libco协程库上下文切换原理详解
缘起
libco 协程库在单个线程中实现了多个协程的创建和切换。按照我们通常的编程思路,单个线程中的程序执行流程通常是顺序的,调用函数同样也是 “调用——返回”,每次都是从函数的入口处开始执行。而libco 中的协程却实现了函数执行到一半时,切出此协程,之后可以回到函数切出的位置继续执行,即函数的执行可以被“拦腰斩断”,这种在函数任意位置 “切出——恢复” 的功能是如何实现的呢? 本文从libco 代码层面对协程的切换进行了剖析,希望能让初次接触 libco 的同学能快速了解其背后的运行机理。
函数调用与协程切换的区别
下面的程序是我们常规调用函数的方法:
void A() {
cout << 1 << " ";
cout << 2 << " ";
cout << 3 << " ";
}
void B() {
cout << "x" << " ";
cout << "y" << " ";
cout << "z" << " ";
}
int main(void) {
A();
B();
}
在单线程中,上述函数的输出为:
1 2 3 x y z
如果我们用 libco 库将上面程序改造一下:
void A() {
cout << 1 << " ";
cout << 2 << " ";
co_yield_ct(); // 切出到主协程
cout << 3 << " ";
}
void B() {
cout << "x" << " ";
co_yield_ct(); // 切出到主协程
cout << "y" << " ";
cout << "z" << " ";
}
int main(void) {
... // 主协程
co_resume(A); // 启动协程 A
co_resume(B); // 启动协程 B
co_resume(A); // 从协程 A 切出处继续执行
co_resume(B); // 从协程 B 切出处继续执行
}
同样在单线程中,改造后的程序输出如下:
1 2 x 3 y z
可以看出,切出操作是由 co_yield_ct() 函数实现的,而协程的启动和恢复是由 co_resume 实现的。函数 A() 和 B() 并不是一个执行完才执行另一个,而是产生了 “交叉执行“ 的效果,那么,在单个线程中,这种 ”交叉执行“,是如何实现的呢?
Read the f**king source code!
Talk is cheap, show me code.
下面我们就深入 libco 的代码来看一下,协程的切换是如何实现的。通过分析代码看到,无论是 co_yield_ct() 还是 co_resume,在协程切出和恢复时,都调用了同一个函数co_swap,在这个函数中调用了 coctx_swap 来实现协程的切换,这一函数的原型是:
void coctx_swap( coctx_t *,coctx_t* ) asm("coctx_swap");
两个参数都是 coctx_t *指针类型,其中第一个参数表示要切出的协程,第二个参数表示切出后要进入的协程。
在上篇文章 “x86-64 下函数调用及栈帧原理” 中已经指出,调用子函数时,父函数会把两个调用参数放入了寄存器中,并且把返回地址压入了栈中。即在进入 coctx_swap 时,第一个参数值已经放到了 %rdi 寄存器中,第二个参数值已经放到了 %rsi 寄存器中,并且栈指针 %rsp 指向的位置即栈顶中存储的是父函数的返回地址。进入 coctx_swap 后,堆栈的状态如下:
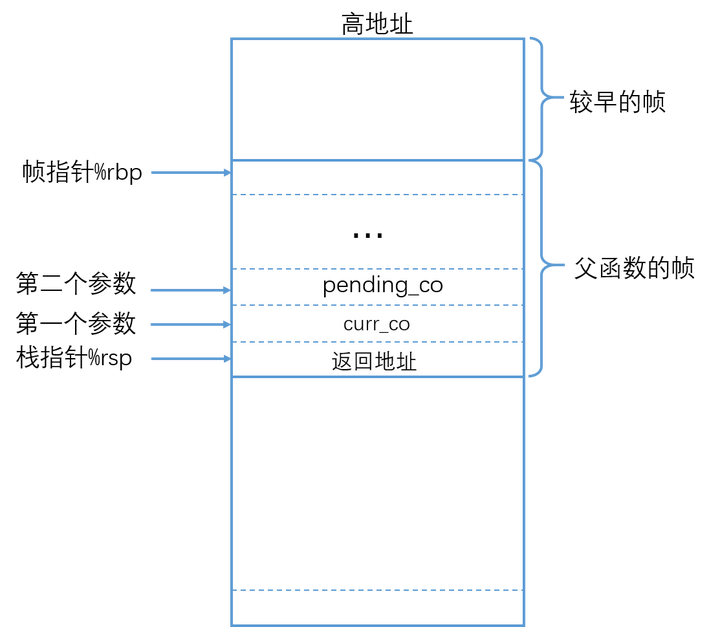
由于coctx_swap 是在 co_swap() 函数中调用的,下面所提及的协程的返回地址就是 co_swap() 中调用 coctx_swap() 之后下一条指令的地址:
void co_swap(stCoRoutine_t* curr, stCoRoutine_t* pending_co) {
....
// 从本协程切出
coctx_swap(&(curr->ctx),&(pending_co->ctx) );
// 此处是返回地址,即协程恢复时开始执行的位置
stCoRoutineEnv_t* curr_env = co_get_curr_thread_env();
....
}
coctx_swap 函数是用汇编实现的,我们这里只关注 x86-64 相关的部分,其代码如下:
coctx_swap:
leaq 8(%rsp),%rax
leaq 112(%rdi),%rsp
pushq %rax
pushq %rbx
pushq %rcx
pushq %rdx
pushq -8(%rax) //ret func addr
pushq %rsi
pushq %rdi
pushq %rbp
pushq %r8
pushq %r9
pushq %r12
pushq %r13
pushq %r14
pushq %r15
movq %rsi, %rsp
popq %r15
popq %r14
popq %r13
popq %r12
popq %r9
popq %r8
popq %rbp
popq %rdi
popq %rsi
popq %rax //ret func addr
popq %rdx
popq %rcx
popq %rbx
popq %rsp
pushq %rax
xorl %eax, %eax
ret
可以看出,coctx_swap 中并未像常规被调用函数一样创立新的栈帧。先看前两条语句:
leaq 8(%rsp),%rax
leaq 112(%rdi),%rsp
leaq 用于把其第一个参数的值赋值给第二个寄存器参数。第一条语句用来把 8(%rsp) 的本身的值存入到 %rax 中,注意这里使用的并不是 8(%rsp) 指向的值,而是把 8(%rsp) 表示的地址赋值给了 %rax。这一地址是父函数栈帧中除返回地址外栈帧顶的位置。
在第二条语句 leaq 112(%rdi), %rsp 中,%rdi 存放的是coctx_swap 第一个参数的值,这一参数是指向 coctx_t 类型的指针,表示当前要切出的协程,这一类型的定义如下:
struct coctx_t {
void *regs[ 14 ];
size_t ss_size;
char *ss_sp;
};
因而 112(%rdi) 表示的就是第一个协程的 coctx_t 中 regs[14] 数组的下一个64位地址。而接下来的语句:
pushq %rax
pushq %rbx
pushq %rcx
pushq %rdx
pushq -8(%rax) //ret func addr
pushq %rsi
pushq %rdi
pushq %rbp
pushq %r8
pushq %r9
pushq %r12
pushq %r13
pushq %r14
pushq %r15
第一条语句 pushq %rax 用于把 %rax 的值放入到 regs[13] 中,resg[13] 用来存储第一个协程的 %rsp 的值。这时 %rax 中的值是第一个协程 coctx_swap 父函数栈帧除返回地址外栈帧顶的地址。由于 regs[] 中有单独的元素存储返回地址,栈中再保存返回地址是无意义的,因而把父栈帧中除返回地址外的栈帧顶作为要保存的 %rsp 值是合理的。当协程恢复时,把保存的 regs[13] 的值赋值给 %rsp 即可恢复本协程 coctx_swap 父函数堆栈指针的位置。第一条语句之后的语句就是用pushq 把各CPU 寄存器的值依次从 regs 尾部向前压入。即通过调整%rsp 把 regs[14] 当作堆栈,然后利用 pushq 把寄存器的值和返回地址存储到 regs[14] 整个数组中。regs[14] 数组中各元素与其要存储的寄存器对应关系如下:
//-------------
// 64 bit
//low | regs[0]: r15 |
// | regs[1]: r14 |
// | regs[2]: r13 |
// | regs[3]: r12 |
// | regs[4]: r9 |
// | regs[5]: r8 |
// | regs[6]: rbp |
// | regs[7]: rdi |
// | regs[8]: rsi |
// | regs[9]: ret | //ret func addr, 对应 rax
// | regs[10]: rdx |
// | regs[11]: rcx |
// | regs[12]: rbx |
//hig | regs[13]: rsp |
接下来的汇编语句:
movq %rsi, %rsp
popq %r15
popq %r14
popq %r13
popq %r12
popq %r9
popq %r8
popq %rbp
popq %rdi
popq %rsi
popq %rax //ret func addr
popq %rdx
popq %rcx
popq %rbx
popq %rsp
这里用的方法还是通过改变%rsp 的值,把某块内存当作栈来使用。第一句 movq %rsi, %rsp 就是让%rsp 指向 coctx_swap 第二个参数,这一参数表示要进入的协程。而第二个参数也是coctx_t 类型的指针,即执行完 movq 语句后,%rsp 指向了第二个参数 coctx_t 中 regs[0],而之后的pop 语句就是用 regs[0-13] 中的值填充cpu 的寄存器,这里需要注意的是popq 会使得 %rsp 的值增加而不是减少,这一点保证了会从 regs[0] 到regs[13] 依次弹出到 cpu 寄存器中。在执行完最后一句 popq %rsp 后,%rsp 已经指向了新协程要恢复的栈指针(即新协程之前调用 coctx_swap 时父函数的栈帧顶指针),由于每个协程都有一个自己的栈空间,可以认为这一语句使得%rsp 指向了要进入协程的栈空间。
coctx_swap 中最后三条语句如下:
pushq %rax
xorl %eax, %eax
ret
pushq %rax 用来把 %rax 的值压入到新协程的栈中,这时 %rax 是要进入的目标协程的返回地址,即要恢复的执行点。然后用 xorl 把 %rax 低32位清0以实现地址对齐。最后ret 语句用来弹出栈的内容,并跳转到弹出的内容表示的地址处,而弹出的内容正好是上面 pushq %rax 时压入的 %rax 的值,即之前保存的此协程的返回地址。即最后这三条语句实现了转移到新协程返回地址处执行,从而完成了两个协程的切换。可以看出,这里通过调整%rsp 的值来恢复新协程的栈,并利用了 ret 语句来实现修改指令寄存器 %rip 的目的,通过修改 %rip 来实现程序运行逻辑跳转。注意%rip 的值不能直接修改,只能通过 call 或 ret 之类的指令来间接修改。
整体上看来,协程的切换其实就是cpu 寄存器内容特别是%rip 和 %rsp 的写入和恢复,因为cpu 的寄存器决定了程序从哪里执行(%rip) 和使用哪个地址作为堆栈 (%rsp)。寄存器的写入和恢复如下图所示:
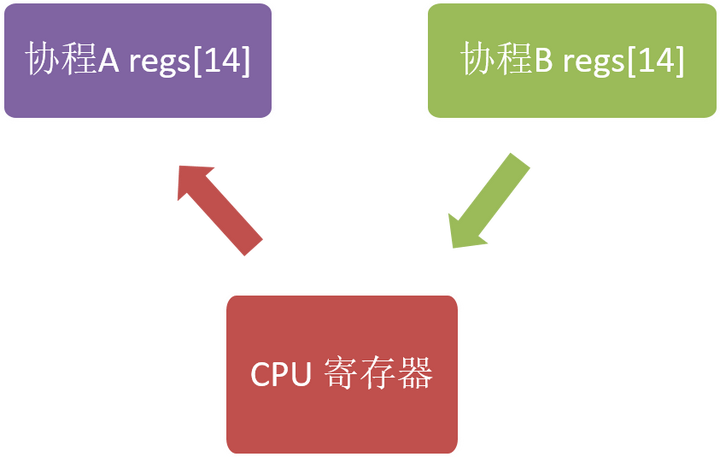
执行完上图的流程,就将之前 cpu 寄存器的值保存到了协程A 的 regs[14] 中,而将协程B regs[14] 的内容写入到了寄存器中,从而使执行逻辑跳转到了 B 协程 regs[14] 中保存的返回地址处开始执行,即实现了协程的切换(从A 协程切换到了B协程执行)。
结语
为实现单线程中协程的切换,libco 使用汇编直接读写了 cpu 的寄存器。由于通常我们在高级语言层面很少接触上下文切换的情形,因而会觉得在单线程中切换上下文的方法会十分复杂,但当我们对代码抽丝剥茧后,发现其实现机理也是很容易理解的。从libco 上下文切换中可以看出,用汇编与 cpu 硬件寄存器配合竟然可以设计出如此神奇的功能,不得不惊叹于 cpu 硬件设计的精妙。
libco 库的说明中提及这种上下文切换的方法取自 glibc,看来基础库中隐藏了不少 “屠龙之技”。
看来,想要提高编程技能,无他,Read the f**king source code !
The End.
https://zhuanlan.zhihu.com/p/27409164
libco协程库上下文切换原理详解的更多相关文章
- Kotlin协程作用域与Job详解
Job详解: 在上一次https://www.cnblogs.com/webor2006/p/11725866.html中抛出了一个问题: 所以咱们将delay去掉,需要改造一下,先把主线程的dela ...
- libco协程原理简要分析
此文简要分析一下libco协程的关键原理. 在分析前,先简单过一些协程的概念,以免有新手误读了此篇文章. 协程是用户态执行单元,它的创建,执行,上下文切换,挂起,销毁都是在用户态中完成,对linux系 ...
- C高级 跨平台协程库
1.0 协程库引言 协程对于上层语言还是比较常见的. 例如C# 中 yield retrun, lua 中 coroutine.yield 等来构建同步并发的程序. 本文就是探讨如何从底层实现开发级别 ...
- Android中的Coroutine协程原理详解
前言 协程是一个并发方案.也是一种思想. 传统意义上的协程是单线程的,面对io密集型任务他的内存消耗更少,进而效率高.但是面对计算密集型的任务不如多线程并行运算效率高. 不同的语言对于协程都有不同的实 ...
- 协程库st(state threads library)原理解析
协程库state threads library(以下简称st)是一个基于setjmp/longjmp实现的C语言版用户线程库或协程库(user level thread). 这里有一个基本的协程例子 ...
- 写个百万级别full-stack小型协程库——原理介绍
其实说什么百万千万级别都是虚的,下面给出实现原理和测试结果,原理很简单,我就不上图了: 原理:为了简单明了,只支持单线程,每个协程共享一个4K的空间(你可以用堆,用匿名内存映射或者直接开个数组也都是可 ...
- 协程概念,原理及实现(c++和node.js实现)
协程 什么是协程 wikipedia 的定义: 协程是一个无优先级的子程序调度组件,允许子程序在特点的地方挂起恢复. 线程包含于进程,协程包含于线程.只要内存足够,一个线程中可以有任意多个协程,但某一 ...
- TOMCAT原理详解及请求过程(转载)
转自https://www.cnblogs.com/hggen/p/6264475.html TOMCAT原理详解及请求过程 Tomcat: Tomcat是一个JSP/Servlet容器.其作为Ser ...
- LVS原理详解(3种工作模式及8种调度算法)
2017年1月12日, 星期四 LVS原理详解(3种工作模式及8种调度算法) LVS原理详解及部署之二:LVS原理详解(3种工作方式8种调度算法) 作者:woshiliwentong 发布日期: ...
随机推荐
- Android.mk 中常用“LOCAL_” 变量
编写模块的编译文件,实际就是定义一系列以“LOCAL_”开头的编译变量,因此我们有必要弄明白这些变量的具体含义.下面是一些经常使用的LOCAL_编译变量的说明: 变量名 说明 LOCAL_ASSET_ ...
- windows下nodejs监听80端口
windows下nodejs监听80端口时提示端口被占用报错,解决方案如下: 1.cmd---netstat -ano查看是什么程序占用了80端口: 2.控制面板--管理工具--服务--停止 SQL ...
- PHP中按值传递和引用传递的区别
有次跟朋友讨论对象传值的方式时提到引用传值时,在大脑中搜索五秒钟,果断确定在这两个项目当中并没有用到.今天去问了一下度娘,顺便做了个小测试: 按值传递: 引用传递: 按值传递中原来参数的值在调用其他函 ...
- 【代码笔记】iOS-UIAlertView3秒后消失
一,效果图. 二,代码. - (void)viewDidLoad { [super viewDidLoad]; // Do any additional setup after loading the ...
- 【读书笔记】iOS-网络-理解错误源
考虑一个字节是如何从设备发往运程服务器以及如何从远程服务器将这个字节接收到设备,这个过程只需要几百毫秒时间,不过确要求网络设备都能正常工作才行.设备网络和网络互联的复杂性导致了分层网络的产生.分层网络 ...
- easyui+webuploader+ckeditor实现插件式多图片上传-添加图片权限(图片上传人是谁,只能看到自己的图片)
需求: 实现过程及思路 1.先页面布局 <html xmlns="http://www.w3.org/1999/xhtml"> <head runat=" ...
- Kubernetes+Docker的云平台在CentOS7系统上的安装
Kubernetes+Docker的云平台在CentOS7系统上的安装 1.运行VirtualBox5. 2.安装CentOS7系统. 注意:选择Basic Server类型 安装过程略. 3.修改计 ...
- 语义SLAM的数据关联和语义定位(四)多目标测量概率模型
多目标模型 这部分想讲一下Semantic Localization Via the Matrix Permanent这篇文章的多目标测量概率模型.考虑到实际情况中,目标检测算法从单张图像中可能检测出 ...
- Flutter 数据模型创建
build_runner的使用 1.在根目录运行 2.一次性创建.g.dart文件 使用build 此时目录内不能有.g.dart文件 3.watch是监听 有model类的文件创建 自动创建.g.d ...
- Fit项目分页组件的编写
项目中涉及列表显示的地方都会用到分页控件,为了能更好地与当前网站的样式匹配,这次要自己实现一个. 所以选择了模板中提供的分页样式,基于模板改造以能够动态生成: 一 控件的行为规则 a) 可设置显示几个 ...