sklearn决策树应用及可视化
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
1.载入iris数据集(from sklearn import datasets)
x = iris.data[:,[0,2]] # x = iris.data[:, 0:2]
y = iris.target
2.设置训练集中的数据和标签(x是特征集合,二维数组,y是标签值集合,一维数组)
clf = DecisionTreeClassifier(max_depth = 3)
clf.fit(x,y)
3.训练模型(DecisionTreeClassifier涉及到参数max_depth及其他,参考sklearn)
最后,是决策树的可视化,预备工作为:
scikit-learn中决策树的可视化一般需要安装graphviz。主要包括graphviz的安装和python的graphviz插件的安装。
第一步是安装graphviz。下载地址在:http://www.graphviz.org/。如果你是linux,可以用apt-get或者yum的方法安装。如果是windows,就在官网下载msi文件安装。无论是linux还是windows,装完后都要设置环境变量,将graphviz的bin目录加到PATH,比如我是windows,将C:/Program Files (x86)/Graphviz2.38/bin/加入了PATH
第二步是安装python插件graphviz: pip install graphviz
第三步是安装python插件pydotplus。这个没有什么好说的: pip install pydotplus
这样环境就搭好了,若仍然找不到graphviz,可以在代码里面加入这一行:
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
两种方法:
(1)生成pdf
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("iris.pdf")
(2)直接在jupyter中显示
from IPython.display import Image
from sklearn import tree
import pydotplus
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=["sepal length","sepal width"],
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
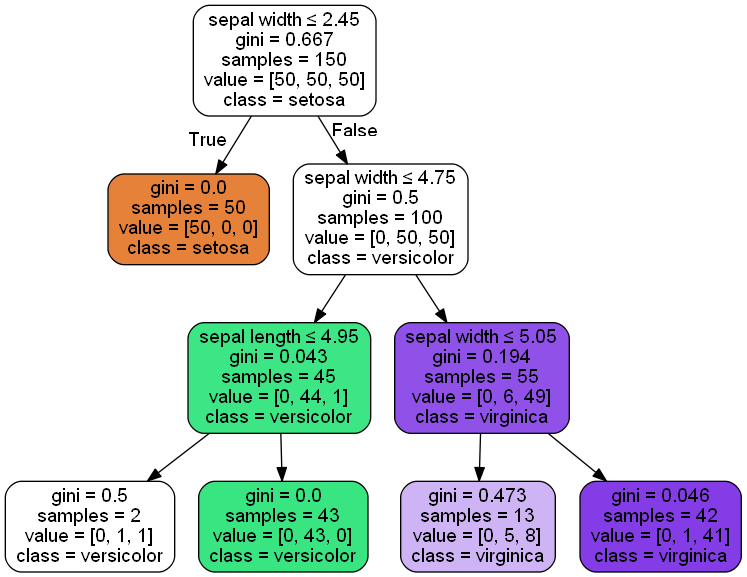
文章参考:https://www.cnblogs.com/pinard/p/6056319.html
sklearn决策树应用及可视化的更多相关文章
- 通俗地说决策树算法(三)sklearn决策树实战
前情提要 通俗地说决策树算法(一)基础概念介绍 通俗地说决策树算法(二)实例解析 上面两篇介绍了那么多决策树的知识,现在也是时候来实践一下了.Python有一个著名的机器学习框架,叫sklearn.我 ...
- sk-learn 决策树的超参数
一.参数criterion:特征选择标准,[entropy, gini].默认gini,即CART算法. splitter:特征划分标准,[best, random].best在特征的所有划分点中找出 ...
- sklearn中树模型可视化的方法
在机器学习的过程中,我们常常会用到树模型的方式来解决我们的问题.在工业界,我们不仅要针对某个问题利用机器学习的方法来解决问题,而且还需要能力解释其中的原理或原因.今天主要在这里记录一下树模型是怎么做可 ...
- 【sklearn入门】通过sklearn实现k-means并可视化聚类结果
import numpy as np from sklearn.cluster import KMeans from mpl_toolkits.mplot3d import Axes3D import ...
- Sklearn库例子——决策树分类
Sklearn上关于决策树算法使用的介绍:http://scikit-learn.org/stable/modules/tree.html 1.关于决策树:决策树是一个非参数的监督式学习方法,主要用于 ...
- 决策树decision tree原理介绍_python sklearn建模_乳腺癌细胞分类器(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 机器学习之使用sklearn构造决策树模型
一.任务基础 导入所需要的库 import matplotlib.pyplot as plt import pandas as pd %matplotlib inline 加载sklearn内置数据集 ...
- 决策树模型 ID3/C4.5/CART算法比较
决策树模型在监督学习中非常常见,可用于分类(二分类.多分类)和回归.虽然将多棵弱决策树的Bagging.Random Forest.Boosting等tree ensembel 模型更为常见,但是“完 ...
- 机器学习之决策树(ID3 、C4.5算法)
声明:本篇博文是学习<机器学习实战>一书的方式路程,系原创,若转载请标明来源. 1 决策树的基础概念 决策树分为分类树和回归树两种,分类树对离散变量做决策树 ,回归树对连续变量做决策树.决 ...
随机推荐
- 17flask分页
一,flask_sqlachemy的使用 如果想要展示出来的页面是分页显示,则首先需要知道每页应该分多少个条目,然后通过数据库去查找对应的条数,同时也需要和分页所需的"paginate&qu ...
- EMP-面向未来微前端方案正式开源了!
原文团队掘金平台:https://juejin.im/post/6891532248269783054 EMP项目github链接: https://github.com/efoxTeam/emp E ...
- 强迫自己学习Jquery三
元素定位问题 offset 和 position必须要好好看一下,
- MySQL视图详细介绍
前言: 在MySQL中,视图可能是我们最常用的数据库对象之一了.那么你知道视图和表的区别吗?你知道创建及使用视图要注意哪些点吗?可能很多人对视图只是一知半解,想详细了解视图的同学看过来哟,本篇文章会详 ...
- binary hacks读数笔记(nm命令)
nm命令(names):输出包含三个部分:1 符号值.默认显示十六进制,也可以指定: 2 符号类型.小写表示是本地符号,大写表示全局符号(external); 3 符号名称. 例如:nm Simple ...
- 机器学习3《数据集与k-近邻算法》
机器学习数据类型: ●离散型数据:由记录不同类别个体的数目所得到的数据,又称计数数据,所 有这些数据全部都是整数,而且不能再细分,也不能进一步提高他们的精确度. ●连续型数据:交量可以在某个范围内取任 ...
- SpringBoot整合Xxl-Job
一.下载Xxl-Job源代码并导入本地并运行 Github地址:https://github.com/xuxueli/xxl-job 中文文档地址:https://www.xuxueli.com/xx ...
- linux中的fork炸弹
学习bash脚本看到一段代码(老鸟应该知道)挺有意思,一时看不懂.该命令不需要管理员即可运行,请不要在你的机器上使用以下脚本,否则你知道你在干什么 :() { :|: & };: 参考链接:h ...
- 思维导图软件iMindMap的使用方法
从手绘的思维导图再到各种各样的思维导图的软件,思维导图的高效性大家都体会到了.思维导图软件iMindMap在众多导图软件中是最受欢迎的之一,下面就给大家分享一下思维导图怎么画: 首先我要教给大家的是如 ...
- SwiftUI:看我展示52张扑克牌,“很快啊!”
目录 思路 效果图 相关代码解析 枚举创建扑克牌号码 枚举创建扑克牌类型 viewModel逻辑 UI实现 源码 感受 思路 使用 SwiftUI 创建 UI 结构: 使用 swift 的枚举和结构体 ...