小师妹学JVM之:cache line对代码性能的影响
简介
读万卷书不如行万里路,讲了这么多assembly和JVM的原理与优化,今天我们来点不一样的实战。探索一下怎么使用assembly来理解我们之前不能理解的问题。
一个奇怪的现象
小师妹:F师兄,之前你讲了那么多JVM中JIT在编译中的性能优化,讲真的,在工作中我们真的需要知道这些东西吗?知道这些东西对我们的工作有什么好处吗?
um...这个问题问得好,知道了JIT的编译原理和优化方向,我们的确可以在写代码的时候稍微注意一下,写出性能更加优秀的代码,但是这只是微观上了。
如果将代码上升到企业级应用,一个硬件的提升,一个缓存的加入或者一种架构的改变都可能比小小的代码优化要有用得多。
就像是,如果我们的项目遇到了性能问题,我们第一反应是去找架构上面有没有什么缺陷,有没有什么优化点,很少或者说基本上不会去深入到代码层面,看你的这个代码到底有没有可优化空间。
第一,只要代码的业务逻辑不差,运行起来速度也不会太慢。
第二,代码的优化带来的收益实在太小了,而工作量又非常庞大。
所以说,对于这种类似于鸡肋的优化,真的有必要存在吗?
其实这和我学习物理化学数学知识是一样的,你学了那么多知识,其实在日常生活中真的用不到。但是为什么要学习呢?
我觉得有两个原因,第一是让你对这个世界有更加本质的认识,知道这个世界是怎么运行的。第二是锻炼自己的思维习惯,学会解决问题的方法。
就想算法,现在写个程序真的需要用到算法吗?不见得,但是算法真的很重要,因为它可以影响你的思维习惯。
所以,了解JVM的原理,甚至是Assembly的使用,并不是要你用他们来让你的代码优化的如何好,而是让你知道,哦,原来代码是这样工作的。在未来的某一个,或许我就可能用到。
好了,言归正传。今天给小师妹介绍一个很奇怪的例子:
private static int[] array = new int[64 * 1024 * 1024];
@Benchmark
public void test1() {
int length = array.length;
for (int i = 0; i < length; i=i+1)
array[i] ++;
}
@Benchmark
public void test2() {
int length = array.length;
for (int i = 0; i < length; i=i+2)
array[i] ++;
}
小师妹,上面的例子,你觉得哪一个运行的更快呢?
小师妹:当然是第二个啦,第二个每次加2,遍历的次数更少,肯定执行得更快。
好,我们先持保留意见。
第二个例子,上面我们是分别+1和+2,如果后面再继续+3,+4,一直加到128,你觉得运行时间是怎么样的呢?
小师妹:肯定是线性减少的。
好,两个问题问完了,接下来让我们来揭晓答案吧。
两个问题的答案
我们再次使用JMH来测试我们的代码。代码很长,这里就不列出来了,有兴趣的朋友可以到本文下面的代码链接下载运行代码。
我们直接上运行结果:
Benchmark Mode Cnt Score Error Units
CachelineUsage.test1 avgt 5 27.499 ± 4.538 ms/op
CachelineUsage.test2 avgt 5 31.062 ± 1.697 ms/op
CachelineUsage.test3 avgt 5 27.187 ± 1.530 ms/op
CachelineUsage.test4 avgt 5 25.719 ± 1.051 ms/op
CachelineUsage.test8 avgt 5 25.945 ± 1.053 ms/op
CachelineUsage.test16 avgt 5 28.804 ± 0.772 ms/op
CachelineUsage.test32 avgt 5 21.191 ± 6.582 ms/op
CachelineUsage.test64 avgt 5 13.554 ± 1.981 ms/op
CachelineUsage.test128 avgt 5 7.813 ± 0.302 ms/op
好吧,不够直观,我们用一个图表来表示:
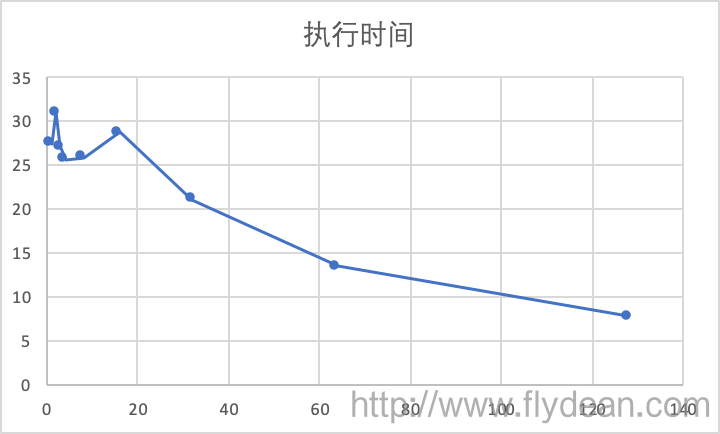
从图表可以看出,步长在1到16之间的时候,执行速度都还相对比较平稳,在25左右,然后就随着步长的增长而下降。
CPU cache line
那么我们先回答第二个问题的答案,执行时间是先平稳再下降的。
为什么会在16步长之内很平稳呢?
CPU的处理速度是有限的,为了提升CPU的处理速度,现代CPU都有一个叫做CPU缓存的东西。
而这个CPU缓存又可以分为L1缓存,L2缓存甚至L3缓存。
其中L1缓存是每个CPU核单独享有的。在L1缓存中,又有一个叫做Cache line的东西。为了提升处理速度,CPU每次处理都是读取一个Cache line大小的数据。
怎么查看这个Cache line的大小呢?
在mac上,我们可以执行:sysctl machdep.cpu
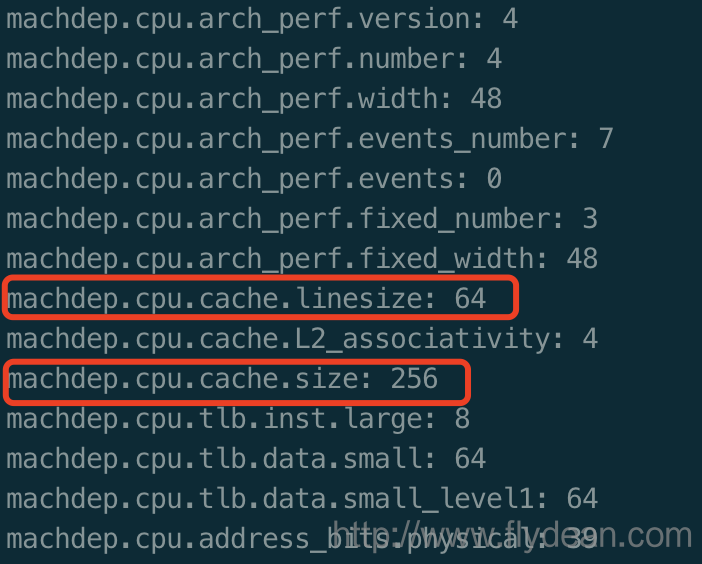
从图中我们可以得到,机子的CPU cache line是64byte,而cpu的一级缓存大小是256byte。
好了,现在回到为什么1-16步长执行速度差不多的问题。
我们知道一个int占用4bytes,那么16个int刚好占用64bytes。所以我们可以粗略的认为,1-16步长,每次CPU取出来的数据是一样的,都是一个cache line。所以,他们的执行速度其实是差不多的。
inc 和 add
小师妹:F师兄,上面的解释虽然有点完美了,但是好像还有一个漏洞。既然1-16使用的是同一个cache line,那么他们的执行时间,应该是逐步下降才对,为什么2比1执行时间还要长呢?
这真的是一个好问题,光看代码和cache line好像都解释不了,那么我们就从Assembly的角度再来看看。
还是使用JMH,打开PrintAssembly选项,我们看看输出结果。
先看下test1方法的输出:

再看下test2方法的输出:

两个有什么区别呢?
基本上的结构都是一样的,只不过test1使用的是inc,而test2方法使用的add。
本人对汇编语言不太熟,不过我猜两者执行时间的差异在于inc和add的差异,add可能会执行慢一点,因为它多了一个额外的参数。
总结
Assembly虽然没太大用处,但是在解释某些神秘现象的时候,还是挺好用的。
本文的例子https://github.com/ddean2009/learn-java-base-9-to-20
本文作者:flydean程序那些事
本文链接:http://www.flydean.com/jvm-jit-cacheline/
本文来源:flydean的博客
欢迎关注我的公众号:程序那些事,更多精彩等着您!
小师妹学JVM之:cache line对代码性能的影响的更多相关文章
- 小师妹学JVM之:JDK14中JVM的性能优化
目录 简介 String压缩 分层编译(Tiered Compilation) Code Cache分层 新的JIT编译器Graal 前置编译 压缩对象指针 Zero-Based 压缩指针 Escap ...
- 小师妹学JVM之:JIT中的PrintAssembly
目录 简介 使用PrintAssembly 输出过滤 总结 简介 想不想了解JVM最最底层的运行机制?想不想从本质上理解java代码的执行过程?想不想对你的代码进行进一步的优化和性能提升? 如果你的回 ...
- 小师妹学JVM之:JVM中的Safepoints
目录 简介 GC的垃圾回收器 分代回收器中的问题 safepoints safepoint一般用在什么地方 总结 简介 java程序员都听说过GC,大家也都知道GC的目的是扫描堆空间,然后将那些标记为 ...
- 小师妹学JVM之:JVM的架构和执行过程
目录 简介 JVM是一种标准 java程序的执行顺序 JVM的架构 类加载系统 运行时数据区域 执行引擎 总结 简介 JVM也叫Java Virtual Machine,它是java程序运行的基础,负 ...
- 小师妹学JVM之:GC的垃圾回收算法
目录 简介 对象的生命周期 垃圾回收算法 Mark and sweep Concurrent mark sweep (CMS) Serial garbage collection Parallel g ...
- 小师妹学JVM之:深入理解JIT和编译优化-你看不懂系列
目录 简介 JIT编译器 Tiered Compilation分层编译 OSR(On-Stack Replacement) Deoptimization 常见的编译优化举例 Inlining内联 Br ...
- 小师妹学JVM之:JIT中的LogCompilation
目录 简介 LogCompilation简介 LogCompilation的使用 解析LogCompilation文件 总结 简介 我们知道在JVM中为了加快编译速度,引入了JIT即时编译的功能.那么 ...
- 小师妹学JVM之:JIT中的PrintCompilation
目录 简介 PrintCompilation 分析PrintCompilation的结果 总结 简介 上篇文章我们讲到了JIT中的LogCompilation,将编译的日志都收集起来,存到日志文件里面 ...
- 小师妹学JVM之:java的字节码byte code简介
目录 简介 Byte Code的作用 查看Byte Code字节码 java Byte Code是怎么工作的 总结 简介 Byte Code也叫做字节码,是连接java源代码和JVM的桥梁,源代码编译 ...
随机推荐
- Spring事务的传播属性
前言 Spring在TransactionDefinition接口中规定了7种类型的事务传播行为.事务传播行为是Spring框架独有的事务增强特性,他不属于的事务实际提供方数据库行为.这是Spring ...
- JVM性能优化 (一) 初识JVM
一.我们为什么要对JVM做优化 在本地开发环境中我们很少会遇到需要对JVM进行优化的需求,但是到了生产环境,我们可能会有下面的需求: 运行的应用"卡住了",日志不输出,程序没有反应 ...
- 深度学习在高德ETA应用的探索与实践
1.导读 驾车导航是数字地图的核心用户场景,用户在进行导航规划时,高德地图会提供给用户3条路线选择,由用户根据自身情况来决定按照哪条路线行驶. 同时各路线的ETA(estimated time of ...
- RocketMQ系列(四)顺序消费
折腾了好长时间才写这篇文章,顺序消费,看上去挺好理解的,就是消费的时候按照队列中的顺序一个一个消费:而并发消费,则是消费者同时从队列中取消息,同时消费,没有先后顺序.RocketMQ也有这两种方式的实 ...
- Python--循环--for && while
for循环示例:猜数字游戏 winning_number = 38 for i in range(3): guess_num = int(input("guess num:") ) ...
- protobuf安装流程
protobuf安装流程 环境 平台 Ubuntu16.04 依赖 autoconf automake libtool curl make g++ 安装流程 在Ubuntu / Debian上,您 ...
- Spring AOP—注解配置方法的使用
Spring除了支持Schema方式配置AOP,还支持注解方式:使用@AspectJ风格的切面声明. 1 启用对@AspectJ的支持 Spring默认不支持@AspectJ风格的切面声明,为了支持需 ...
- 使用Docker搭建Nextcloud SSL站点
1.启动mariadb docker run -d \ --name mysql \ -e MYSQL_ROOT_PASSWORD=<你的mysql密码> \ -p 13306:3306 ...
- GoldenDict和AutoHotKey的安装和使用
GoldenDict 下载地址:http://sourceforge.net/projects/goldendict/files/early%20access%20builds/ 官网提供的版本很老, ...
- @loj - 2987@ 「CTSC2016」时空旅行
目录 @description@ @solution@ @accepted code@ @details@ @description@ 2045 年,人类的技术突飞猛进,已经找到了进行时空旅行的方法. ...