leetcode133. 克隆图
给定无向连通图中一个节点的引用,返回该图的深拷贝(克隆)。图中的每个节点都包含它的值 val(Int) 和其邻居的列表(list[Node])。
示例: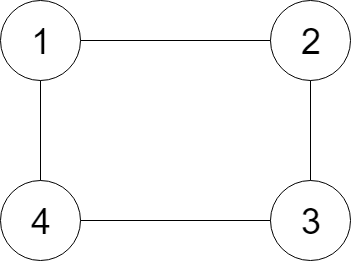
输入:
{"$id":"1","neighbors":[{"$id":"2","neighbors":[{"$ref":"1"},{"$id":"3","neighbors":[{"$ref":"2"},{"$id":"4","neighbors":[{"$ref":"3"},{"$ref":"1"}],"val":4}],"val":3}],"val":2},{"$ref":"4"}],"val":1}
解释:
节点 1 的值是 1,它有两个邻居:节点 2 和 4 。
节点 2 的值是 2,它有两个邻居:节点 1 和 3 。
节点 3 的值是 3,它有两个邻居:节点 2 和 4 。
节点 4 的值是 4,它有两个邻居:节点 1 和 3 。
提示:
节点数介于 1 到 100 之间。
无向图是一个简单图,这意味着图中没有重复的边,也没有自环。
由于图是无向的,如果节点 p 是节点 q 的邻居,那么节点 q 也必须是节点 p 的邻居。
必须将给定节点的拷贝作为对克隆图的引用返回。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/clone-graph
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解答:
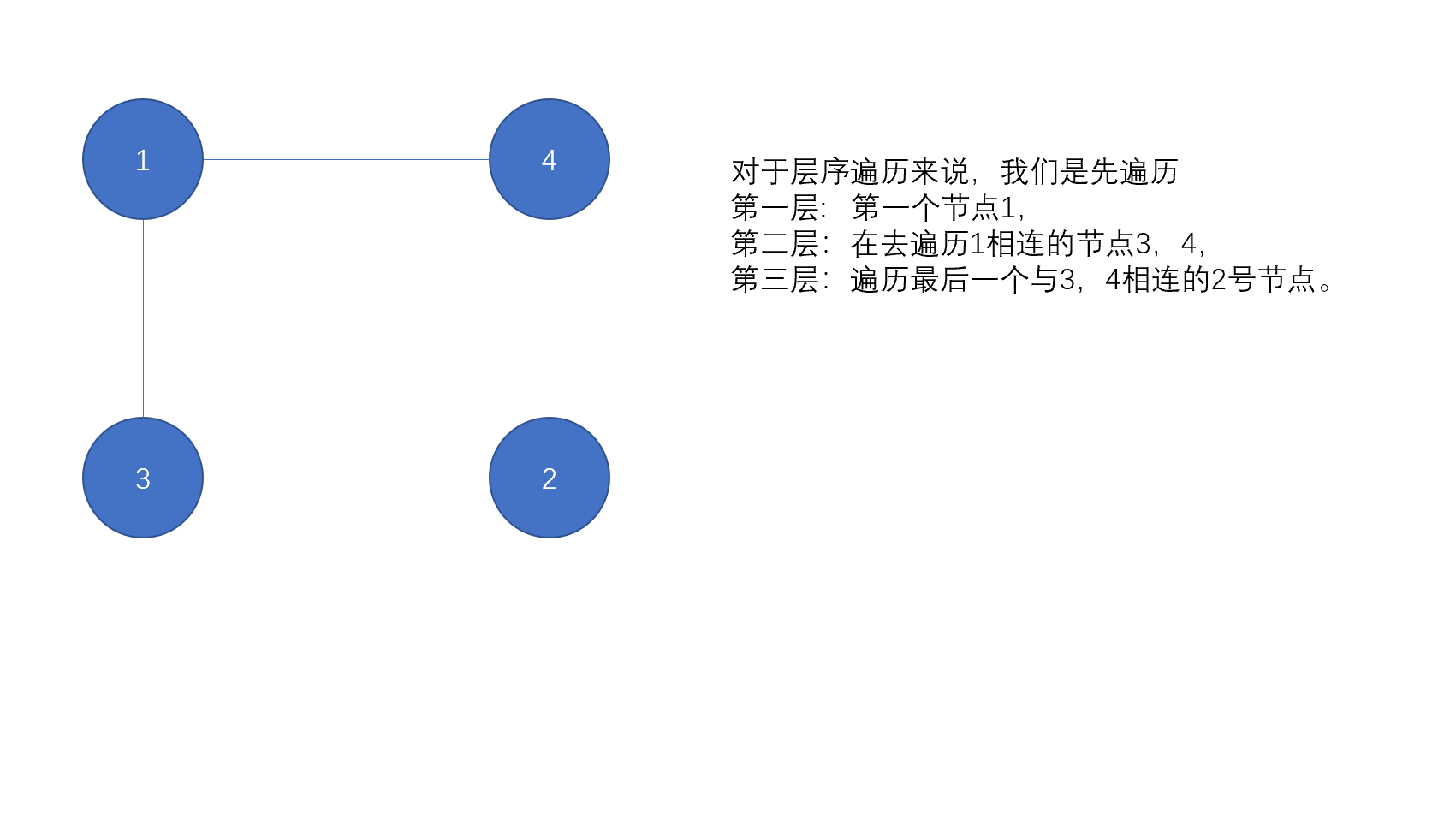
1bfs:层序遍历
在图的遍历中分为层序遍历和深度遍历,和树的遍历基本相同。使用一个hashmap保存所有遇到的节点,借助一个队列linkedlist来实现层序遍历。
1 /*
2 // Definition for a Node.
3 class Node {
4 public int val;
5 public List<Node> neighbors;
6
7 public Node() {}
8
9 public Node(int _val,List<Node> _neighbors) {
10 val = _val;
11 neighbors = _neighbors;
12 }
13 };
14 */
15 class Solution {
16 public Node cloneGraph(Node node) {
17 if(node==null)
18 return null;
19 HashMap<Node,Node> map=new HashMap<>();
20 LinkedList<Node> list=new LinkedList<>();
21 Node clone=new Node(node.val,new ArrayList<Node>());
22 map.put(node,clone);
23 list.add(node);
24 while(!list.isEmpty())
25 {
26 Node temp=list.remove();
27 for(Node n:temp.neighbors)
28 {
29 if(!map.containsKey(n))
30 {
31 Node next=new Node(n.val,new ArrayList<Node>());
32 map.put(n,next);
33 list.add(n);
34 }
35 map.get(temp).neighbors.add(map.get(n));
36 }
37
38 }
39 return clone;
40 }
41 }
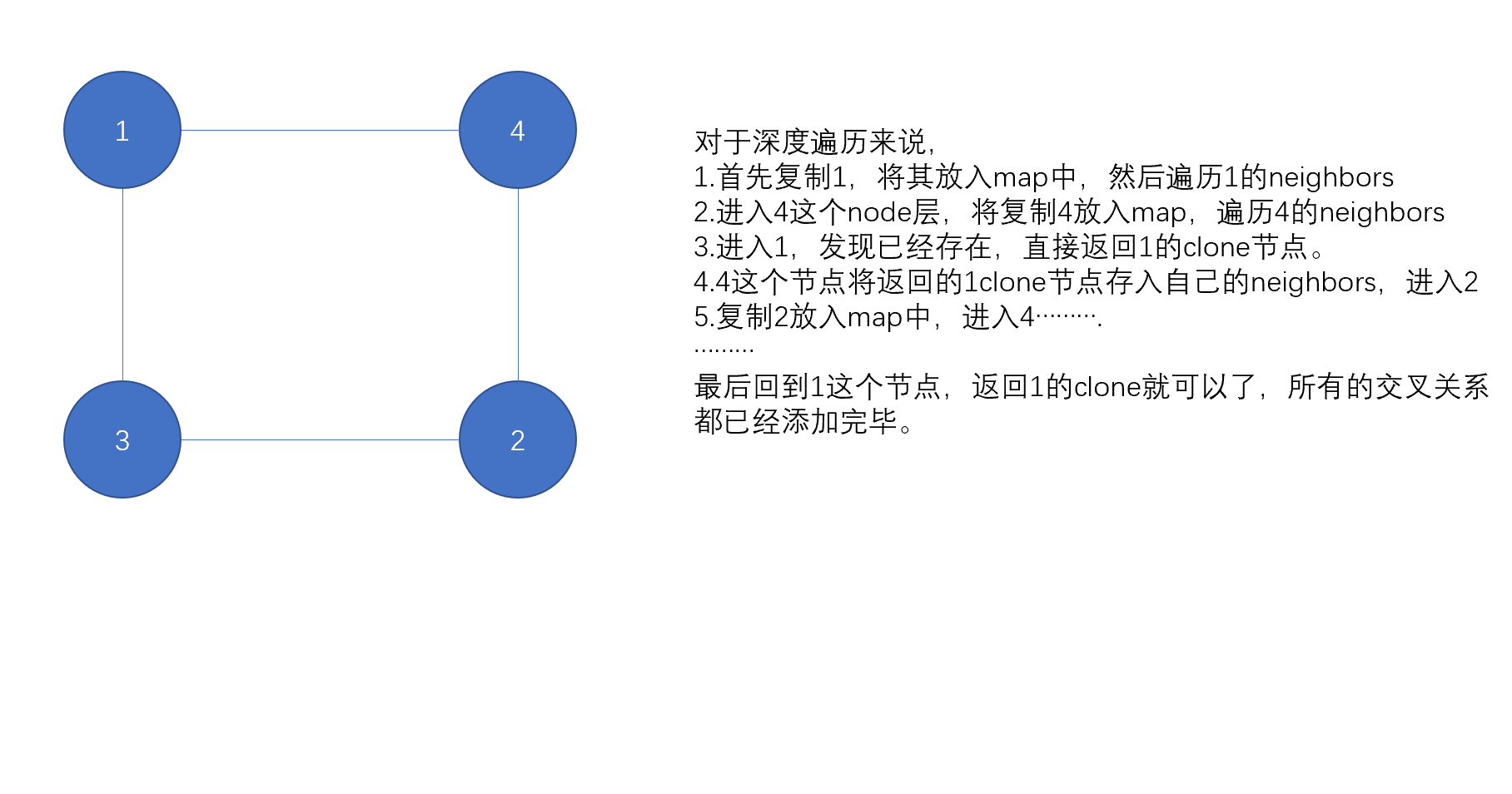
解法2:dfs深度遍历
对于深度遍历来说,依旧需要一个map保存已经创建过的node节点。每一层需要先判断map中是否已经有这个node,有的话就可以直接返回这个node的clone节点,不然需要创建clone节点返回。这道题就变成了递归,那么递归的三要素就需要好好考虑一下, 这里的结束条件应该就是每个节点的neighbors列表遍历完全以后,所以当完成遍历neighbors就返回,返回值是什么呢?因为在遍历的时候还要往复制的node节点里面添加node引用,所以返回值就是复制的node节点,比如说在遍历1的neighbors时遇到2,进入2,那么我们需要返回2的复制节点,这样在1这个节点才会有2的复制,才可以往1的复制节点里面添加2的复制节点。
1 /*
2 // Definition for a Node.
3 class Node {
4 public int val;
5 public List<Node> neighbors;
6
7 public Node() {}
8
9 public Node(int _val,List<Node> _neighbors) {
10 val = _val;
11 neighbors = _neighbors;
12 }
13 };
14 */
15 class Solution {
16 HashMap<Node,Node> map=new HashMap<>();
17 public Node cloneGraph(Node node) {
18 return dfs(node);
19 }
20 public Node dfs(Node node)
21 {
22 if(map.containsKey(node))
23 return map.get(node) ;
24 Node clone=new Node(node.val,new ArrayList<>());
25 map.put(node,clone);
26 for(Node n:node.neighbors)
27 {
28 Node temp=dfs(n);
29 clone.neighbors.add(temp);
30 }
31 return clone;
32 }
33 }
leetcode133. 克隆图的更多相关文章
- LeetCode-133克隆图(图的遍历+深拷贝概念)
克隆图 LeetCode-133 使用一个map来存储已经遍历的结点,这个存起来的结点必须是新new的才符合题意 /* // Definition for a Node. class Node { p ...
- [Java]LeetCode133. 克隆图 | Clone Graph
Clone an undirected graph. Each node in the graph contains a label and a list of its neighbors. OJ's ...
- Leetcode 133.克隆图
克隆图 克隆一张无向图,图中的每个节点包含一个 label (标签)和一个 neighbors (邻接点)列表 . OJ的无向图序列化: 节点被唯一标记. 我们用 # 作为每个节点的分隔符,用 , 作 ...
- LeetCode 133:克隆图 Clone Graph
题目: 给定无向连通图中一个节点的引用,返回该图的深拷贝(克隆).图中的每个节点都包含它的值 val(Int) 和其邻居的列表(list[Node]). Given a reference of a ...
- Leetcode之广度优先搜索(BFS)专题-133. 克隆图(Clone Graph)
Leetcode之广度优先搜索(BFS)专题-133. 克隆图(Clone Graph) BFS入门详解:Leetcode之广度优先搜索(BFS)专题-429. N叉树的层序遍历(N-ary Tree ...
- 【LeetCode】克隆图
[问题]给定无向连通图中一个节点的引用,返回该图的深拷贝(克隆).图中的每个节点都包含它的值 val(Int) 和其邻居的列表(list[Node]). 解释: 节点 的值是 ,它有两个邻居:节点 和 ...
- Java实现 LeetCode 133 克隆图
133. 克隆图 给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆). 图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node]). class Node { ...
- 【LeetCode】133. 克隆图
133. 克隆图 知识点:图:递归;BFS 题目描述 给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆). 图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[No ...
- 133克隆图 · Clone Graph
[抄题]: 克隆一张无向图,图中的每个节点包含一个 label 和一个列表 neighbors. [思维问题]: [一句话思路]: 先BFS克隆点(一个点+扩展所有邻居),再克隆邻居(一个点+扩展所有 ...
随机推荐
- 利用Gitee转接GitHub下载加速 简简单单 - 快快乐乐
利用Gitee转接GitHub下载加速 简简单单 - 快快乐乐 JERRY_Z. ~ 2020 / 10 / 26 转载请注明出处!️ 目录 利用Gitee转接GitHub下载加速 简简单单 - 快快 ...
- Camera2使用textureView支持
SurfaceView 绘制会有独立窗口, TextureView 没有独立的窗口,可以像普通的 View 一样,更高效更方便 public class MainActivity extends Ap ...
- B. Game of the Rows 解析(思維)
Codeforce 839 B. Game of the Rows 解析(思維) 今天我們來看看CF839B 題目連結 題目 有如下圖片所示的飛機座位\(n\)排,和\(k\)隊士兵,每隊數量不一定. ...
- Eureka整合sidecar异构调用
本次使用nodejs脚本生成的异构程序测试: node-server.js var http = require('http'); var url = require('url'); var path ...
- 上午小测1 B.序列 哈希表+数学
题目描述 \(EZ\) 每周一都要举行升旗仪式,国旗班会站成一整列整齐地向前行进. 郭神摄像师想要选取其中一段照下来.他想让这一段中每个人的身高成等比数列,展示出最萌身高差.但他发现这个太难办到了.于 ...
- C语言程序设计之 数组2020-10-28
C语言程序设计之 数组2020-10-28 整理: 第一题:求最小数与第一个数交换 [问题描述] 输入一个正整数n (1<n<=100),再输入n个整数,将最小值与第一个数交换,然后输 ...
- NB-IoT的同步信号解析
NB-IoT的小区搜索和LTE的小区搜索是类似的,每个UE都是通过对同步信号的检测,来实现与小区时间和频率上的同步,以此来获取小区的ID.NB-IoT的同步信号包括NPSS和NSSS. NPSS用于完 ...
- Vue3教程:一个基于 Vue 3 + Vant 3 的商城项目开源啦!
之前发布过一篇文章,告诉大家我要开发一个 Vue3 的商城项目并开源到 GitHub 上,供大家练手和学习,随后也一直有收到留言和反馈,问我开发到哪里了,什么时候开源之类的问题,今天终于可以通知大家, ...
- border-radius编程练习1-3
border-radius编程练习1-3 我们刚学了圆角的知识,那么我们运用圆角的知识来实现下图所要求的效果: 参考代码: <!DOCTYPE html> <html lang=&q ...
- MYSQL学习(二) --MYSQL框架
MYSQL架构理解 通过对MYSQL重要的几个属性的理解,建立一个基本的MYSQL的知识框架.后续再补充完善. 一.MYSQL架构 这里给的架构描述,是很宏观的架构.有助于建立对MYSQL整体理解. ...