【论文阅读】Learning Spatial Regularization with Image-level Supervisions for Multi-label Image Classification
转载请注明出处:https://www.cnblogs.com/White-xzx/
原文地址:https://arxiv.org/abs/1702.05891
Caffe-code:https://github.com/zhufengx/SRN_multilabel
如有不准确或错误的地方,欢迎交流~
空间正则化网络(Spatial Regularization Network, SRN),学习所有标签间的注意力图(attention maps),并通过可学习卷积挖掘标签间的潜在关系,结合正则化分类结果和 ResNet-101 网络的分类结果,以提高图像分类表现。
【SRN的优势】
(1)挖掘图像多标签之间的语义和空间关联性,较大地提高精度;
(2)当网络模型对具有空间相关标签的图片训练后,注意力机制自适应地关注图像的相关区域
(3)图像级标注,端到端训练

【SRN网络结构】
(1)Main Net:ResNet-101,针对各标签分别学习得到独立的分类器。“Res-2048” 表示具有2048输出的 ResNet 网络模块;
(2)SRN 采用ResNet-101的视觉特征作为输入,利用注意力机制学习得到标签间的正则空间关系;
(3)结合主网络和SRN的分类结果得到最终的分类置信度;
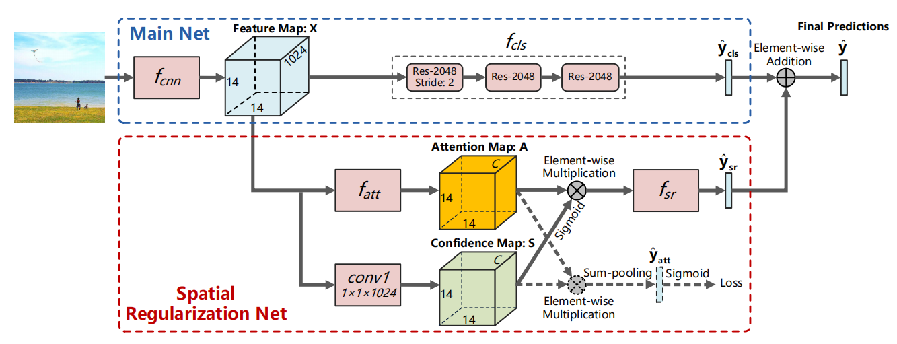
【Main Net】
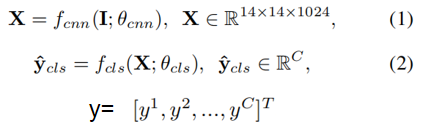


【SRN:注意力机制 fatt(·)】
当图像存在某个标签时,更多的注意力应该放在相关的区域,标签注意力图编码了标签对应的丰富空间信息。l被标记则l相关区域的注意力值应该更高
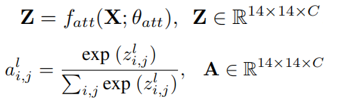

注意力图能用于产生更鲁棒的空间正则信息,但每个标签的注意力图总是和为1,可能会突出错误位置,造成错误的空间正则信息,论文提出使用加权注意力图U,U解码了标签局部和全局的置信分数(confidence)。

【SRN:fsr(·)结构】
conv2、conv3多通道,512输出,捕捉多标签的语义关系;
conv4单通道,2048输出,4个kernel为一组缠绕1个相同的特征通道,不同kernel捕捉语义关联标签间的不同空间关系。

【Multiple Steps 分步训练】
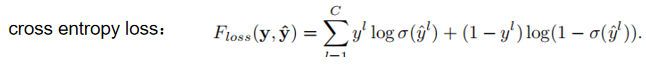
分四个阶段: ①只训练主网络, 基于 ResNet,pretrained on ImageNet,fcnn 和 fcls;
②固定 fcnn 和 fcls, 训练 fatt;
③固定 fcnn, fcls和 fatt,训练 fsr;
④联合训练整个网络。
图像增强策略: ①resize为256×256
②裁剪4个角和中心区域,长宽在{256,224,192,168,128}中随机选取
③resize为224×224
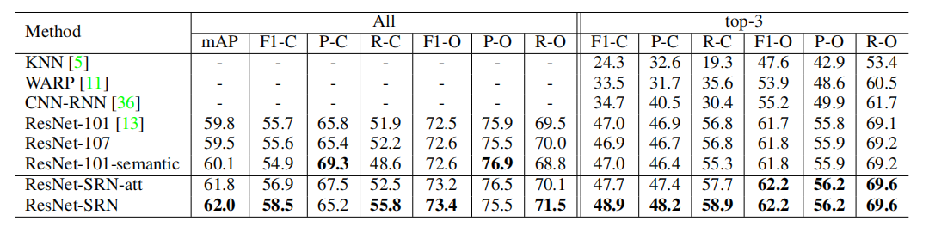
【实验结果】


【论文阅读】Learning Spatial Regularization with Image-level Supervisions for Multi-label Image Classification的更多相关文章
- Learning Spatial Regularization with Image-level Supervisions for Multi-label Image Classification
- 论文阅读笔记(十七)【ICCV2017】:Dynamic Label Graph Matching for Unsupervised Video Re-Identification
Introduction 文章主要提出了 Dynamic Graph Matching(DGM)方法,以非监督的方式对多个相机的行人视频中识别出正确匹配.错误匹配的结果.本文主要思想如下图: 具体而言 ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文阅读:Face Recognition: From Traditional to Deep Learning Methods 《人脸识别综述:从传统方法到深度学习》
论文阅读:Face Recognition: From Traditional to Deep Learning Methods <人脸识别综述:从传统方法到深度学习> 一.引 ...
- 【论文阅读】Learning Dual Convolutional Neural Networks for Low-Level Vision
论文阅读([CVPR2018]Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision) 本文针对低 ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- [论文阅读笔记] node2vec Scalable Feature Learning for Networks
[论文阅读笔记] node2vec:Scalable Feature Learning for Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 由于DeepWal ...
- [论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks
[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问 ...
随机推荐
- Easy-UI开发总结
Easy-UI开发总结 jQuery EasyUI 简介 jQuery EasyUI 是一个基于 jQuery 的框架,集成了各种用户界面插件. 什么是 jQuery EasyUI jQuery Ea ...
- 【刷题】LOJ 6004 「网络流 24 题」圆桌聚餐
题目描述 假设有来自 \(n\) 个不同单位的代表参加一次国际会议.每个单位的代表数分别为 \(r_i\) .会议餐厅共有 \(m\) 张餐桌,每张餐桌可容纳 \(c_i\) 个代表就餐. 为了使 ...
- 数位DP学习笔记
数位DP学习笔记 什么是数位DP? 数位DP比较经典的题目是在数字Li和Ri之间求有多少个满足X性质的数,显然对于所有的题目都可以这样得到一些暴力的分数 我们称之为朴素算法: for(int i=l_ ...
- PHP使用serialize和json_encode序列化数据并通过redis缓存文件和$GLOGALS缓存资源对象
PHP常用缓存方式:第一种,把需要缓存的数据进行处理,形成PHP可以直接执行的文件.在需要缓存数据的时候,通过include方式引入,并使用.第二种,把需要的数据通过serialize函数序列化后直接 ...
- 3: $.ajax()方法详解
1.url: 要求为String类型的参数,(默认为当前页地址)发送请求的地址. 2.type: 要求为String类型的参数,请求方式(post或get)默认为get.注意其他http请求方法,例如 ...
- ubuntu下sublime Text3配置C++编译环境
今天在Ubuntu下用sublime Text3编译C++代码,环境配的不太顺利,下边展示一个实例. 1.主函数main.cpp #include <iostream> #include ...
- logstash marking url as dead 问题解决
具体问题如下图所示: 将 INFO 信息打印大致如下所示: [2018-03-05T16:26:08,711][INFO ][logstash.setting.writabledirectory] C ...
- centos安装lrzsz
yum -y install lrzsz 使用rz打开上传框
- ASP.Net巧用窗体母版页
背景:每个网页的基本框架结构类似: 浏览网站的时候会发现,好多网站中,每个网页的基本框架都是一样的,比如,最上面都是网站的标题,中间是内容,最下面是网站的版权.开发提供商等信息: 在这些网页中,表头. ...
- 20155206 2016-2017-2 《Java程序设计》第7周学习总结
20155206 2016-2017-2 <Java程序设计>第7周学习总结 教材学习内容总结 认识时间与日期 1.格林威治时间(GMT):通过观察太阳而得,因为地球公转轨道为椭圆形且速度 ...