移动计算而非移动数据,所以数据本地性尤其重要,因此我 ...
- spark读取hdfs数据本地性异常【转】
在分布式计算中,为了提高计算速度,数据本地性是其中重要的一环. 不过有时候它同样也会带来一些问题. 一.问题描述 在分布式计算中,大多数情况下要做到移动计算而非移动数据,所以数据本地性尤其重要,因此我 ...
- 【原】Spark数据本地性
Spark数据本地性 分布式计算系统的精粹在于移动计算而非移动数据,但是在实际的计算过程中,总存在着移动数据的情况,除非是在集群的所有节点上都保存数据的副本.移动数据,将数据从一个节点移动到另一个节点 ...
- Spark数据本地性
1.文件系统本地性 第一次运行时数据不在内存中,需要从HDFS上取,任务最好运行在数据所在的节点上: 2.内存本地性 第二次运行,数据已经在内存中,所有任务最好运行在该数据所在内存的节点上: 3.LR ...
- 【Spark笔记】Windows10 本地搭建单机版Spark开发环境
0x00 环境及软件 1.系统环境 OS:Windows10_x64 专业版 2.所需软件或工具 JDK1.8.0_131 spark-2.3.0-bin-hadoop2.7.tgz hadoop-2 ...
- [转载] Spark:大数据的“电光石火”
转载自http://www.csdn.net/article/2013-07-08/2816149 Spark已正式申请加入Apache孵化器,从灵机一闪的实验室“电火花”成长为大数据技术平台中异军突 ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本课主题 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- Spark:大数据的电花火石!
什么是Spark?可能你很多年前就使用过Spark,反正当年我四六级单词都是用的星火系列,没错,星火系列的洋名就是Spark. 当然这里说的Spark指的是Apache Spark,Apache Sp ...
随机推荐
- 3月web前端面试小结
说一下box-sizing的应用场景 box-sizing的属性值分为两个,border-box和content-box,其中, border-box:width=content+padding+bo ...
- 编码用命令执行的C语言词语统计程序
需求介绍 程序处理用户需求的模式为: wc.exe [parameter][filename] 在[parameter]中,用户通过输入参数与程序交互,需实现的功能如下: 1.基本功能 支持 -c ...
- Python爬虫实战:2017中国最好大学排名
抓取内容: 从最好大学网上抓取中国前10的大学排名.大学名称.总分,并数据格式左对齐. http://www.zuihaodaxue.cn/zuihaodaxuepaiming2017.html 首先 ...
- CMS垃圾收集器与G1收集器
1.CMS收集器 CMS收集器是一种以获取最短回收停顿时间为目标的收集器.基于“标记-清除”算法实现,它的运作过程如下: 1)初始标记 2)并发标记 3)重新标记 4)并发清除 初始标记.从新标记这两 ...
- Linux命令(六) 查看文件 cat tac more less tail
如果要查看文件,使用 cat less tac tail 和 more 中的任意一个即可. 1.cat 使用 cat 命令查看文件时会显示整个文件的内容,注意cat只能查看文本文件的内容,如 ...
- k8s kubectl edit 方式修改 nodeport 的端口
0. 买了一本 每天五分钟玩转 k8s 还有 刚才转帖的blog 里面有一个 kubectl edit 的语法能够在线更改端口号 ,之前一直没弄明白. 刚才做了下实验.发现很好用 这里记录一下. 1. ...
- KSOA单据保护表中Clientid解析为mac和ip
SELECT DISTINCT a.*,ISNULL(c.client_net_address,'') AS client_net_address FROM ( SELECT * ,),,) ) ), ...
- SQLServer将一个表的数据导入到另一个表
1.假如A表存在 insert into A(a,b,c) (select a,b,c from B) 2.假如A表不存在 select a,b,c into A from B 3.假如需要跨数据库 ...
- nestd事务如果报错了 则回滚到外部事物保存点 且外部事物如果没异常的话 会正常提交 nested事务并不会提交;如果外部事物报错了 内部事务会一同回滚
nestd事务如果报错了 则回滚到外部事物保存点 且外部事物如果没异常的话 会正常提交 nested事务并不会提交:如果外部事物报错了 内部事务会一同回滚
- JSP 获取真实IP地址的代码
[转载]JSP 获取真实IP地址的代码 JSP 获取真实IP地址的代码 在JSP里,获取客户端的IP地址的方法是:request.getRemoteAddr(),这种方法在大部分情况下都是有效的. ...