postgresql定位分析消耗CPU高的SQL语句
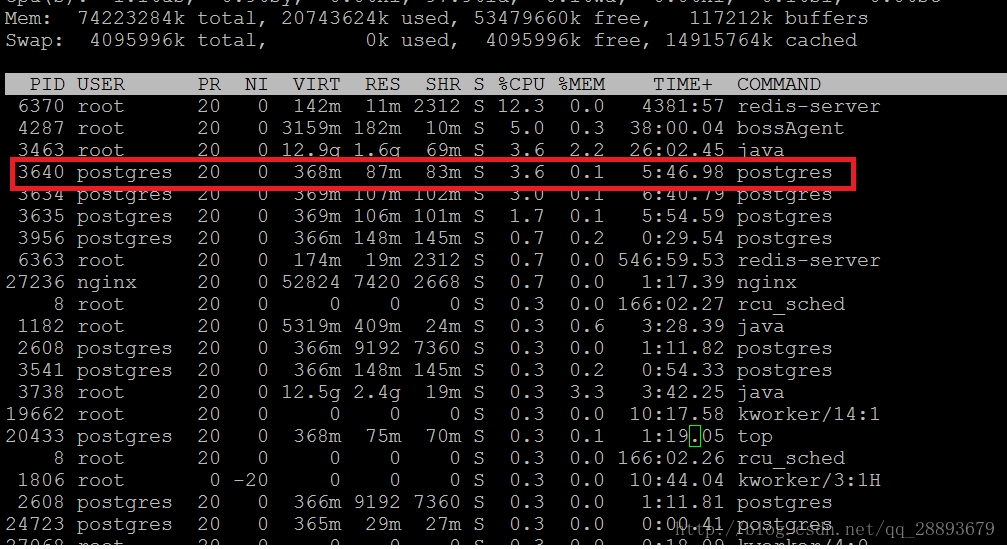
第一步:使用TOP命令查看占用CPU高的postgresql进程,并获取该进程的ID号,如图该id号为3640
第二步:切换到postgres用户,并且psql连接到数据库,执行如下查询语句
SELECT procpid, START, now() - START AS lap, current_query FROM ( SELECT backendid, pg_stat_get_backend_pid (S.backendid) AS procpid,
pg_stat_get_backend_activity_start (S.backendid) AS START,pg_stat_get_backend_activity (S.backendid) AS current_query FROM (SELECT
pg_stat_get_backend_idset () AS backendid) AS S) AS S WHERE current_query <> '<IDLE>' and procpid=25400 ORDER BY lap DESC;

procpid:进程id 如果不确认进程ID,将上面的条件去掉,可以逐条分析
start:进程开始时间
lap:经过时间
current_query:执行中的sql
怎样停止正在执行的sql :SELECT pg_cancel_backend(进程id);或者用系统函数
kill -9 进程id;
第三步:查看该sql的执行计划(使用explain analyze + sql语句的格式)
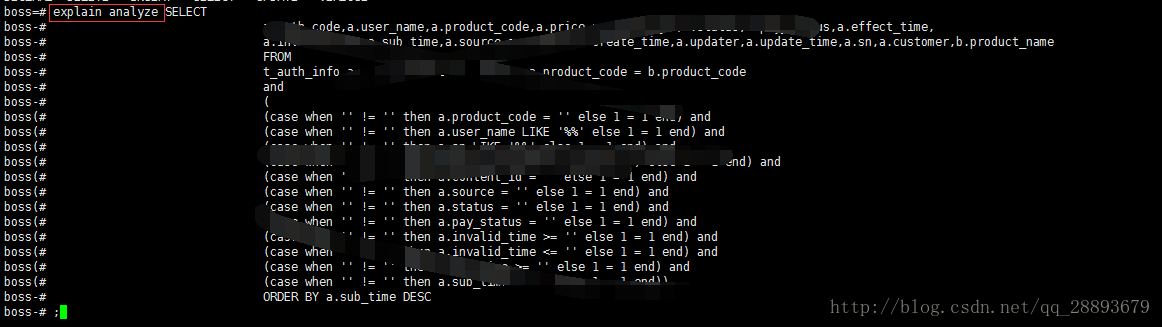
第四步:分析执行计划,本项目是由于该语句没有走索引,导致查询时间过长,具体原因可以查看执行计划来处理。如:

postgresql定位分析消耗CPU高的SQL语句的更多相关文章
- oracle 中如何定位重要(消耗资源多)的SQL
链接:http://www.xifenfei.com/699.html 标题:oracle 中如何定位重要(消耗资源多)的SQL 作者:惜分飞©版权所有[文章允许转载,但必须以链接方式注明源地址,否则 ...
- SQL Server中查询CPU占用高的SQL语句
SQL Server中查询CPU占用高的情况,会用到sys.sysprocesses ,dm_exec_sessions ,dm_exec_requests 一.查看当前的数据库用户连接有多少 USE ...
- 转载:SQL Server中查询CPU占用高的SQL语句
SQL Server中查询CPU占用高的SQL语句 SQL Server 表变量的用法 究竟什么是敏捷测试--朱少民
- SQL SERVER 占用资源高的SQL语句
--SQL SERVER 占用资源高的SQL语句: --查询占用cpu高的前 50 个 SQL 语句 SELECT total_cpu_time,[total_physical_Reads], tot ...
- Linux 下定位java应用 cpu高的原因(转)
使用场景: 遇到Linux下java应用cpu占用很高的时候,我们很想知道此时的应用到底在做什么导致资源的消耗. 方便我们进一步定位和优化~ 1.查询cpu耗用top5的进程(你也可以top10) [ ...
- oracle 中如何定位重要(消耗资源多)的SQL【转】
1.查看值得怀疑的SQL )||'%'load, s.executions executes, p.sql_text from(select address, disk_reads, executio ...
- 干货!SQL性能优化,书写高质量SQL语句
写SQL语句的时候我们往往关注的是SQL的执行结果,但是是否真的关注了SQL的执行效率,是否注意了SQL的写法规范? 以下的干货分享是在实际开发过程中总结的,希望对大家有所帮助! 1. limit分页 ...
- 查询总耗CPU最多与平均耗CPU最多的SQL语句
总耗CPU最多的前20个SQL total_worker_time AS [总消耗CPU 时间(ms)],execution_count [运行次数], qs.total_worker_time AS ...
- MySql定位执行效率较低的SQL语句
MySQL能够记录执行时间超过参数 long_query_time 设置值的SQL语句,默认是不记录的. 获得初始锁定的时间不算作执行时间.mysqld在SQL执行完和所有的锁都被释放后才写入日志.且 ...
随机推荐
- goreplay 输出流量捕获数据到 elasticsearch
goreplay 是一个很不错的流量拷贝,复制工具,小巧,支持一些扩展,当然也提供了企业版,企业版 功能更强大,支持二进制协议的分析 . 为了方便数据的存储,我们可以使用es 进行存储 环境准备 do ...
- nginx http2 push 试用
nginx 已经很早就支持http2,今天证书过期,重新申请了一个,同时测试下http2 的push 功能 环境准备 证书 这个结合自己的实际去申请,我使用免费的letsencrypt,支持泛域名证书 ...
- lua-resty-shell 多任务执行
已经写过一个openresty 使用lua-resty-shell 执行shell 脚本的demo,但是实际上我们可能是多节点运行, 同时需要负载均衡的机制. lua-resty-shell 支持un ...
- 为什么 PCB 生产时推荐出 Gerber 给工厂?
为什么 PCB 生产时推荐出 Gerber 给工厂? 事情是这样的,有一天电工王工,画了一块 PCB,发给 PCB 板厂. 过了几天 PCB 回来了,一看不对呀,这里的丝印怎么少了,那里怎么多了几条线 ...
- java BIO/NIO
一.BIO Blocking IO(即阻塞IO); 1. 特点: a) Socket服务端在监听过程中每次accept到一个客户端的Socket连接,就要处理这个请求,而此时其他连接过来 ...
- TypeScript 知识点
TypeScript 通过 类型批注 提供静态类型以在编译时启动类型检查. 基本批注类型是number.bool.string.而弱或动态类型是any. typescript 使用 作用 语句 全局安 ...
- Linux CentOS6升级glibc库过程
CentOS6升级glibc库过程 hadoop无法加载native库,可能原因是 glibc库版本过低,需要升级. 第一:安装以下软件 yum -y install zlib zlib-devel ...
- hadoop append 追加文件错误
java.io.IOException:Failed to replace a bad datanode on the existing pipeline due to no more good da ...
- Kafka研究【一】:bring up环境
kafka是干什么的,有和特性,我这里就不多说,详情自己研究官方文档. 0. 背景介绍 我需要在三台机器上分别部署kafka broker的实例,构建成一个集群.kafka的broker集群,是基于z ...
- Python 简说 list,tuple,dict,set
python 是按缩进来识别代码块的 . 缩进请严格按照Python的习惯写法:4个空格,不要使用Tab,更不要混合Tab和空格,否则很容易造成因为缩进引起的语法错误. list 有序集合 访问不 ...