SQL Server中ORDER BY后面可以是表达式和子查询
假如SQL Server数据库中现在有Book表如下
CREATE TABLE [dbo].[Book](
[ID] [int] IDENTITY(1,1) NOT NULL,
[BookName] [nvarchar](50) NULL,
[BookDescription] [nvarchar](50) NULL,
[ISBN] [nvarchar](20) NULL,
[CreateTime] [datetime] NULL,
CONSTRAINT [PK_Book] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO ALTER TABLE [dbo].[Book] ADD CONSTRAINT [DF_Book_CreateTime] DEFAULT (getdate()) FOR [CreateTime]
有如下数据:
SET IDENTITY_INSERT [dbo].[Book] ON
GO
INSERT [dbo].[Book] ([ID], [BookName], [BookDescription], [ISBN], [CreateTime]) VALUES (1, N'Chinese', N'This is a very good Chinese book', N'', CAST(N'2018-10-17T15:25:18.450' AS DateTime))
GO
INSERT [dbo].[Book] ([ID], [BookName], [BookDescription], [ISBN], [CreateTime]) VALUES (2, N'English', N'English', N'', CAST(N'2018-10-17T15:25:18.457' AS DateTime))
GO
INSERT [dbo].[Book] ([ID], [BookName], [BookDescription], [ISBN], [CreateTime]) VALUES (3, N'Japanese', N'Japanese', N'', CAST(N'2018-10-17T15:25:18.473' AS DateTime))
GO
INSERT [dbo].[Book] ([ID], [BookName], [BookDescription], [ISBN], [CreateTime]) VALUES (4, N'Russian', N'Russian', N'', CAST(N'2018-10-17T15:25:18.483' AS DateTime))
GO
INSERT [dbo].[Book] ([ID], [BookName], [BookDescription], [ISBN], [CreateTime]) VALUES (5, N'Italian', N'Italian', N'', CAST(N'2018-10-17T15:25:18.493' AS DateTime))
GO
SET IDENTITY_INSERT [dbo].[Book] OFF
我们使用SELECT语句查询该表,如下所示:
SELECT *
FROM [dbo].[Book]
现在设想一个问题,我们如何根据[BookName]和[BookDescription]两列数据的联合值来对结果进行排序呢?
我想很多人都会想到用子查询,如下所示:
SELECT [ID],[BookName],[BookDescription],[ISBN],[CreateTime]
FROM
(
SELECT [ID],[BookName],[BookDescription],[ISBN],[CreateTime],[BookName]+N'#'+[BookDescription] AS [Combine]
FROM [dbo].[Book]
) AS T
ORDER BY [Combine]
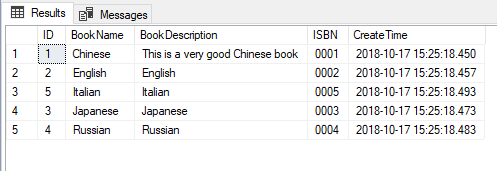
像上面这样用子查询的确没有问题,但是你知道吗,我们是可以直接在ORDER BY语句中写表达式的,如下所示:
SELECT *
FROM [dbo].[Book]
ORDER BY [BookName]+N'#'+[BookDescription]
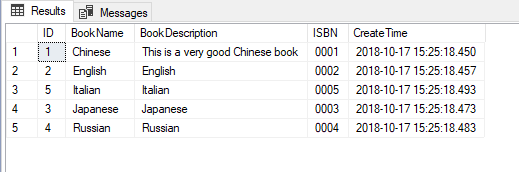
结果和用子查询完全一样
我们也可以在ORDER BY中使用多个表达式和列来对结果进行排序,甚至我们可以根据一个子查询来对结果进行排序,如下所示:
SELECT *
FROM [dbo].[Book]
ORDER BY [BookName]+N'#'+[BookDescription] ASC,
(SELECT TOP 1 R_BOOK.[ISBN] FROM [dbo].[Book] AS R_BOOK WHERE R_BOOK.[BookName]=[BookName]) DESC, --这里的子查询只能返回一行和一列数据,否则SQL Server会报错
[CreateTime] ASC
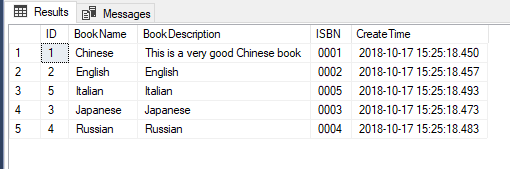
但是ORDER BY后面不能是常量,比如下面这样我们在ORDER BY后面跟一个字符串常量是不行的:
SELECT *
FROM [dbo].[Book]
ORDER BY N'Constant'
执行该语句会报错:
Msg 408, Level 16, State 1, Line 3
A constant expression was encountered in the ORDER BY list, position 1.
SQL Server中ORDER BY后面可以是表达式和子查询的更多相关文章
- SQL Server中order by的使用,我们来填坑
看似很简单是不是? 单列排序,没有任何问题 select * from tableA where age>1 order by age /*后面可以跟上ASC.DESC,默认是ASC升序排列*/ ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- SQL SERVER中LIKE使用变量类型输出结果不同
前言:Sql Server中LIKE里面使用不同的变量类型导致查询结果不一致的问题,其实看似有点让人不解的现象背后实质跟数据类型的实现有关. 一.我们先来创建示例演示具体操作 CREATE TABLE ...
- SQL Server中TOP子句可能导致的问题以及解决办法
简介 在SQL Server中,针对复杂查询使用TOP子句可能会出现对性能的影响,这种影响可能是好的影响,也可能是坏的影响,针对不同的情况有不同的可能性. 关系数据库中SQL语句只 ...
- SQL Server中行列转换 Pivot UnPivot
SQL Server中行列转换 Pivot UnPivot PIVOT用于将列值旋转为列名(即行转列),在SQL Server 2000可以用聚合函数配合CASE语句实现 PIVOT的一般语法是:PI ...
- SQL Server中的窗口函数
简介 SQL Server 2012之后对窗口函数进行了极大的加强,但对于很多开发人员来说,对窗口函数却不甚了解,导致了这样强大的功能被浪费,因此本篇文章主要谈一谈SQL Server中窗口函 ...
- SQL Server中CTE的另一种递归方式-从底层向上递归
SQL Server中的公共表表达式(Common Table Expression,CTE)提供了一种便利的方式使得我们进行递归查询.所谓递归查询方便对某个表进行不断的递归从而更加容易的获得 ...
- 浅谈SQL Server中的三种物理连接操作
简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge J ...
- 谈一谈SQL Server中的执行计划缓存(上)
简介 我们平时所写的SQL语句本质只是获取数据的逻辑,而不是获取数据的物理路径.当我们写的SQL语句传到SQL Server的时候,查询分析器会将语句依次进行解析(Parse).绑定(Bind).查询 ...
随机推荐
- JVM 运行时数据区详解
一.运行时数据区 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同数据区域. 1.有一些是随虚拟机的启动而创建,随虚拟机的退出而销毁,所有的线程共享这些数据区. 2.第二种则 ...
- 配置Codis-FE(管理界面)
codis所有的配置项可以有两种方式进行管理:通过图形界面进行配置,另外一种通过命令配置. 1.通过配置文件生成codis-fe的启动文件a.通过codis的管理工具完成:/usr/local/cod ...
- 前端组件化Polymer深入篇(1)
在前面的几节里面简单的介绍了一下Polymer的基本功能,但还有一些细节的东西并没有讨论,所有打算花点时间把Polymer的一些细节写一下. new和createElement有区别吗? <sc ...
- 一次完整的HTTP接口请求过程及针对优化
客户端发起http请求,基本的经历过程如下: 域名解析 -> TCP三次握手 -> 建立TCP连接后发起HTTP请求 -> Nginx反向代理 -> 应用层 -> 服务层 ...
- Ceph 块设备 - 块设备快速入门
目录 一.准备工作 二.安装 Ceph 三.使用块存储 一.准备工作 本文描述如何安装 ceph 客户端,使用 Ceph 块设备 创建文件系统并挂载使用. 必须先完成 ceph 存储集群的搭建,并 ...
- winDBG排错小记
去年底,公司一个上线了近一年的系统逐渐出现访问缓慢,操作超时的问题.本人使用winDBG工具对抓下来的内存映象进行了诊断,虽最后没有查出什么原因,但在过程中也学到了不少东西,现记录如下 一. “Fai ...
- Spring事务传播属性介绍(二).mandatory、not_supported、never、supports
Required.Required_New传播属性分析传送门:https://www.cnblogs.com/lvbinbin2yujie/p/10259897.html Nested传播属性分析传送 ...
- Eclipse 处理 IOConsole Updater 报错
上篇博文说了如何处理 Eclipse Console打印不自动删除问题, 而不让日志自动删除后会报错:IOConsole Updater 重复的刷屏,一会之后,就会出现IOConsole Update ...
- C# 装箱与拆箱转换
一.装箱转换(boxing) 装箱时一种隐式转换,它接受值类型的值,根据这个值在堆上创建一个完整的引用类型类型对象并返回对象引用,简单来说就是将值类型转换为引用类型 任何值类型ValueType都可以 ...
- UVa 12657 Boxes in a Line(数组模拟双链表)
题目链接 /* 问题 将一排盒子经过一系列的操作后,计算并输出奇数位置上的盒子标号之和 解题思路 由于数据范围很大,直接数组模拟会超时,所以采用数组模拟的链表,left[i]和right[i]分别表示 ...